标签:ocs 美食 电影 没有 数据 现在 因此 tf-idf ast
作者|GUEST
编译|VK
来源|Analytics Vidhya
我们生活在数字技术的时代。你上次走进一家没有数字交易的商店是什么时候?
这些数字交易技术已经迅速成为我们日常生活的一个关键部分。
不仅仅是在个人层面,这些数字技术是每个金融机构的核心。通过多种可能的选择(如网上银行、ATM、信用卡或借记卡、UPI、POS机等),在后台运行可靠的系统,支付交易或资金转账已经变得非常顺利。
我们会为每个事务生成一个适当的描述:
在本文中,我们将使用聚类(一种流行的机器学习算法)讨论一个金融机构为其客户群定制产品的真实用例。
作为一家金融机构,根据现有客户的不同兴趣,为他们提供定制化的服务,这一点总是很重要的。对于任何金融机构来说,捕捉客户的意图是一个重大挑战。
Twitter、WhatsApp、Facebook等社交媒体平台已成为分析客户兴趣和偏好的主要信息来源。
金融机构从第三方获取数据往往会产生巨大的成本。即便如此,将一个社交媒体帐户映射到一个独特的客户也变得非常困难。
那么我们如何解决这个问题呢?

上述问题的部分解决方案可以通过使用机构提供的内部交易数据来解决。
我们可以根据事务描述消息将客户执行的事务分为不同的类别。
此方法可用于标记交易是否针对食品、运动、服装、账单付款、家居等进行。如果客户的大部分交易都出现在特定类别中,则我们可以更好地估计他/她的偏好。
让我们了解一下我们是如何处理这个问题陈述的,以及我们为找出解决方案而采取的关键步骤。
我们从所有事务开始处理,并将它们的描述消息映射到每个客户。首先,我们有一项重要的任务,即确定簇(或)类别(或)主题的数量。为了达到这个目标,我们使用主题模型。
主题模型是一种对文档进行无监督分类的方法,它可以在我们不确定要查找的内容时找到自然的项目组。它主要使用潜在Dirichlet分配(LDA)来拟合主题模型。
它将每个文档(即事务)视为主题的混合,而每个主题则是单词的混合。
举个例子:预算这个词可能会出现在电影和政治中。这种LDA的基本假设是,样本中的每一个观察结果都来自一个任意未知的分布,可以用生成统计模型来解释。
让我们来看看这个方法来解决我们的问题。
在事务描述中,存在生成统计模型,生成交易描述中来自未知分布(即未知组或主题)的所有单词。我们试图建立一个统计模型,以便它预测一个词属于某个特定主题的概率。

通过手动查看各个主题的关键词来确定主题的总数。
但是这导致每个人的观点不一致,我们需要一个方法来评估正确的主题数量。我们使用主题连贯性的度量来确定正确的主题数量。
主题连贯性应用于主题的前N个单词。它被定义为主题词的成对词相似度得分的平均值/中位数。一个好的模型将产生连贯的主题,即主题连贯性得分高的主题。
好的主题是可以用一个简短的标签来描述的主题;因此,这就是主题一致性度量所捕获的内容。
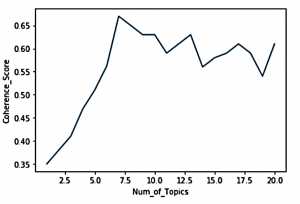
接着我们可以确定主题/簇的总数(在我们的例子中是7个主题)。我们应该开始将每个事务描述消息分配到主题中。在为主题分配文档时,单靠主题模型可能无法产生准确的结果。
在这里,我们使用主题模型的输出以及其他一些特性,使用K-Means集群对事务描述消息进行聚类。在这里,我们将集中精力为K-Means聚类构建一个特征集。
每个事务描述都有大约30个特征,我们执行K-Means聚类将每个事务描述分配给7个集群中的一个。
结果表明,靠近簇中心的观测值大多标注了正确的主题。很少有远离簇中心的观测被赋予错误的主题标签。
在手工检查的350个事务描述中,大约240个(准确率约69%)事务描述被正确地标记为适当的主题。
现在我们至少对内部客户的偏好和兴趣有了一个基本的估计。我们可以发送定制的报价和选项,以保持他们的参与和改善业务。
虽然使用主题模型的方法相对新颖,但使用交易对客户进行分类的方法主要是由信用卡发卡机构使用的。
例如,美国运通一直在使用这种方法为客户创建兴趣图。这种兴趣图不仅将交易分为食物、旅游等主要群体,而且还创建了泰国美食爱好者、野生动物爱好者等微观细分市场,所有这些都仅仅来自于丰富的交易数据!
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
标签:ocs 美食 电影 没有 数据 现在 因此 tf-idf ast
原文地址:https://www.cnblogs.com/panchuangai/p/13339439.html