标签:path oop 比较 机制 except put mamicode play sum

(6)自定义Combiner实现步骤
(a)自定义一个Combiner继承Reducer,重写Reduce方法
public class WordcountCombiner extends Reducer<Text, IntWritable, Text,IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { // 1 汇总操作 int count = 0; for(IntWritable v :values){ count += v.get(); } // 2 写出 context.write(key, new IntWritable(count)); } }
(b)在Job驱动类中设置:
job.setCombinerClass(WordcountCombiner.class);
1.需求
统计过程中对每一个MapTask的输出进行局部汇总,以减小网络传输量即采用Combiner功能。
(1)数据输入

(2)期望输出数据
期望:Combine输入数据多,输出时经过合并,输出数据降低。
2.需求分析

图4-15 Combiner的合并案例
3.案例实操-方案一
1)增加一个WordcountCombiner类继承Reducer

package com.atguigu.mr.combiner; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class WordcountCombiner extends Reducer<Text, IntWritable, Text, IntWritable>{ IntWritable v = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { // 1 汇总 int sum = 0; for(IntWritable value :values){ sum += value.get(); } v.set(sum); // 2 写出 context.write(key, v); } }
2)在WordcountDriver驱动类中指定Combiner
// 指定需要使用combiner,以及用哪个类作为combiner的逻辑 job.setCombinerClass(WordcountCombiner.class);
4.案例实操-方案二
1)将WordcountReducer作为Combiner在WordcountDriver驱动类中指定
// 指定需要使用Combiner,以及用哪个类作为Combiner的逻辑 job.setCombinerClass(WordcountReducer.class);
运行程序,如图4-16,4-17所示
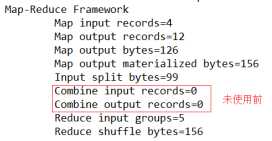
图4-16 未使用前

图4-17 使用后
对Reduce阶段的数据根据某一个或几个字段进行分组。
分组排序步骤:
(1)自定义类继承WritableComparator
(2)重写compare()方法
@Override public int compare(WritableComparable a, WritableComparable b) { // 比较的业务逻辑 return result; }
(3)创建一个构造将比较对象的类传给父类
protected OrderGroupingComparator() { super(OrderBean.class, true); }
1.需求
有如下订单数据
表4-2 订单数据
|
订单id |
商品id |
成交金额 |
|
0000001 |
Pdt_01 |
222.8 |
|
Pdt_02 |
33.8 |
|
|
0000002 |
Pdt_03 |
522.8 |
|
Pdt_04 |
122.4 |
|
|
Pdt_05 |
722.4 |
|
|
0000003 |
Pdt_06 |
232.8 |
|
Pdt_02 |
33.8 |
现在需要求出每一个订单中最贵的商品。
(1)输入数据

(2)期望输出数据
1 222.8
2 722.4
3 232.8
2.需求分析
(1)利用“订单id和成交金额”作为key,可以将Map阶段读取到的所有订单数据按照id升序排序,如果id相同再按照金额降序排序,发送到Reduce。
(2)在Reduce端利用groupingComparator将订单id相同的kv聚合成组,然后取第一个即是该订单中最贵商品,如图4-18所示。
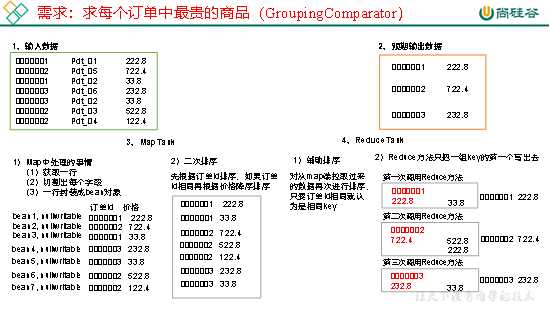
图4-18 过程分析
3.代码实现
(1)定义订单信息OrderBean类
package com.atguigu.mapreduce.order; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.WritableComparable; public class OrderBean implements WritableComparable<OrderBean> { private int order_id; // 订单id号 private double price; // 价格 public OrderBean() { super(); } public OrderBean(int order_id, double price) { super(); this.order_id = order_id; this.price = price; } @Override public void write(DataOutput out) throws IOException { out.writeInt(order_id); out.writeDouble(price); } @Override public void readFields(DataInput in) throws IOException { order_id = in.readInt(); price = in.readDouble(); } @Override public String toString() { return order_id + "\t" + price; } public int getOrder_id() { return order_id; } public void setOrder_id(int order_id) { this.order_id = order_id; } public double getPrice() { return price; } public void setPrice(double price) { this.price = price; } // 二次排序 @Override public int compareTo(OrderBean o) { int result; if (order_id > o.getOrder_id()) { result = 1; } else if (order_id < o.getOrder_id()) { result = -1; } else { // 价格倒序排序 result = price > o.getPrice() ? -1 : 1; } return result; } }
(2)编写OrderSortMapper类
package com.atguigu.mapreduce.order; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class OrderMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable> { OrderBean k = new OrderBean(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1 获取一行 String line = value.toString(); // 2 截取 String[] fields = line.split("\t"); // 3 封装对象 k.setOrder_id(Integer.parseInt(fields[0])); k.setPrice(Double.parseDouble(fields[2])); // 4 写出 context.write(k, NullWritable.get()); } }
(3)编写OrderSortGroupingComparator类
package com.atguigu.mapreduce.order; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; public class OrderGroupingComparator extends WritableComparator { protected OrderGroupingComparator() { super(OrderBean.class, true); } @Override public int compare(WritableComparable a, WritableComparable b) { OrderBean aBean = (OrderBean) a; OrderBean bBean = (OrderBean) b; int result; if (aBean.getOrder_id() > bBean.getOrder_id()) { result = 1; } else if (aBean.getOrder_id() < bBean.getOrder_id()) { result = -1; } else { result = 0; } return result; } }
(4)编写OrderSortReducer类
package com.atguigu.mapreduce.order; import java.io.IOException; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Reducer; public class OrderReducer extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable> { @Override protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { context.write(key, NullWritable.get()); } }
(5)编写OrderSortDriver类
package com.atguigu.mapreduce.order; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class OrderDriver { public static void main(String[] args) throws Exception, IOException { // 输入输出路径需要根据自己电脑上实际的输入输出路径设置 args = new String[]{"e:/input/inputorder" , "e:/output1"}; // 1 获取配置信息 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 2 设置jar包加载路径 job.setJarByClass(OrderDriver.class); // 3 加载map/reduce类 job.setMapperClass(OrderMapper.class); job.setReducerClass(OrderReducer.class); // 4 设置map输出数据key和value类型 job.setMapOutputKeyClass(OrderBean.class); job.setMapOutputValueClass(NullWritable.class); // 5 设置最终输出数据的key和value类型 job.setOutputKeyClass(OrderBean.class); job.setOutputValueClass(NullWritable.class); // 6 设置输入数据和输出数据路径 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 8 设置reduce端的分组 job.setGroupingComparatorClass(OrderGroupingComparator.class); // 7 提交 boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }
标签:path oop 比较 机制 except put mamicode play sum
原文地址:https://www.cnblogs.com/qiu-hua/p/13340985.html
