标签:http span lazy form index 数据表 ram col info
1,series.values, seires.index.tolist(), series.items()
values、index、items返回的对象分别是List、Index、Zip类型的数据
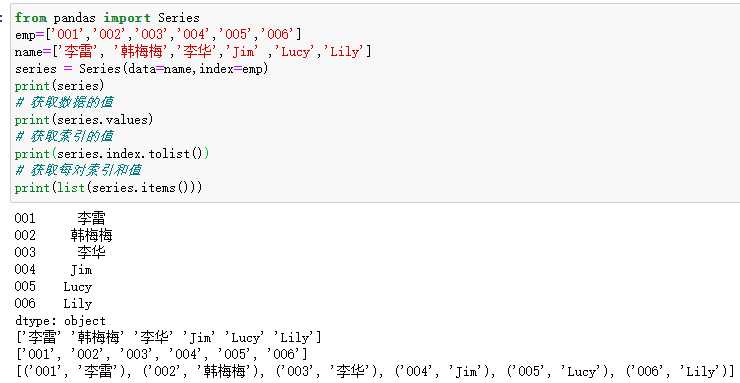
from pandas import Series
emp=[‘001‘,‘002‘,‘003‘,‘004‘,‘005‘,‘006‘]
name=[‘李雷‘, ‘韩梅梅‘,‘李华‘,‘Jim‘ ,‘Lucy‘,‘Lily‘]
series = Series(data=name,index=emp)
print(series)
# 获取数据的值
print(series.values)
# 获取索引的值
print(series.index.tolist())
# 获取每对索引和值
print(list(series.items()))
2, 对Series访问可以用series[‘index‘] 索引下标,或者series[N]位置下标。
当需要索取的值多于一个时,用两层中括号 [[]]
from pandas import Series
emp=[‘001‘,‘002‘,‘003‘,‘004‘,‘005‘,‘006‘]
name=[‘李雷‘, ‘韩梅梅‘,‘李华‘,‘Jim‘ ,‘Lucy‘,‘Lily‘]
series = Series(data=name,index=emp)
print(series.values)
print(series.index.tolist())
print(list(series.items()))
print("{0:=^30}".format(‘下面是是用索引下标‘))
print(series[‘001‘])
print(series[‘001‘:‘003‘])
print(series[[‘001‘,‘004‘,‘006‘]],)
print("{0:=^30}".format(‘下面是是用位置下标‘))
print(series[0])
print(series[0:3])
print(series[[0,3,5]])

3, series的遍历
通过series.keys(), 获取series的索引数据;
通过series.items(),获取series的索引和值,返回元组形式;
直接对series遍历可以获得值。
from pandas import Series
empid=[‘001‘,‘002‘,‘003‘,‘004‘,]
name=[‘李雷‘, ‘韩梅梅‘,‘Jim‘ ,‘Lucy‘,]
series = Series(data=name,index=empid)
for value in series:
print(value)
print("{:=^20}".format("分隔线"))
for value in series.keys():
print(value)
print("{:=^20}".format("分隔线"))
for value in series.items():
print(value)

==============分隔符==============
4,对于DataFrame数据表,可以通过ndim查看维度,
shape检查数据行列数,index获取数据行索引;
columns获取列索引。
通过索引切片获取数据行列数据,通过
df.head()和df.tail()获取前几行或后几行的数据。
from pandas import Series, DataFrame
df_dict = {
‘name‘:[‘李雷‘, ‘韩梅梅‘,‘李华‘,‘Jim‘ ,‘Lucy‘,‘Lily‘],
‘age‘:[‘18‘,‘20‘,‘19‘,‘22‘,‘23‘,‘24‘],
‘weight‘:[‘50‘,‘55‘,‘60‘,‘80‘,‘75‘,‘59‘]
}
df = DataFrame(data = df_dict, index = ["01","02","03","04","05","06",])
# 获取行数和列数
print(df.shape)
# 获取行索引
print(df.index.tolist())
# 获取列索引
print(df.columns.tolist())
# 获取数据的维度
print(df.ndim)
# 通过位置索引切片获取一行
print(df[0:1])
print("{0:=^20}".format("分隔线"))
# 通过位置索引切片获取多行
print(df[1:3])
print("{0:=^20}".format("分隔线"))
# 获取多行里面的某几列
print(df[1:3][[‘name‘,‘age‘]])
print("{0:=^20}".format("分隔线"))
# 获取DataFrame的列
print(df[‘name‘])
print("{0:=^20}".format("分隔线"))
# 如果获取多个列
print(df[[‘name‘,‘age‘]])
print("{0:=^20}".format("分隔线"))
print(df.head(2))
print("{0:=^20}".format("分隔线"))
print(df.tail(2))

4.2 通过行标签索引筛选loc[]或者位置索引筛选iloc[]来获取数据。
from pandas import Series, DataFrame
df_dict = {
‘name‘:[‘李雷‘, ‘韩梅梅‘,‘李华‘,‘Jim‘ ,‘Lucy‘,‘Lily‘],
‘age‘:[‘18‘,‘20‘,‘19‘,‘22‘,‘23‘,‘24‘],
‘weight‘:[‘50‘,‘55‘,‘60‘,‘80‘,‘75‘,‘59‘]
}
df = DataFrame(data = df_dict, index = ["01","02","03","04","05","06",])
# 1,获取某一行某一列的数据
print(df.loc[‘01‘,‘name‘])
print("{0:*^20}".format("分隔线"))
# 2,某一行多列的数据
print(df.loc[‘01‘,[‘name‘,‘weight‘]])
# 3,一行所有列
print("{0:*^20}".format("分隔线"))
print(df.loc[‘01‘,:])
# 4,选择间隔的多行多列
print("{0:*^20}".format("分隔线"))
print(df.loc[[‘01‘,‘03‘],[‘name‘,‘weight‘]])
# 5,选择连续的多行和间隔的多列
print("{0:*^20}".format("分隔线"))
print(df.loc[‘01‘:‘03‘,‘name‘:‘weight‘])

df.loc[] 通过标签索引获取行数据,它的语法结构是这样的:
df.loc[[行],[列]],方括号中用逗号分隔,左侧是行、右侧是列。
千万注意:如果行或者列使用切片的时候,要把方括号去掉,
列df.loc[‘001‘:‘003‘,‘name‘:‘weight‘]。
df.iloc[] 通过位置索引获取行数据,
操作和loc[]操作是一样的,只要将标签索引改成位置索引即可。
from pandas import Series, DataFrame
df_dict = {
‘name‘:[‘李雷‘, ‘韩梅梅‘,‘李华‘,‘Jim‘ ,‘Lucy‘,‘Lily‘],
‘age‘:[‘18‘,‘20‘,‘19‘,‘22‘,‘23‘,‘24‘],
‘weight‘:[‘50‘,‘55‘,‘60‘,‘80‘,‘75‘,‘59‘]
}
df = DataFrame(data = df_dict, index = ["01","02","03","04","05","06",])
print(df)
print("{0:*^20}".format("分隔线"))
# 取一行
print(df.iloc[1])
print("{0:*^20}".format("分隔线"))
# 取连续多行
print(df.iloc[0:2])
# 取间断的多行
print("{0:*^20}".format("分隔线"))
print(df.iloc[[0,2],:])
# 取某一列
print("{0:*^20}".format("分隔线"))
print(df.iloc[:,1])
print("{0:*^20}".format("分隔线"))
# 某一个值
print(df.iloc[1,0])

需要注意的是,loc和iloc的切片操作在是否包含切片终点的数据有差异。
loc[‘001‘:‘003‘]的结果中包含行索引003对应的行。
iloc[0:2] 结果中不包含序号为2的数据,切片终点对应的数据不在筛选结果中。
4.3) DataFrame的遍历
iterrows(): 按行遍历,将DataFrame的每一行转化为(index, Series)对。
index为行索引值,Series为该行对应的数据。
from pandas import Series, DataFrame
df_dict = {
‘name‘:[‘李雷‘, ‘韩梅梅‘,‘李华‘,‘Jim‘ ,‘Lucy‘,‘Lily‘],
‘age‘:[‘18‘,‘20‘,‘19‘,‘22‘,‘23‘,‘24‘],
‘weight‘:[‘50‘,‘55‘,‘60‘,‘80‘,‘75‘,‘59‘]
}
df = DataFrame(data = df_dict, index = ["01","02","03","04","05","06",])
print(df)
print("{0:*^20}".format("分隔线"))
for index,row_data in df.iterrows():
print(index,row_data)
print()

iteritems():按列遍历,将DataFrame的每一列转化为(column, Series)对。
column为列索引的值,Series为该列对应的数据。
from pandas import Series, DataFrame
df_dict = {
‘name‘:[‘李雷‘, ‘韩梅梅‘,‘李华‘,‘Jim‘ ,‘Lucy‘,‘Lily‘],
‘age‘:[‘18‘,‘20‘,‘19‘,‘22‘,‘23‘,‘24‘],
‘weight‘:[‘50‘,‘55‘,‘60‘,‘80‘,‘75‘,‘59‘]
}
df = DataFrame(data = df_dict, index = ["01","02","03","04","05","06",])
print(df)
print("{0:*^20}".format("分隔线"))
for col,col_data in df.iteritems():
print(col,col_data)
print()

标签:http span lazy form index 数据表 ram col info
原文地址:https://www.cnblogs.com/yinziming/p/13340162.html