标签:服务 收录 shu 很多 super 分布 自己的 点列 封装
本文已收录GitHub,更有互联网大厂面试真题,面试攻略,高效学习资料等
首先,我先带你认识一下什么是锁。
在单机多线程环境中,我们经常遇到多个线程访问同一个共享资源(这里需要注意的是:在很多地方,这种资源会称为临界资源,但在今天这篇文章中,我们统一称之为共享资源)的情况。为了维护数据的一致性,我们需要某种机制来保证只有满足某个条件的线程才能访问资源,不满足条件的线程只能等待,在下一轮竞争中重新满足条件时才能访问资源。
这个机制指的是,为了实现分布式互斥,在某个地方做个标记,这个标记每个线程都能看到,到标记不存在时可以设置该标记,当标记被设置后,其他线程只能等待拥有该标记的线程执行完成,并释放该标记后,才能去设置该标记和访问共享资源。这里的标记,就是我们常说的锁。
也就是说,锁是实现多线程同时访问同一共享资源,保证同一时刻只有一个线程可访问共享资源所做的一种标记。
与普通锁不同的是,分布式锁是指分布式环境下,系统部署在多个机器中,实现多进程分布式互斥的一种锁。为了保证多个进程能看到锁,锁被存在公共存储(比如 Redis、Memcache、数据库等三方存储中),以实现多个进程并发访问同一个临界资源,同一时刻只有一个进程可访问共享资源,确保数据的一致性。
那什么场景下需要使用分布式锁呢?
比如,现在某电商要售卖某大牌吹风机(以下简称“吹风机”),库存只有 2 个,但有 5个来自不同地区的用户{A,B,C,D,E}几乎同时下单,那么这 2 个吹风机到底会花落谁家呢?
你可能会想,这还不简单,谁先提交订单请求,谁就购买成功呗。但实际业务中,为了高并发地接受大量用户订单请求,很少有电商网站真正实施这么简单的措施。
此外,对于订单的优先级,不同电商往往采取不同的策略,比如有些电商根据下单时间判断谁可以购买成功,而有些电商则是根据付款时间来判断。但,无论采用什么样的规则去判断谁能购买成功,都必须要保证吹风机售出时,数据库中更新的库存是正确的。为了便于理解,我在下面的讲述中,以下单时间作为购买成功的判断依据。
我们能想到的最简单方案就是,给吹风机的库存数加一个锁。当有一个用户提交订单后,后台服务器给库存数加一个锁,根据该用户的订单修改库存。而其他用户必须等到锁释放以后,才能重新获取库存数,继续购买。
在这里,吹风机的库存就是共享资源,不同的购买者对应着多个进程,后台服务器对共享资源加的锁就是告诉其他进程“关键重地,非请勿入”。
但问题就这样解决了吗?当然没这么简单。
想象一下,用户 A 想买 1 个吹风机,用户 B 想买 2 个吹风机。在理想状态下,用户 A 网速好先买走了 1 个,库存还剩下 1 个,此时应该提示用户 B 库存不足,用户 B 购买失败。但实际情况是,用户 A 和用户 B 同时获取到商品库存还剩 2 个,用户 A 买走 1 个,在用户 A 更新库存之前,用户 B 又买走了 2 个,此时用户 B 更新库存,商品还剩 0 个。这时,电商就头大了,总共 2 个吹风机,却卖出去了 3 个。
不难看出,如果只使用单机锁将会出现不可预知的后果。因此,在高并发场景下,为了保证临界资源同一时间只能被一个进程使用,从而确保数据的一致性,我们就需要引入分布式锁了。
此外,在大规模分布式系统中,单个机器的线程锁无法管控多个机器对同一资源的访问,这时使用分布式锁,就可以把整个集群当作一个应用一样去处理,实用性和扩展性更好。
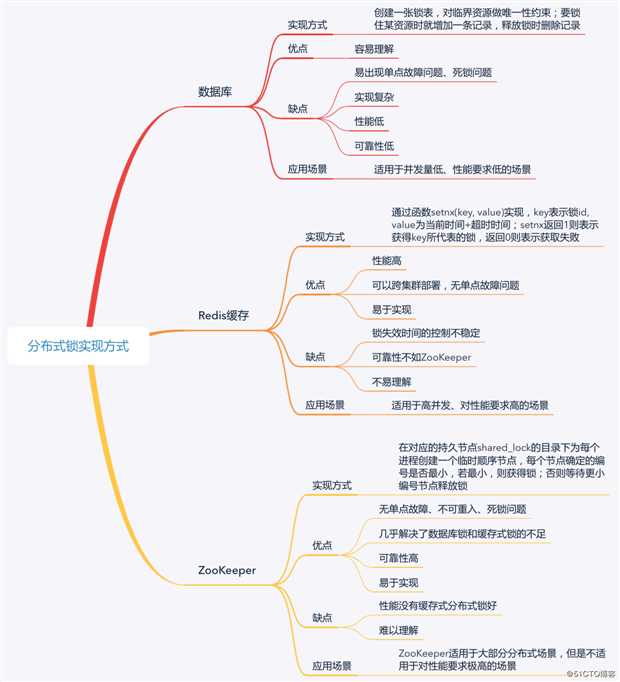
接下来,我带你看看实现分布式锁的 3 种主流方法,即:
要实现分布式锁,最简单的方式就是创建一张锁表,然后通过操作该表中的数据来实现。
当我们要锁住某个资源时,就在该表中增加一条记录,想要释放锁的时候就删除这条记录。数据库对共享资源做了唯一性约束,如果有多个请求被同时提交到数据库的话,数据库会保证只有一个操作可以成功,操作成功的那个线程就获得了访问共享资源的锁,可以进行操作。
基于数据库实现的分布式锁,是最容易理解的。但是,因为数据库需要落到硬盘上,频繁读取数据库会导致 IO 开销大,因此这种分布式锁适用于并发量低,对性能要求低的场景。对于双 11、双 12 等需求量激增的场景,数据库锁是无法满足其性能要求的。而在平日的购物中,我们可以在局部场景中使用数据库锁实现对资源的互斥访问。
下面,我们还是以电商售卖吹风机的场景为例。吹风机库存是 2 个,有 5 个来自不同地区的用户{A,B,C,D,E}想要购买,其中用户 A 想买 1 个,用户 B 想买 2 个,用户 C 想买 1个。
用户 A 和用户 B 几乎同时下单,但用户 A 的下单请求最先到达服务器。因此,该商家的产品数据库中增加了一条关于用户 A 的记录,用户 A 获得了锁,他的订单请求被处理,服务器修改吹风机库存数,减去 1 后还剩下 1 个。
当用户 A 的订单请求处理完成后,有关用户 A 的记录被删除,服务器开始处理用户 B 的订单请求。这时,库存只有 1 个了,无法满足用户 B 的订单需求,因此用户 B 购买失败。
从数据库中,删除用户 B 的记录,服务器开始处理用户 C 的订单请求,库存中 1 个吹风机满足用户 C 的订单需求。所以,数据库中增加了一条关于用户 C 的记录,用户 C 获得了锁,他的订单请求被处理,服务器修改吹风机数量,减去 1 后还剩下 0 个。

可以看出,基于数据库实现分布式锁比较简单,绝招在于创建一张锁表,为申请者在锁表里建立一条记录,记录建立成功则获得锁,消除记录则释放锁。该方法依赖于数据库,主要有两个缺点:
数据库的性能限制了业务的并发量,那么对于双 11、双 12 等需求量激增的场景是否有解决方法呢?
基于缓存实现分布式锁的方式,非常适合解决这种场景下的问题。所谓基于缓存,也就是说把数据存放在计算机内存中,不需要写入磁盘,减少了 IO 读写。接下来,我以 Redis 为例与你展开这部分内容。
Redis 通常可以使用 setnx(key, value) 函数来实现分布式锁。key 和 value 就是基于缓存的分布式锁的两个属性,其中 key 表示锁 id,value = currentTime + timeOut,表示当前时间 + 超时时间。也就是说,某个进程获得 key 这把锁后,如果在 value 的时间内未释放锁,系统就会主动释放锁。
setnx 函数的返回值有 0 和 1:
我还是以电商售卖吹风机的场景为例,和你说明基于缓存实现的分布式锁,假设现在库存数量是足够的。
用户 A 的请求因为网速快,最先到达 Server2,setnx 操作返回 1,并获取到购买吹风机的锁;用户 B 和用户 C 的请求,几乎同时到达了 Server1 和 Server3,但因为这时 Server2获取到了吹风机数据的锁,所以只能加入等待队列。
Server2 获取到锁后,负责管理吹风机的服务器执行业务逻辑,只用了 1s 就完成了订单。订单请求完成后,删除锁的 key,从而释放锁。此时,排在第二顺位的 Server1 获得了锁,可以访问吹风机的数据资源。但不巧的是,Server1 在完成订单后发生了故障,无法主动释放锁。
于是,排在第三顺位的 Server3 只能等设定的有效时间(比如 30 分钟)到期,锁自动释放后,才能访问吹风机的数据资源,也就是说用户 C 只能到 00:30:01 以后才能继续抢购。

总结来说,Redis 通过队列来维持进程访问共享资源的先后顺序。Redis 锁主要基于 setnx函数实现分布式锁,当进程通过 setnx<key,value> 函数返回 1 时,表示已经获得锁。排在后面的进程只能等待前面的进程主动释放锁,或者等到时间超时才能获得锁。
相对于基于数据库实现分布式锁的方案来说,基于缓存实现的分布式锁的优势表现在以下几个方面:
这个方案的不足是,通过超时时间来控制锁的失效时间,并不是十分靠谱,因为一个进程执行时间可能比较长,或受系统进程做内存回收等影响,导致时间超时,从而不正确地释放了锁。
为了解决基于缓存实现的分布式锁的这些问题,我们再来看看基于 ZooKeeper 实现的分布式锁吧。
ZooKeeper 基于树形数据存储结构实现分布式锁,来解决多个进程同时访问同一临界资源时,数据的一致性问题。ZooKeeper 的树形数据存储结构主要由 4 种节点构成:
根据它们的特征,ZooKeeper 基于临时顺序节点实现了分布锁。
还是以电商售卖吹风机的场景为例。假设用户 A、B、C 同时在 11 月 11 日的零点整提交了购买吹风机的请求,ZooKeeper 会采用如下方法来实现分布式锁:
例如,用户 B 也想要买吹风机,但在他之前,用户 C 想看看吹风机的库存量。因此,用户B 只能等用户 A 买完吹风机、用户 C 查询完库存量后,才能购买吹风机。

可以看到,使用 ZooKeeper 可以完美解决设计分布式锁时遇到的各种问题,比如单点故障、不可重入、死锁等问题。虽然 ZooKeeper 实现的分布式锁,几乎能涵盖所有分布式锁的特性,且易于实现,但需要频繁地添加和删除节点,所以性能不如基于缓存实现的分布式锁。
我通过一张表格来对比一下这三种方式的特点,以方便你理解、记忆。

总结来说,ZooKeeper 分布式锁的可靠性最高,有封装好的框架,很容易实现分布式锁的功能,并且几乎解决了数据库锁和缓存式锁的不足,因此是实现分布式锁的首选方法。
从上述分析可看出,为了确保分布式锁的可用性,我们在设计时应考虑到以下几点:
互斥性,即在分布式系统环境下,分布式锁应该能保证一个资源或一个方法在同一时间只
能被一个机器的一个线程或进程操作。
具备锁失效机制,防止死锁。即使有一个进程在持有锁的期间因为崩溃而没有主动解锁,
也能保证后续其他进程可以获得锁。
可重入性,即进程未释放锁时,可以多次访问临界资源。
有高可用的获取锁和释放锁的功能,且性能要好。
本文以电商购物为例,首先带你剖析了什么是分布式锁,以及为什么需要分布式锁;然后,与你介绍了三种实现分布式锁的方法,包括基于数据库实现、基于缓存实现(以 Redis 为例),以及基于 ZooKeeper 实现。
分布式锁是解决多个进程同时访问临界资源的常用方法,在分布式系统中非常常见,比如开源的 ZooKeeper、Redis 中就有所涉及。通过今天这篇文章对分布式锁原理及方法的讲解,我相信你会发现分布式锁不再那么神秘、难懂,然后以此为基础对分布式锁进行更深入的学习和应用。
接下来,我把今天的内容通过下面的一张思维导图再全面总结下。
为什么现在BAT面试必问分布式?阿里大牛带你实战剖析分布式锁
标签:服务 收录 shu 很多 super 分布 自己的 点列 封装
原文地址:https://blog.51cto.com/14799494/2512034