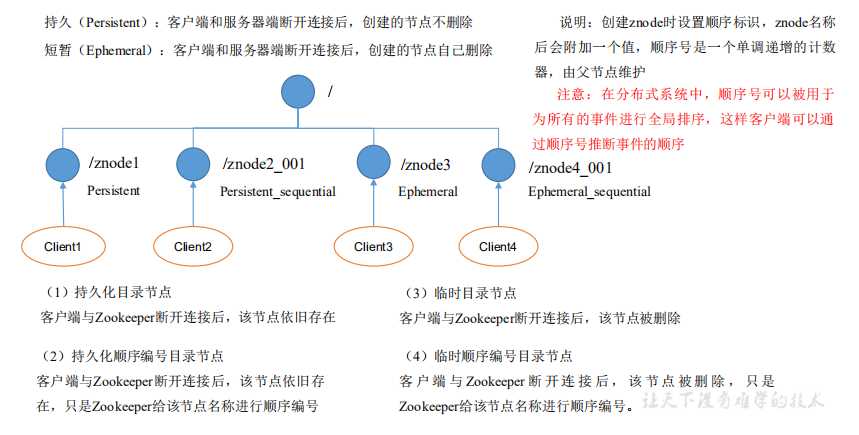
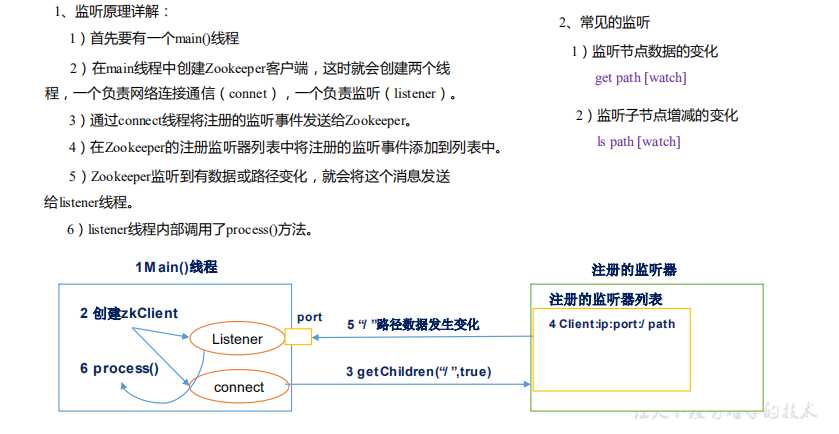
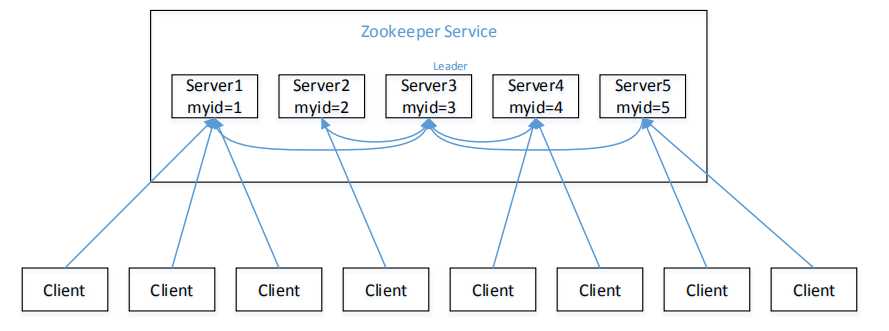
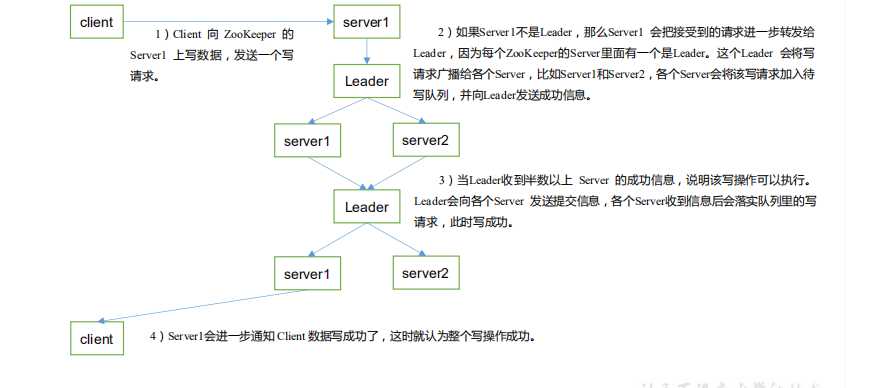
事务 ID 是 ZooKeeper 中所有修改总的次序。每个修改都有唯一的 zxid,如果 zxid1 小于 zxid2,那么 zxid1 在 zxid2 之前发生。
2)ctime - znode 被创建的毫秒数(从 1970 年开始)
3)mzxid - znode 最后更新的事务 zxid
4)mtime - znode 最后修改的毫秒数(从 1970 年开始)
5)pZxid-znode 最后更新的子节点 zxid
6)cversion - znode 子节点变化号,znode 子节点修改次数
7)dataversion - znode 数据变化号
8)aclVersion - znode 访问控制列表的变化号
9)ephemeralOwner- 如果是临时节点,这个是 znode 拥有者的 session id。如果不是临时节点则是 0。
10)dataLength- znode 的数据长度
11)numChildren - znode 子节点数量