标签:isp rsa 比例 ctime 最优 多少 训练 概念 空间
大部分模型的默认阈值为输出值的中位数。比如逻辑回归的输出范围为[0,1],当某个样本的输出大于0.5就会被划分为正例,反之为反例。在数据的类别不平衡时,采用默认的分类阈值可能会导致输出全部为反例,产生虚假的高准确度,导致分类失败。因此很多答主提到了几点:1. 可以选择调整阈值,使得模型对于较少的类别更为敏感 2. 选择合适的评估标准,比如ROC或者F1,而不是准确度(accuracy)。(这里给出ROC/AUC以及和acc的区别举个简单的例子, 连接:)Sklearn的决策树有一个参数是class_weight,就是用来调整分类阈值的,文档中的公式:
# 权重与样本数中每个类别的数量为负相关,越少见的类别权重越大
n_samples / (n_classes * np.bincount(y))
所以遇到不平衡数据,用集成学习+阈值调整可以作为第一步尝试。
而通过采样(sampling)来调整数据的不平衡,是另一种解决途径,并且可以和阈值调整同时使用。但采样法不是单纯的从数据角度改变了模型阈值,还改变了模型优化收敛等一系列过程,在此不赘述。
我们使用的第一个实验数据是Cardio(Cardiotocogrpahy dataset),原始数据大小为 :也就是1831条数据,每条数据有21个特征。其中正例176个(9.6122%),反例1655个(90.3878%),属于典型的类别不平衡问题。
先来看一张可视化图,因为原始数据是21维不易展示,所以我们使用T-SNE把数据嵌入到2维空间。图中红色代表正例,蓝色代表反例(建议在电脑端阅读)。数据重叠会加深颜色,甚至造成颜色混合。左上、左下、右上和右下依次是:
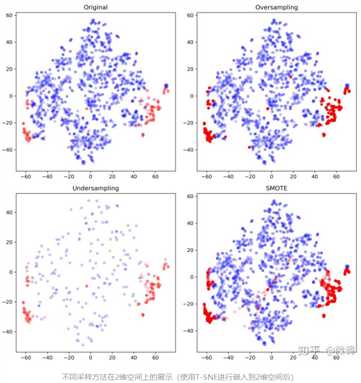
所以可以很直观地从图中看出:
1. 过采样(右上)只是单纯的重复了正例,因此会过分强调已有的正例。如果其中部分点标记错误或者是噪音,那么错误也容易被成倍的放大。因此最大的风险就是对正例过拟合。
2. 欠采样(左下)抛弃了大部分反例数据,从而弱化了中间部分反例的影响,可能会造成偏差很大的模型。当然,如果数据不平衡但两个类别基数都很大,或许影响不大。同时,数据总是宝贵的,抛弃数据是很奢侈的,因此另一种常见的做法是反复做欠采样,生成 个新的子样本。其中每个样本的正例都使用这176个数据,而反例则从1655个数据中不重复采样。最终对这9个样本分别训练,并集成结果。这样数据达到了有效利用,但也存在风险:
3. SMOTE(右下)可以看出和过采样(右上)有了明显的不同,因为不单纯是重复正例了,而是在局部区域通过K-近邻生成了新的正例。相较于简单的过采样, SMOTE:
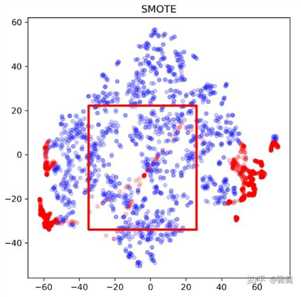
让我们把实验所中归纳出的经验性性质总结一下,实验细节和结果在文末:
但是不是过采样就是万能药?未必。首先,它不可避免的带来更大的运算开销,其次当数据中噪音过大时,结果反而可能会更差因为噪音也被重复使用。当然,除此以外还有更严谨的统计学理论说明采样的力量,以及如何正确采样,此处按下不表。我的一个不成熟的经验是:使用过采样(或SMOTE)+强正则模型(如XGBoost)可能比较适合不平衡的数据。拿到一个新的数据时,可以不妨直接先试试这个方法,作为基准(Baseline)。
多说两句的话,很多方法都可以结合起来,比如过采样和欠采样是可以结合起来的。一个比较成熟的算法就是用SMOTE过采样,再利用Tomek‘s link再控制新的样本空间。有兴趣的朋友可以移步4. Combination of over- and under-sampling,这个例子的作者开发了imbalanced-learn(Welcome to imbalanced-learn documentation!),是一个Python上处理数据不平衡的工具库,这个答案中的实验代码都是基于这个工具库。
实验细节:从实际的模型表现上进行一个对比
Cardio数据集:Cardiotocogrpahy dataset
Data: cardio | shape: (1831, 21) | F1 Threshold Moving: 0.829987896832 Original: 0.805920420913 Oversampling: 0.963759891658 Undersampling: 0.938725868726 Undersampling Ensemble: 0.821234363304 SMOTE: 0.971714100029 Data: cardio | shape: (1831, 21) | ROC Threshold Moving: 0.992879432167 Original: 0.991171853188 Oversampling: 0.992246339935 Undersampling: 0.992405698663 Undersampling Ensemble: 0.992896183665 SMOTE: 0.993895382919
Letter数据集:Letter Recognition dataset
Data: letter | shape: (1600, 32) | F1 Threshold Moving: 0.257964355223 Original: 0.2322000222 Oversampling: 0.80419404639 Undersampling: 0.762522610875 Undersampling Ensemble: 0.265496694535 SMOTE: 0.94066718832 Data: letter | shape: (1600, 32) | ROC Threshold Moving: 0.778733333333 Original: 0.775133333333 Oversampling: 0.853071111111 Undersampling: 0.798 Undersampling Ensemble: 0.7762 SMOTE: 0.961724444444
Mnist数据集:mnist dataset - ODDS
Data: mnist | shape: (7603, 100) | F1 Threshold Moving: 0.809942609314 Original: 0.843460421197 Oversampling: 0.963745254804 Undersampling: 0.939662842407 Undersampling Ensemble: 0.795183545913 SMOTE: 0.972652248517 Data: mnist | shape: (7603, 100) | ROC Threshold Moving: 0.985425233631 Original: 0.985211857272 Oversampling: 0.991881775625 Undersampling: 0.976346938776 Undersampling Ensemble: 0.977791067047 SMOTE: 0.99455044033
Ionosphere数据集:Ionosphere dataset
Data: ionosphere | shape: (351, 33) | F1 Threshold Moving: 0.755263843708 Original: 0.77205596336 Oversampling: 0.858191681928 Undersampling: 0.787040254432 Undersampling Ensemble: 0.757907605743 SMOTE: 0.849245387823 Data: ionosphere | shape: (351, 33) | ROC Threshold Moving: 0.8816344887 Original: 0.88384133982 Oversampling: 0.946363011452 Undersampling: 0.881254109139 Undersampling Ensemble: 0.87103349549 SMOTE: 0.953137058851
Pima数据集:Pima Indians Diabetes dataset
Data: pima | shape: (768, 8) | F1 Threshold Moving: 0.684815686152 Original: 0.614437063812 Oversampling: 0.744106797407 Undersampling: 0.762079698321 Undersampling Ensemble: 0.667769584397 SMOTE: 0.749990784595 Data: pima | shape: (768, 8) | ROC Threshold Moving: 0.824891737892 Original: 0.824757834758 Oversampling: 0.83276 Undersampling: 0.825577308626 Undersampling Ensemble: 0.82011965812 SMOTE: 0.84188
Q: 请问在算F1的时候阈值是多少?
A: F1基于precision和recall,使用逻辑回归时阈值默认都是0.5
Q: 你采样所带来的F1提升并非来源于模型精度的提升,只是变相调整了阈值
A: 这说的就是这么个道理啊,直接调阈值也是一种手段,但直接调到不平衡比例也不一定效果好。采样的效果不仅仅是变相调整阈值这么简单,还会影响模型的学习过程以及是否收敛,那就不是一篇文章不用数学能说明白的了。
Q: 既然直接调阈值就能达到F1提升,采样不是多此一举吗?
A: 我补一个实验(改变阈值)作为对照吧...改变阈值不会改变优化和收敛过程,而加入新的采样一定会的,所以不等价。
Q: 为什么不用AUC做metric呢?
A: 因为roc不是point estimation,也就不存在阈值这个概念了,我想体现的就是默认阈值下采样的效果。可能这个评估方法可能不够全面,可以再补一个roc的评估。
Q: 我想表达的是无论采样到底是否对模型有帮助,用未优化阈值的F1来做metric都是不准确的
Q: 因为F1是存在最优阈值的,你现在的工作本质上是改变数据的分布,使数据对应的F1最优阈值更接近0.5罢了,对于采样本身的价值并没有说服力。
1、欠采用和过采样对模型带来什么影响?(包括对数据不平衡问题的解决方案以及采样方法的分析)
标签:isp rsa 比例 ctime 最优 多少 训练 概念 空间
原文地址:https://www.cnblogs.com/rushup0930/p/13356383.html