标签:ccf 重点 tps intro amd 常用 依赖 形式 格式
Prometheus是一套开源的系统监控报警框架。Prometheus作为新一代的云原生监控系统,相比传统监控监控系统(Nagios或者Zabbix)拥有如下优点。
易管理性
Prometheus: Prometheus核心部分只有一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储。
Nagios: 需要有专业的人员进行安装,配置和管理,并且过程很复杂。
业务数据相关性
Prometheus:监控服务的运行状态,基于Prometheus丰富的Client库,用户可以轻松的在应用程序中添加对Prometheus的支持,从而让用户可以获取服务和应用内部真正的运行状态。
Nagios:大部分的监控能力都是围绕系统的一些边缘性的问题,主要针对系统服务和资源的状态以及应用程序的可用性。
另外Prometheus还存在以下优点:
高效:单一Prometheus可以处理数以百万的监控指标;每秒处理数十万的数据点。
易于伸缩:通过使用功能分区(sharing)+联邦集群(federation)可以对Prometheus进行扩展,形成一个逻辑集群;Prometheus提供多种语言的客户端SDK,这些SDK可以快速让应用程序纳入到Prometheus的监控当中。
良好的可视化:Prometheus除了自带有Prometheus UI,Prometheus还提供了一个独立的基于Ruby On Rails的Dashboard解决方案Promdash。另外最新的Grafana可视化工具也提供了完整的Proetheus支持,基于Prometheus提供的API还可以实现自己的监控可视化UI。
参考官网:官网
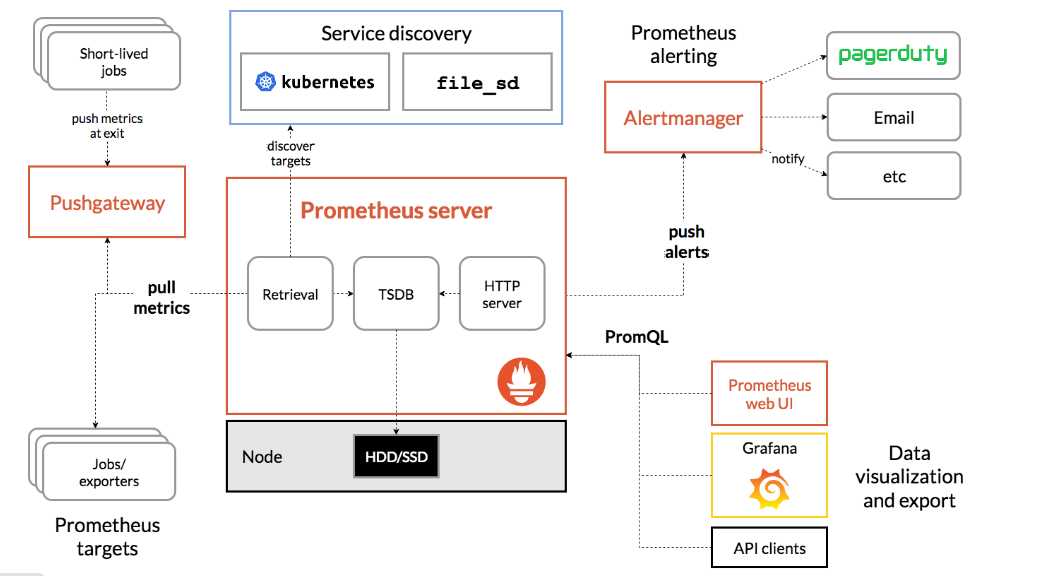
Prometheus Server:Prometheus Sever是Prometheus组件中的核心部分,负责实现对监控数据的获取,存储及查询。Prometheus Server可以通过静态配置管理监控目标,也可以配合使用Service Discovery的方式动态管理监控目标,并从这些监控目标中获取数据。其次Prometheus Sever需要对采集到的数据进行存储,Prometheus Server本身就是一个实时数据库,将采集到的监控数据按照时间序列的方式存储在本地磁盘当中。Prometheus Server对外提供了自定义的PromQL,实现对数据的查询以及分析。另外Prometheus Server的联邦集群能力可以使其从其他的Prometheus Server实例中获取数据。
Exporters:Exporter将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可以获取到需要采集的监控数据。可以将Exporter分为2类:
直接采集:这一类Exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向Prometheus暴露监控数据的端点。
间接采集:原有监控目标并不直接支持Prometheus,因此需要通过Prometheus提供的Client Library编写该监控目标的监控采集程序。例如:Mysql Exporter,JMX Exporter,Consul Exporter等。
AlertManager:在Prometheus Server中支持基于Prom QL创建告警规则,如果满足Prom QL定义的规则,则会产生一条告警。在AlertManager从 Prometheus server 端接收到 alerts后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty,webhook 等。
PushGateway:Prometheus数据采集基于Prometheus Server从Exporter pull数据,因此当网络环境不允许Prometheus Server和Exporter进行通信时,可以使用PushGateway来进行中转。通过PushGateway将内部网络的监控数据主动Push到Gateway中,Prometheus Server采用针对Exporter同样的方式,将监控数据从PushGateway pull到Prometheus Server。
1.Prometheus server定期从配置好的jobs或者exporters中拉取metrics,或者接收来自Pushgateway发送过来的metrics,或者从其它的Prometheus server中拉metrics。
2.Prometheus server在本地存储收集到的metrics,并运行定义好的alerts.rules,记录新的时间序列或者向Alert manager推送警报。
3.Alertmanager根据配置文件,对接收到的警报进行处理,发出告警。
4.在图形界面中,可视化采集数据。
| 主机名 | IP | 描述 | |
| 监控主机 | pro01 | 192.168.253.42 | docker, prometheus, grafana, exporter,alertmanager |
| 被监控主机 | exp02 | 192.168.253.57 192.168.253.42 | exporter |
docker的安装这里就不说了。
docker pull prom/prometheus
5.1 创建prometheus工作目录
mkdir -p /data/prometheus mkdir /data/prometheus/data chown 777 /data/prometheus/data mkdir /data/prometheus/rules
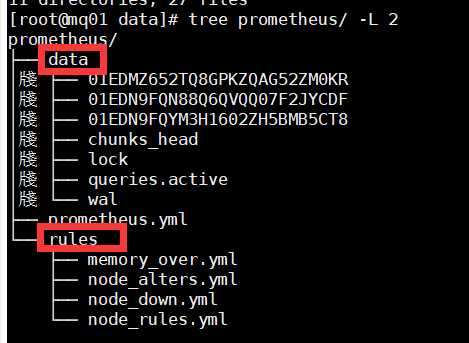
编写prometheus.yml文件
chown 777 /data/prometheus/prometheus.yml
vim /data/prometheus/prometheus.yml # my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: [‘193.168.253.42:9093‘] # - alertmanager:9093 # Load rules once and periodically evaluate them according to the global ‘evaluation_interval‘. rule_files: - "node_down.yml" # - "first_rules.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it‘s Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: ‘prometheus‘ static_configs: - targets: [‘localhost:9090‘]- job_name: ‘node‘ scrape_interval: 8s static_configs: - targets: [‘193.168.253.42:9100‘]
以上yml文件,配置了alertmanager,用于告警,匹配规则为node_down,节点如果down掉就会触发警告,job_name 有三个,监控本机9090,8080,9100端口,分别为三种不同的组件
启动prometheus
docker run -d -p 9090:9090 -v /data/prometheus/data:/prometheus -v /data/prometheus:/etc/prometheus --name pro prom/prometheus

浏览器访问
拉取镜像
docker pull grafana/grafana
启动grafana
docker run -p -d 3000:3000 --name grafana grafana/grafana
查看容器
浏览器访问
浏览器访问http://192.168.253.42:3000(IP:3000端口),即可打开grafana页面,默认用户名密码都是admin,初次登录会要求修改默认的登录密码
添加prometheus数据源
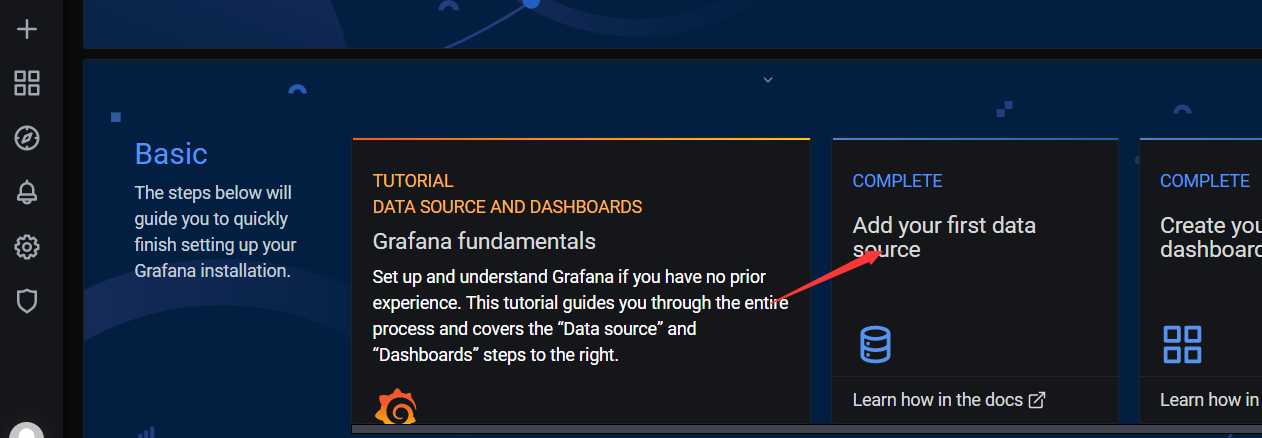
(1)点击主界面"Add your first data source"
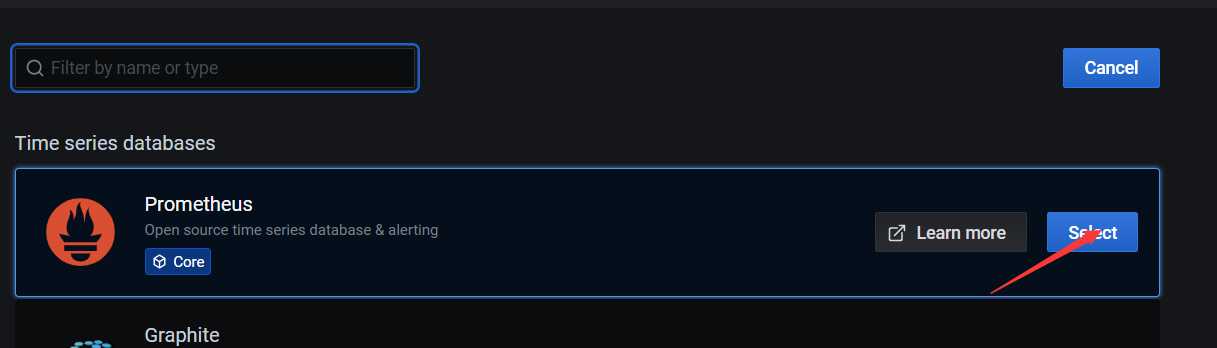
(2)选择Prometheus
(3)填写数据源设置项
URL处填写Prometheus服务所在的IP地址,此处我们将Prometheus服务与Grafana安装在同一台机器上,直接填写localhost或者ip就行
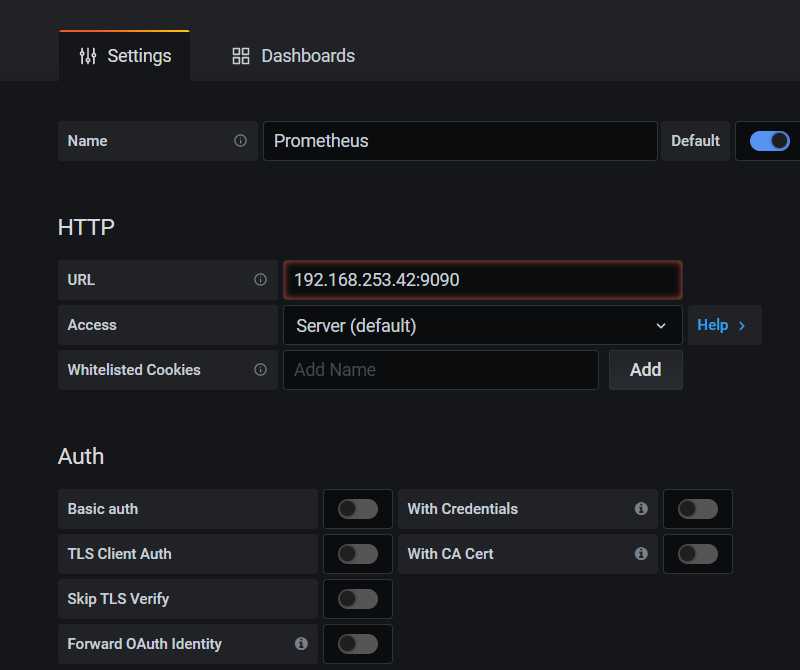
点击下方 【Save & Test】按钮,保存设置

(4)Dashboards页面选择“Prometheus 2.0 Stats”
点击Dashboards选项卡,选择Prometheus 2.0 Stats
(5)查看监控
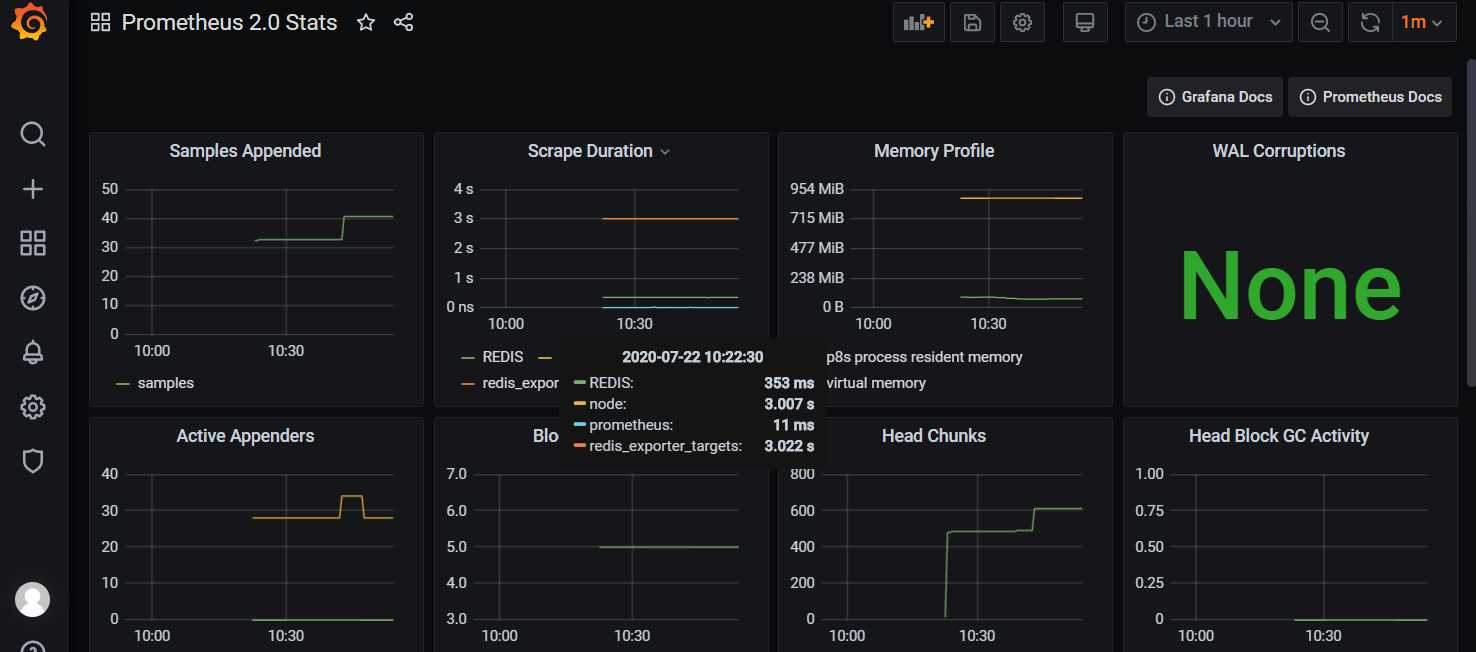
点击Grafana图标,切换到Grafana主页面,然后点击Home,选择我们刚才添加的Prometheus 2.0 Stats,即可看到监控数据

以下操作皆在被监控主机(pro01,exp02)上操作。
下载node-exporter地址:https://github.com/prometheus/node_exporter/releases
解压node-exporter
tar xzf node_exporter-0.18.1.linux-amd64.tar.g mv node_exporter-0.18.1.linux-amd64 /data/node_exporter
启动
cd /data/node_exporter
./node_exporter
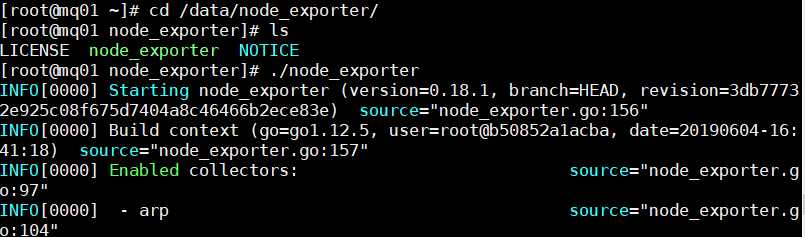
浏览器访问
设置node_exporter 以服务的方式启动并设置开机自启
添加系统服务
vim /etc/systemd/system/node_exporter.service
[Unit] Description=node_exporter After=network.target [Service] ExecStart=/data/node_exporter/node_exporter Restart=on-failure [Install] WantedBy=multi-user.target
启动服务,设置开机自启,并检查服务开启状态
# systemctl daemon-reload
# systemctl enable node_exporter
# systemctl start node_exporter
# systemctl status node_exporter
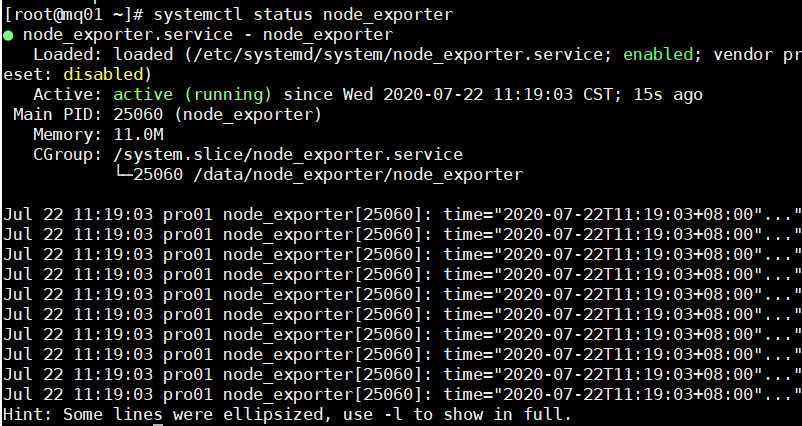
浏览器访问:
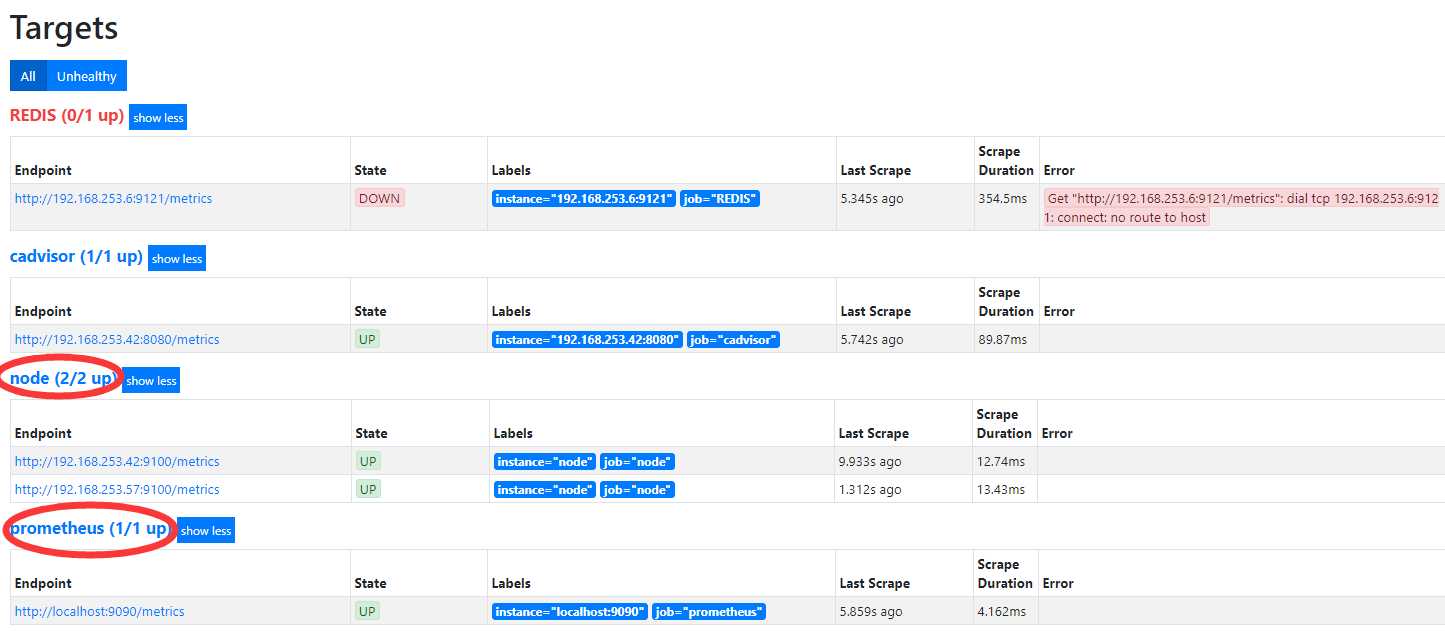
拉取镜像:
docker pull prom/alertmanager
创建工作目录
mkdir -p /data/alertmanager/storage mkdir /data/alertmanager/template chown 777 /data/alertmanager/storage
修改配置
vim /data/alertmanager/alertmanager.yml
global: smtp_smarthost: ‘smtp.qq.com:465‘ #smtp地址 smtp_from: ‘258xxx9221@qq.com‘ #谁发邮件 smtp_auth_username: ‘258xxx9221@qq.com‘ #邮箱用户 smtp_auth_password: ‘xxxxxxx‘ #邮箱smtp授权码 smtp_require_tls: false templates: #定义模板 - ‘template/*.tmp1‘ route: group_by: [‘alertname‘] #分组名 group_wait: 30s #当收到警报,等待30秒看是否还有警报,如果有就一起发出去 group_interval: 5m # 发送警告间隔时间 repeat_interval: 3h # 重复报警的间隔时间 receiver: mail # 全局报警组,这个参数是必选的,和下面报警组名要相同 receivers: - name: ‘mail‘ # 报警组名 email_configs: - to: ‘{{ template "email.to" . }}‘ #发送给谁 html: ‘{{ template "email.to.html" . }}‘ send_resolved: true #告警抑制 inhibit_rules: - source_match: severity: ‘critical‘ target_match: severity: ‘warning‘ equal: [‘alertname‘, ‘dev‘, ‘instance‘]
简单介绍一下主要配置的作用:
global: 全局配置,包括报警解决后的超时时间、SMTP 相关配置、各种渠道通知的 API 地址等等。
route: 用来设置报警的分发策略,它是一个树状结构,按照深度优先从左向右的顺序进行匹配。
receivers: 配置告警消息接受者信息,例如常用的 email、wechat、slack、webhook 等消息通知方式。
inhibit_rules: 抑制规则配置,当存在与另一组匹配的警报(源)时,抑制规则将禁用与一组匹配的警报(目标)。
新建模板:
vim /data/alertmanager/template/email.tmpl
{{ define "email.from" }}11111111@qq.com{{ end }}
{{ define "email.to" }}22222222@qq.com{{ end }}
{{ define "email.to.html" }}
{{ range .Alerts }}
=========start==========<br>
告警程序: prometheus_alert <br>
告警级别: {{ .Labels.severity }} 级 <br>
告警类型: {{ .Labels.alertname }} <br>
故障主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
触发时间: {{ .StartsAt.Format "2019-08-04 16:58:15" }} <br>
=========end==========<br>
{{ end }}
{{ end }}
说明:
define 用来定义变量,配置3个变量,分别是:email.from、email.to、email.to.html ,可以在 alertmanager.yml 文件中直接配置引用。
这里 email.to.html 就是要发送的邮件内容,支持 Html 和 Text 格式。为了显示好看,采用 Html 格式简单显示信息。
{{ range .Alerts }} 是个循环语法,用于循环获取匹配的 Alerts 的信息,下边的告警信息跟上边默认邮件显示信息一样,只是提取了部分核心值来展示。
启动服务
docker run -d -p 9093:9093 --name alertmanager --restart=always -v /data/alertmanager:/etc/alertmanager -v /data/alertmanager/storage:/alertmanager prom/alertmanager
浏览器访问:
http://192.168.253.42:9093
根据prometheus.yml文件,编写匹配规则
cd /data/prometheus/rules
vim node_down.yml
groups:
- name: node-up
rules:
- alert: node-up
expr: up{job="node-exporter"} == 0
for: 15s
labels:
severity: 1
team: node
annotations:
summary: "{{ $labels.instance }} 已停止运行!"
description: "{{ $labels.instance }} 检测到异常停止!请重点关注!!!"
vim memory_over.yml
expr 是计算公式,(1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes))) * 100 表示获取内存使用率
groups: - name: example rules: - alert: NodeMemoryUsage expr: (1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes))) * 100 > 80 for: 1m labels: severity: warning annotations: summary: "{{$labels.instance}}: High Memory usage detected" description: "{{$labels.instance}}: Memory usage is above 80% (current value is:{{ $value }})"
重启peometheus
docker restart pro
访问告警页面
http://192.168.253.42:9090/alerts
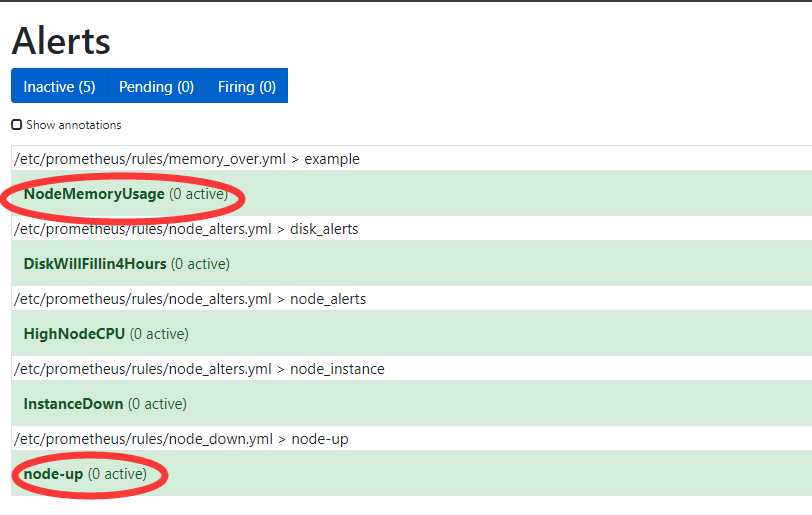
测试报警
这里直接修改 /data/prometheus/rules/memory_over.yml文件,告警阈值改为10
expr: (1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes))) * 100 > 10
重启prometheus
docker restart pro
等待一分钟,出pending
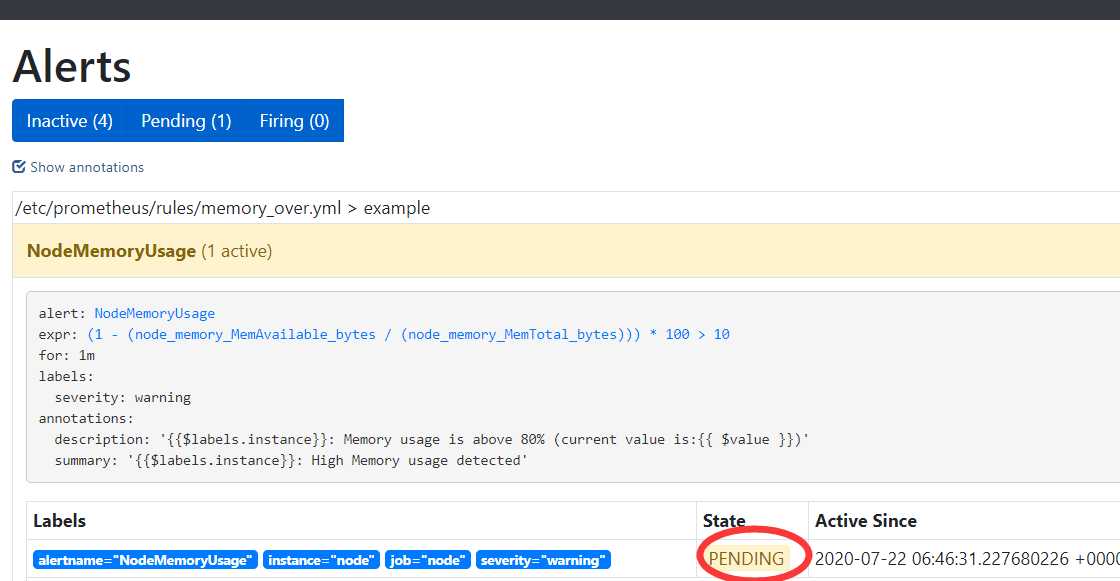
再等待一分钟,会出现Firing
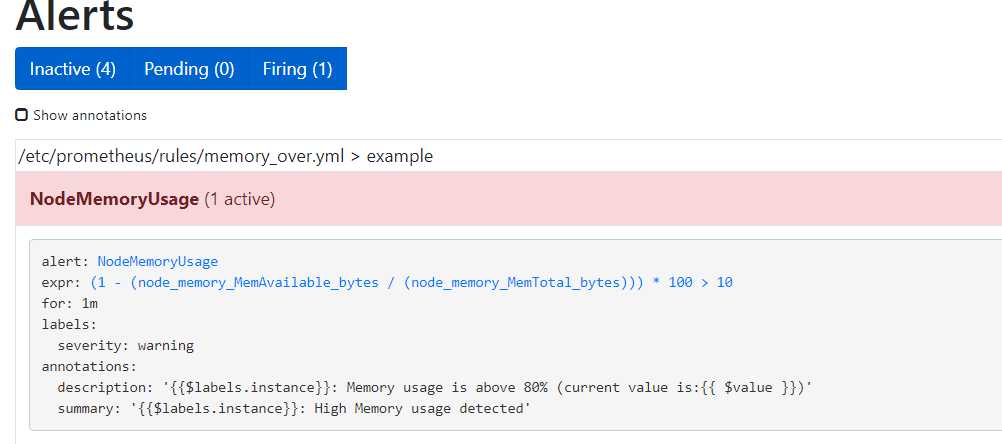
查看邮件
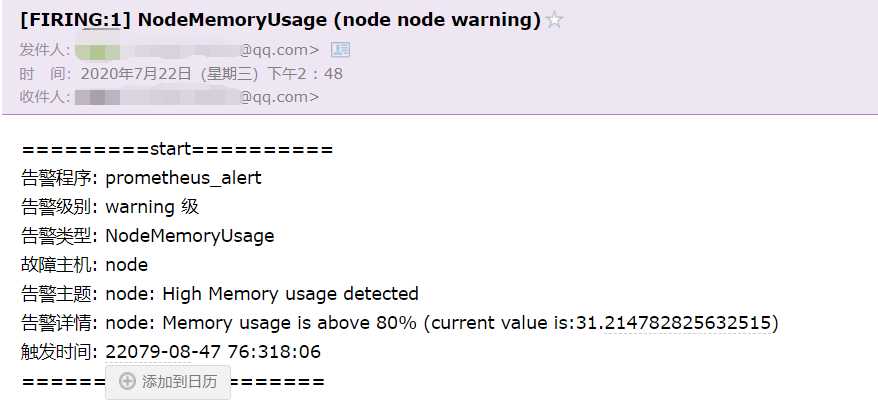
如果有没收到邮件,查看日志
docker logs -f alertmanager
标签:ccf 重点 tps intro amd 常用 依赖 形式 格式
原文地址:https://www.cnblogs.com/lanist/p/13331391.html