标签:strip oschina 公众 block comment 关注 性能对比 多线程 mes
现代CPU为了提升性能都会有自己的缓存结构,而多核CPU为了同时正常工作,引入了MESI,作为CPU缓存之间同步的协议。MESI虽然很好,但是不当的时候用也可能导致性能的退化。
到底怎么回事呢?一起来看看吧。
为了提升处理速度,CPU引入了缓存的概念,我们先看一张CPU缓存的示意图:

CPU缓存是位于CPU与内存之间的临时数据交换器,它的容量比内存小的多但是交换速度却比内存要快得多。
CPU的读实际上就是层层缓存的查找过程,如果所有的缓存都没有找到的情况下,就是主内存中读取。
为了简化和提升缓存和内存的处理效率,缓存的处理是以Cache Line(缓存行)为单位的。
一次读取一个Cache Line的大小到缓存。
在mac系统中,你可以使用sysctl machdep.cpu.cache.linesize来查看cache line的大小。 在linux系统中,使用getconf LEVEL1_DCACHE_LINESIZE来获取cache line的大小。
本机中cache line的大小是64字节。
考虑下面一个对象:
public class CacheLine {
public long a;
public long b;
}
很简单的对象,通过之前的文章我们可以指定,这个CacheLine对象的大小应该是12字节的对象头+8字节的long+8字节的long+4字节的补全,总共应该是32字节。
因为32字节< 64字节,所以一个cache line就可以将其包括。
现在问题来了,如果是在多线程的环境中,thread1对a进行累加,而thread2对b进行累加。会发生什么情况呢?
大家注意,耗时点就在第4步。 虽然a和b是两个不同的long,但是因为他们被包含在同一个cache line中,最终导致了虽然两个线程没有共享同一个数值对象,但是还是发送了锁的关联情况。
那怎么解决这个问题呢?
在JDK7之前,我们需要使用一些空的字段来手动补全。
public class CacheLine {
public long actualValue;
public long p0, p1, p2, p3, p4, p5, p6, p7;
}
像上面那样,我们手动填充一些空白的long字段,从而让真正的actualValue可以独占一个cache line,就没有这些问题了。
但是在JDK8之后,java文件的编译期会将无用的变量自动忽略掉,那么上面的方法就无效了。
还好,JDK8中引入了sun.misc.Contended注解,使用这个注解会自动帮我们补全字段。
接下来,我们使用JOL工具来分析一下Contended注解的对象和不带Contended注解的对象有什么区别。
[@Test](https://my.oschina.net/azibug)
public void useJol(www.shentuylgw.cn) {
log.info("{www.chuancenpt.com}", ClassLayout.parseClass(CacheLine.class).toPrintable());
log.info("{www.jintianxuesha.com}", ClassLayout.parseInstance(new CacheLine()).toPrintable());
log.info("{}", ClassLayout.parseClass(CacheLinePadded.class).toPrintable());
log.info("{}", ClassLayout.parseInstance(new CacheLinePadded()).toPrintable());
}
注意,在使用JOL分析Contended注解的对象时候,需要加上 -XX:-RestrictContended参数。
同时可以设置-XX:ContendedPaddingWidth 来控制padding的大小。
INFO com.flydean.CacheLineJOL - com.flydean.CacheLine object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) d0 29 17 00 (11010000 00101001 00010111 00000000) (1518032)
12 4 (alignment/padding gap)
16 8 long CacheLine.valueA 0
24 8 long CacheLine.valueB 0
Instance size: 32 bytes
Space losses: 4 bytes internal + 0 bytes external = 4 bytes total
INFO com.flydean.CacheLineJOL - com.flydean.CacheLinePadded object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 www.gaodeyulept.cn (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
4 4 www.jujinyule.com (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 www.youy2zhuce.cn (object header) d2 5d 17 00 (11010010 01011101 00010111 00000000) (1531346)
12 4 (alignment/padding gap)
16 8 long CacheLinePadded.b 0
24 128 (alignment/padding gap)
152 8 long CacheLinePadded.a 0
Instance size: 160 bytes
Space losses: 132 bytes internal + 0 bytes external = 132 bytes total
我们看到使用了Contended的对象大小是160字节。直接填充了128字节。
sun.misc.Contended是在JDK8中引入的,为了解决填充问题。
但是大家注意,Contended注解是在包sun.misc,这意味着一般来说是不建议我们直接使用的。
虽然不建议大家使用,但是还是可以用的。
但如果你使用的是JDK9-JDK14,你会发现sun.misc.Contended没有了!
因为JDK9引入了JPMS(Java Platform Module System),它的结构跟JDK8已经完全不一样了。
经过我的研究发现,sun.misc.Contended, sun.misc.Unsafe,sun.misc.Cleaner这样的类都被移到了jdk.internal.**中,并且是默认不对外使用的。
那么有人要问了,我们换个引用的包名是不是就行了?
import jdk.internal.vm.annotation.Contended;
抱歉还是不行。
error: package jdk.internal.vm.annotation is not visible
@jdk.internal.vm.annotation.Contended
^
(package jdk.internal.vm.annotation is www.ued3zc.cn declared in module
java.base, which does not export www.javachenglei.com to the unnamed module)
好,我们找到问题所在了,因为我们的代码并没有定义module,所以是一个默认的“unnamed” module,我们需要把java.base中的jdk.internal.vm.annotation使unnamed module可见。
要实现这个目标,我们可以在javac中添加下面的flag:
--add-exports java.base/jdk.internal.vm.annotation=ALL-UNNAMED
好了,现在我们可以正常通过编译了。
上面我们看到padded对象大小是160字节,而unpadded对象的大小是32字节。
对象大了,运行的速度会不慢呢?
实践出真知,我们使用JMH工具在多线程环境中来对其进行测试:
@State(Scope.Benchmark)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@Fork(value = 1, jvmArgsPrepend = "-XX:-RestrictContended")
@Warmup(iterations = 10)
@Measurement(iterations = 25)
@Threads(2)
public class CacheLineBenchMark {
private CacheLine cacheLine= new CacheLine();
private CacheLinePadded cacheLinePadded = new CacheLinePadded();
@Group("unpadded")
@GroupThreads(1)
@Benchmark
public long updateUnpaddedA() {
return cacheLine.a++;
}
@Group("unpadded")
@GroupThreads(1)
@Benchmark
public long updateUnpaddedB() {
return cacheLine.b++;
}
@Group("padded")
@GroupThreads(1)
@Benchmark
public long updatePaddedA() {
return cacheLinePadded.a++;
}
@Group("padded")
@GroupThreads(1)
@Benchmark
public long updatePaddedB() {
return cacheLinePadded.b++;
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(CacheLineBenchMark.class.getSimpleName())
.build();
new Runner(opt).run();
}
}
上面的JMH代码中,我们使用两个线程分别对A和B进行累计操作,看下最后的运行结果:
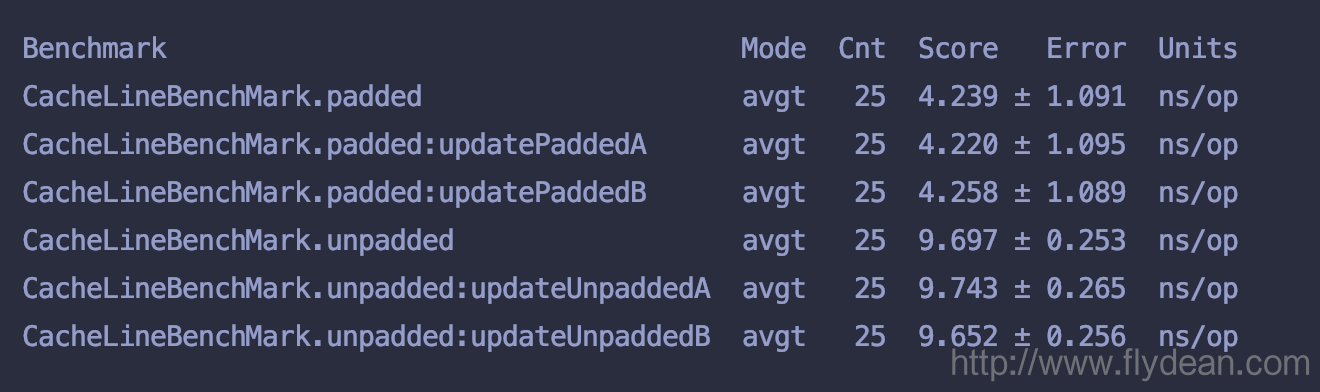
从结果看来虽然padded生成的对象比较大,但是因为A和B在不同的cache line中,所以不会出现不同的线程去主内存取数据的情况,因此要执行的比较快。
其实Contended注解在JDK源码中也有使用,不算广泛,但是都很重要。
比如在Thread中的使用:

比如在ConcurrentHashMap中的使用:
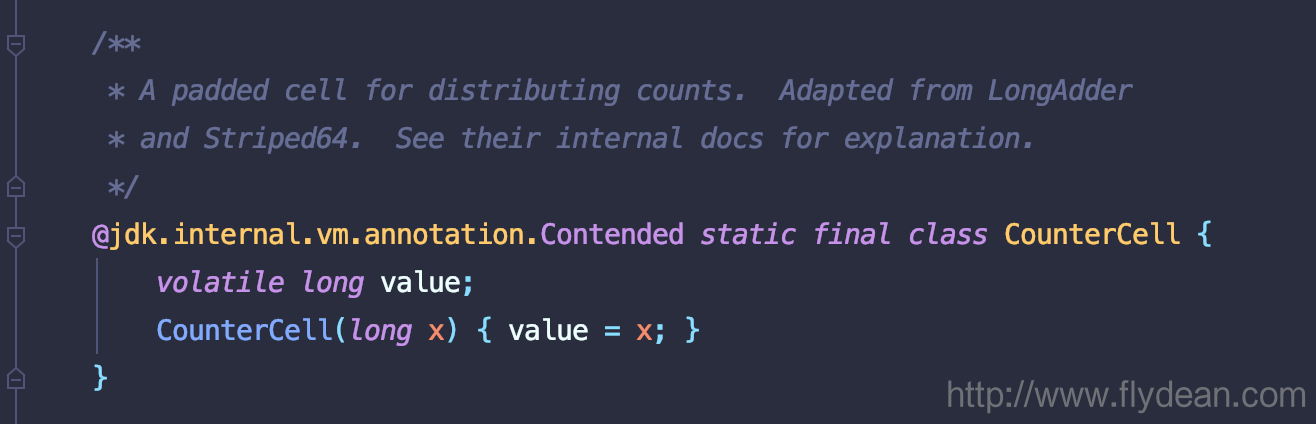
其他使用的地方:Exchanger,ForkJoinPool,Striped64。
感兴趣的朋友可以仔细研究一下。
Contented从最开始的sun.misc到现在的jdk.internal.vm.annotation,都是JDK内部使用的class,不建议大家在应用程序中使用。
这就意味着我们之前使用的方式是不正规的,虽然能够达到效果,但是不是官方推荐的。那么我们还有没有什么正规的办法来解决false-sharing的问题呢?
有知道的小伙伴欢迎留言给我讨论!
本文链接:http://www.flydean.com/jvm-contend-false-sharing/
本文来源:flydean的博客
欢迎关注我的公众号:程序那些事,更多精彩等着您!
JVM系列之:Contend注解和false-sharing
标签:strip oschina 公众 block comment 关注 性能对比 多线程 mes
原文地址:https://www.cnblogs.com/woshixiaowang/p/13365626.html