标签:mat update print 预训练模型 领域 介绍 zip ural init

自然语言处理(Natural Language Processing, NLP)是指计算机通过分析文本,建立计算框架实现语言表示及应用的模型,从而使其获得对语言的理解及应用的能力。从1950年Turing提出著名的“图灵测试”以来,让机器学会“听”和“说”,实现与人类间的无障碍交流成为人机交互领域的一大梦想。近年来随着深度学习技术的发展,自然语言处理领域也取得重要突破,发展成为人工智能领域的一个重要分支,涵盖语音识别、信息检索、信息提取、机器翻译、智能问答等众多应用场景。
在一些自然语言处理任务中,往往难以获得足够的训练数据,从而较难达到理想的训练效果。而预训练技术在计算机视觉领域的应用证实其可以极大改善下游任务模型对数据量的需求,并且可以大幅提升下游任务效果。借鉴与此,自然语言处理开始尝试使用预训练实现迁移学习。2003年NNLM提出用神经网络实现语言模型,到2013年在此基础上发展出的Word2Vec在多数任务取得提升,使得词向量方法成为广泛应用的文本表征技术。2018年ELMo提出的上下文相关的表示方法在处理多义词方面表现惊艳;随后GPT引入Transformer结构使得预训练技术开始在自然语言处理领域大放异彩;随后BERT的横空出世,通过Masked-LM建立基于Transformer的双向预训练模型,横扫各大NLP任务,成为NLP发展史上的里程碑,从此将NLP的预训练研究推向一个高潮。关于预训练技术在NLP领域的详细发展史,有兴趣的读者可以参考文献[]或者知乎文章[]。
BERT开启了NLP的新纪元,此后出现了众多基于BERT的改进模型,MASS[] (Masked Sequence to Sequence Pre-training for Language Generation) 便是其中较为出类拔萃者。

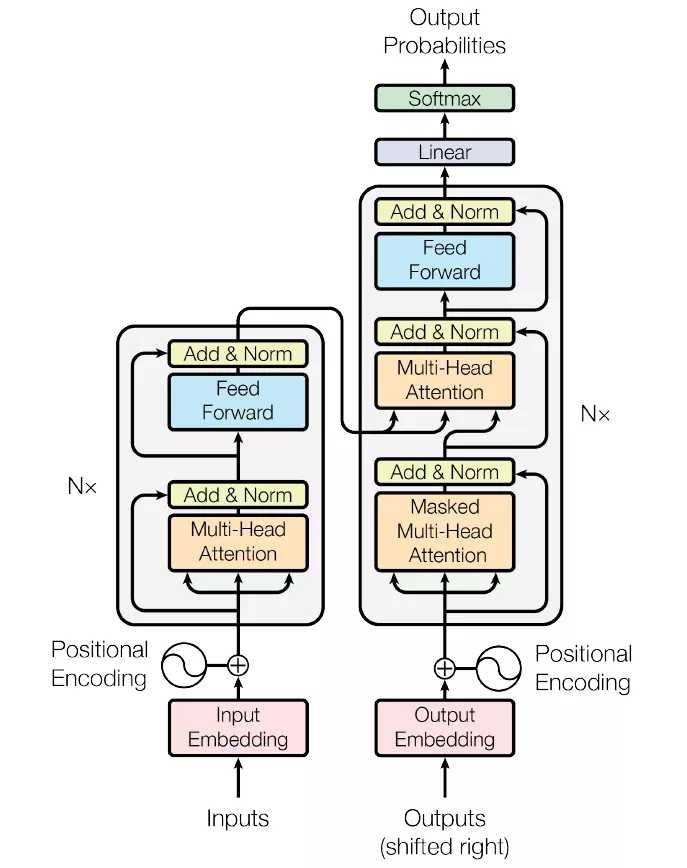
图1. Transformer网络结构
MASS是一种Seq2Seq的学习框架,采用Transformer结构(如图1所示),由encoder和decoder组成,并且在二者之间引入attention,网络结构如图2所示。在训练时,首先根据特定语言模型mask句子中的部分单词并将其作为encoder的输入,encoder对输入进行编码;将encoder的输出作为decoder的输入,同时mask源输入中未做mask处理的词,decoder根据源输入及先前的预测结果给出当前词的预测。
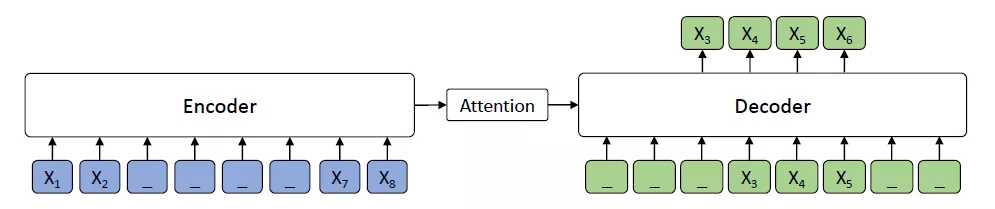
图1. MASS网络的encoder-decoder结构
和BERT的区别在于,MASS加强了encoder和decoder之间的联系,可以同时训练encoder和decoder:遮盖部分词作为encoder的输入,在encoder中预测输入中被遮盖的词,使其更好地理解和编码未遮盖的词;在decoder的输入中,遮盖掉原始输入未被遮盖的词,使decoder的预测结果更依赖于原始输入,而不是上一次的预测结果。同时,MASS之强大竟然一统BERT和GPT,两者分别是MASS网络中只mask一个词与mask所有词的边界条件,如图2所示为BERT和GPT在MASS世界观中的结构表示,如此对比,一目了然。可见,语言模型是MASS网络的重要组成部分,对于语言模型的mask处理,论文中给出的方法为:对于输入序列,随机选取一段连续位置(论文给出了50%的mask比例),将其中的80%做mask处理,10%随机替换为其他词,其余10%不作处理。

图2. BERT(a)及GPT(b)模型结构

MindSpore中已经实现了MASS网络跳转链接,这里将简要介绍如何使用Mindspore定义MASS网络以及进行训练及推理。Enjoy!
1)MinnSpore中的MASS网络实现
MASS基本网络结构为Transformer,在MindSpore中的定义如下:
class Transformer(nn.Cell):
"""
Transformer with encoder and decoder.
In Transformer, we define T = src_max_len, T‘ = tgt_max_len.
Args:
config (TransformerConfig): Model config.
is_training (bool): Whether is training.
use_one_hot_embeddings (bool): Whether use one-hot embedding.
Returns:
Tuple[Tensor], network outputs.
"""
def __init__(self,
config: TransformerConfig,
is_training: bool,
use_one_hot_embeddings: bool = False,
use_positional_embedding: bool = True):
super(Transformer, self).__init__()
self.use_positional_embedding = use_positional_embedding
config = copy.deepcopy(config)
self.is_training = is_training
if not is_training:
config.hidden_dropout_prob = 0.0
config.attention_dropout_prob = 0.0
self.input_mask_from_dataset = config.input_mask_from_dataset
self.batch_size = config.batch_size
self.max_positions = config.seq_length
self.attn_embed_dim = config.hidden_size
self.num_layers = config.num_hidden_layers
self.word_embed_dim = config.hidden_size
self.last_idx = self.num_layers - 1
self.embedding_lookup = EmbeddingLookup(
vocab_size=config.vocab_size,
embed_dim=self.word_embed_dim,
use_one_hot_embeddings=use_one_hot_embeddings)
if self.use_positional_embedding:
self.positional_embedding = PositionalEmbedding(
embedding_size=self.word_embed_dim,
max_position_embeddings=config.max_position_embeddings)
self.encoder = TransformerEncoder(
attn_embed_dim=self.attn_embed_dim,
encoder_layers=self.num_layers,
num_attn_heads=config.num_attention_heads,
intermediate_size=config.intermediate_size,
attention_dropout_prob=config.attention_dropout_prob,
initializer_range=config.initializer_range,
hidden_dropout_prob=config.hidden_dropout_prob,
hidden_act=config.hidden_act,
compute_type=config.compute_type)
self.decoder = TransformerDecoder(
attn_embed_dim=self.attn_embed_dim,
decoder_layers=self.num_layers,
num_attn_heads=config.num_attention_heads,
intermediate_size=config.intermediate_size,
attn_dropout_prob=config.attention_dropout_prob,
initializer_range=config.initializer_range,
dropout_prob=config.hidden_dropout_prob,
hidden_act=config.hidden_act,
compute_type=config.compute_type)
self.cast = P.Cast()
self.dtype = config.dtype
self.cast_compute_type = SaturateCast(dst_type=config.compute_type)
self.slice = P.StridedSlice()
self.dropout = nn.Dropout(keep_prob=1 - config.hidden_dropout_prob)
self._create_attention_mask_from_input_mask = CreateAttentionMaskFromInputMask(config)
self.scale = Tensor([math.sqrt(float(self.word_embed_dim))],
dtype=mstype.float32)
self.multiply = P.Mul()
def construct(self, source_ids, source_mask, target_ids, target_mask):
"""
Construct network.
In this method, T = src_max_len, T‘ = tgt_max_len.
Args:
source_ids (Tensor): Source sentences with shape (N, T).
source_mask (Tensor): Source sentences padding mask with shape (N, T),
where 0 indicates padding position.
target_ids (Tensor): Target sentences with shape (N, T‘).
target_mask (Tensor): Target sentences padding mask with shape (N, T‘),
where 0 indicates padding position.
Returns:
Tuple[Tensor], network outputs.
"""
# Process source sentences.
src_embeddings, embedding_tables = self.embedding_lookup(source_ids)
src_embeddings = self.multiply(src_embeddings, self.scale)
if self.use_positional_embedding:
src_embeddings = self.positional_embedding(src_embeddings)
src_embeddings = self.dropout(src_embeddings)
# Attention mask with shape (N, T, T).
enc_attention_mask = self._create_attention_mask_from_input_mask(source_mask)
# Transformer encoder.
encoder_output = self.encoder(
self.cast_compute_type(src_embeddings), # (N, T, D).
self.cast_compute_type(enc_attention_mask) # (N, T, T).
)
# Process target sentences.
tgt_embeddings, _ = self.embedding_lookup(target_ids)
tgt_embeddings = self.multiply(tgt_embeddings, self.scale)
if self.use_positional_embedding:
tgt_embeddings = self.positional_embedding(tgt_embeddings)
tgt_embeddings = self.dropout(tgt_embeddings)
# Attention mask with shape (N, T‘, T‘).
tgt_attention_mask = self._create_attention_mask_from_input_mask(
target_mask, True
)
# Transformer decoder.
decoder_output = self.decoder(
self.cast_compute_type(tgt_embeddings), # (N, T‘, D)
self.cast_compute_type(tgt_attention_mask), # (N, T‘, T‘)
encoder_output, # (N, T, D)
enc_attention_mask # (N, T, T)
)
return encoder_output, decoder_output, embedding_tables
对Transformer网络中的decoder输出的预测结果进行logSoftMax计算得到预测结果的归一化概率值,定义MASS的训练网络如下:
class TransformerTraining(nn.Cell):
"""
Transformer training network.
Args:
config (TransformerConfig): The config of Transformer.
is_training (bool): Specifies whether to use the training mode.
use_one_hot_embeddings (bool): Specifies whether to use one-hot for embeddings.
Returns:
Tensor, prediction_scores, seq_relationship_score.
"""
def __init__(self, config, is_training, use_one_hot_embeddings):
super(TransformerTraining, self).__init__()
self.transformer = Transformer(config, is_training, use_one_hot_embeddings)
self.projection = PredLogProbs(config)
def construct(self, source_ids, source_mask, target_ids, target_mask):
"""
Construct network.
Args:
source_ids (Tensor): Source sentence.
source_mask (Tensor): Source padding mask.
target_ids (Tensor): Target sentence.
target_mask (Tensor): Target padding mask.
Returns:
Tensor, prediction_scores, seq_relationship_score.
"""
_, decoder_outputs, embedding_table = self.transformer(source_ids, source_mask, target_ids, target_mask)
prediction_scores = self.projection(decoder_outputs,
embedding_table)
return prediction_scores
在MindSpore中还提供了封装交叉熵损失函数的网络TransformerNetworkWithLoss,以及封装优化器及反向训练的网络TransformerTrainOneStepWithLossScaleCell,详细请参考上文所提供代码仓地址。
2) 使用MindSpore训练MASS网络
在训练开始之前,需要配置必要的环境设置信息:
from mindspore import context
context.set_context(mode=context.GRAPH_MODE, device_target="Ascend", reserve_class_name_in_scope=False, device_id=device_id)
Mindspore支持多种数据集格式,可以调用dataset接口加载数据并进行一系列数据增强处理,同时可以配置循环下沉次数及数据集训练重复次数,这里以TFRecord格式为例:
import mindspore.dataset.engine as de
ds = de.TFRecordDataset(input_files, columns_list=["source_eos_ids", "source_eos_mask", "target_sos_ids", "target_sos_mask", "target_eos_ids", "target_eos_mask"], shuffle=shuffle, num_shards=rank_size, shard_id=rank_id, shard_equal_rows=True, num_parallel_workers=8)
ori_dataset_size = ds.get_dataset_size()
print(f" | Dataset size: {ori_dataset_size}.")
repeat_count = epoch_count
if sink_mode:
ds.set_dataset_size(sink_step * batch_size)
repeat_count = epoch_count * ori_dataset_size // ds.get_dataset_size()
type_cast_op = deC.TypeCast(mstype.int32)
ds = ds.map(input_columns=" source_eos_ids", operations=type_cast_op)
ds = ds.map(input_columns=" source_eos_mask", operations=type_cast_op)
ds = ds.map(input_columns=" target_sos_ids", operations=type_cast_op)
ds = ds.map(input_columns=" target_sos_mask", operations=type_cast_op)
ds = ds.map(input_columns=" target_eos_ids", operations=type_cast_op)
ds = ds.map(input_columns=" target_eos_mask", operations=type_cast_op)
ds = ds.batch(batch_size, drop_remainder=True)
ds = ds.repeat(repeat_count)
接下来,定义损失函数,优化器即可开始训练,如需使用loss scale功能,可以通过调用DynamicLossScaleManager接口实现。这里我们使用交叉熵作为损失函数,选择adam优化器,使用TransformerNetworkWithLoss和TransformerTrainOneStepWithLossScaleCell接口封装网络并构建Model模型,通过Model.train接口进行训练,训练结果可以通过MindSpore的回调接口ModelCheckpoint保存计算结果。我们还提供了参数配置接口TransformerConfig,可以读取配置文件config.json中的网络配置参数。
from mindspore.nn.optim import Adam
from mindspore.train.model import Model
from mindspore.train.callback import CheckpointConfig
from config import TransformerConfig
from src.transformer import TransformerNetworkWithLoss, TransformerTrainOneStepWithLossScaleCell
config = TransformerConfig.from_json_file(“config.json”)
net_with_loss = TransformerNetworkWithLoss(config, is_training=True)
net_with_loss.init_parameters_data()
lr = Tensor(polynomial_decay_scheduler(lr=config.lr,
min_lr=config.min_lr,
decay_steps=config.decay_steps,
total_update_num=update_steps,
warmup_steps=config.warmup_steps,
power=config.poly_lr_scheduler_power),
dtype=mstype.float32)
optimizer = Adam(net_with_loss.trainable_params(), lr, beta1=0.9, beta2=0.98)
scale_manager = DynamicLossScaleManager(init_loss_scale=config.init_loss_scale, scale_factor=config.loss_scale_factor, scale_window=config.scale_window)
net_with_grads = TransformerTrainOneStepWithLossScaleCell(
network=net_with_loss,
optimizer=optimizer,
scale_update_cell=scale_manager.get_update_cell())
net_with_grads.set_train(True)
model = Model(net_with_grads)
loss_monitor = LossCallBack(config)
ckpt_config = CheckpointConfig(save_checkpoint_steps=config.save_ckpt_steps, keep_checkpoint_max=config.keep_ckpt_max)
ckpt_callback = ModelCheckpoint(prefix=config.ckpt_prefix, directory=os.path.join(config.ckpt_path, ‘ckpt_{}‘.format(os.getenv(‘DEVICE_ID‘))), config=ckpt_config)
callbacks = [loss_monitor, ckpt_callback]
model.train(epoch_size, pre_training_dataset, callbacks=callbacks, dataset_sink_mode=config.dataset_sink_mode)
3) MASS网络推理
训练完成之后,可以通过MindSpore中定义的load_checkpoint接口加载保存的checkpoint模型参数,通过TransformerInferModel构建MASS的推理网络模型,调用Model.predict接口完成推理。最后通过get_score接口可以计算推理评分。
import pickle
from mindspore.train import Model
from mindspore.train.serialization import load_checkpoint, load_param_into_net
from config import TransformerConfig
from .transformer_for_infer import TransformerInferModel
from src.utils import get_score
config = TransformerConfig(config.path)
tfm_model = TransformerInferModel(config=config, use_one_hot_embeddings=False)
tfm_model.init_parameters_data()
weights = load_infer_weights(checkpoint.path)
load_param_into_net(tfm_model, weights)
tfm_infer = TransformerInferCell(tfm_model)
model = Model(tfm_infer)
predictions = []
probs = []
source_sentences = []
target_sentences = []
for batch in dataset.create_dict_iterator():
source_sentences.append(batch["source_eos_ids"])
target_sentences.append(batch["target_eos_ids"])
source_ids = Tensor(batch["source_eos_ids"], mstype.int32)
source_mask = Tensor(batch["source_eos_mask"], mstype.int32)
start_time = time.time()
predicted_ids, entire_probs = model.predict(source_ids, source_mask)
print(f" | Batch size: {config.batch_size}, "
f"Time cost: {time.time() - start_time}.")
predictions.append(predicted_ids.asnumpy())
probs.append(entire_probs.asnumpy())
output = []
for inputs, ref, batch_out, batch_probs in zip(source_sentences,
target_sentences,
predictions,
probs):
for i in range(config.batch_size):
if batch_out.ndim == 3:
batch_out = batch_out[:, 0]
example = {"source": inputs[i].tolist(),
"target": ref[i].tolist(),
"prediction": batch_out[i].tolist(),
"prediction_prob": batch_probs[i].tolist()}
output.append(example)
score = get_score(output, vocab=args.vocab, metric=args.metric)
至此关于MASS的基本结构以及如何使用Mindspore进行MASS网络训练和推理已经介绍完毕,“纸上得来终觉浅”,不妨亲自动手尝试一下哦~

标签:mat update print 预训练模型 领域 介绍 zip ural init
原文地址:https://www.cnblogs.com/MindSpore/p/13366281.html