标签:时间段 gate 设置 wait csharp nbsp class nod 采集
本讲内容
我们选一个新的key来做讲解
count_netstat_wait_connections #TCP wait_connect数
这个key值不少我们熟悉的node_exporter挖掘而来
而是我们自定义并使用bash脚本+pushgateway的方式推送到 prometheus server采集
类型gauge
gauge类型的数据,属于随机变化的数值,并不像Counter那样是持续增长的
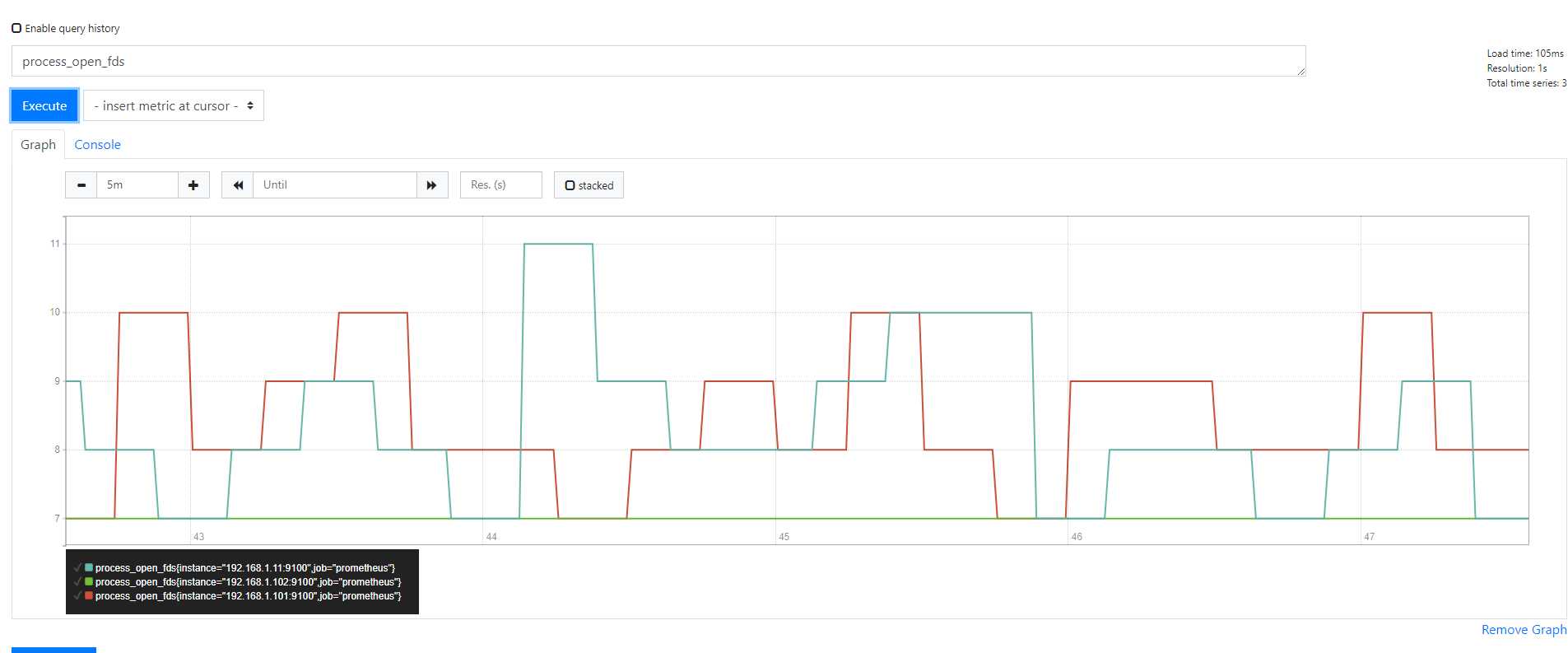
把一个key直接输入命令行之后得到的是最原始的数据输出
相对Counter数据gauge不需要任何increase() rate()之类的函数计算
直接输入以后就可以看到已经成型的有确实意义的曲线图,如下图
标签:来自于采集数据也可以自定义
例如上面数据的instance标签是指明备监控的服务器
可以在命令中使用标签进行进一步过滤例如
process_open_fds{instance="192.168.1.101:9100"}
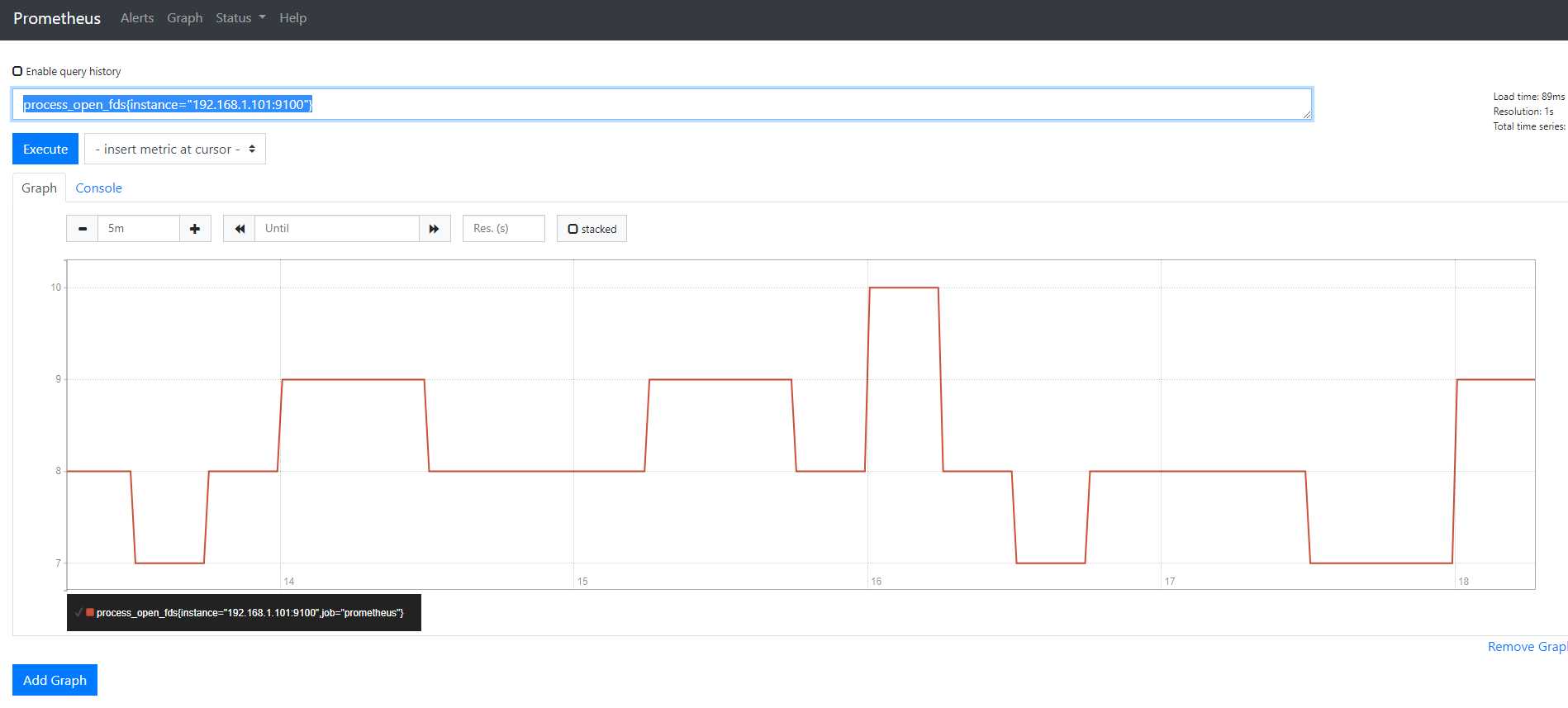
查询多个有多个结果的时候也可以使用鼠标点击进行过滤
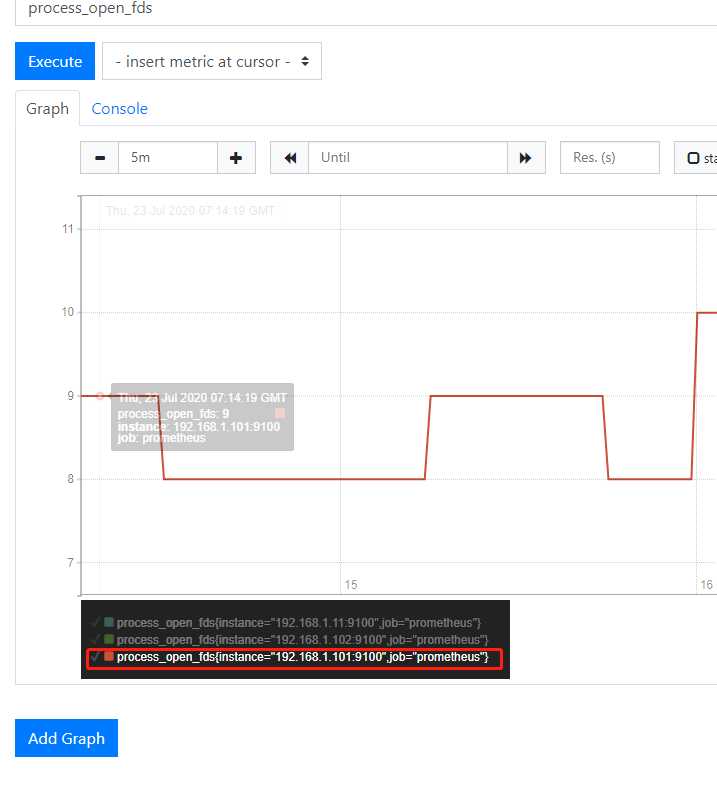
过滤后就只显示某一台服务器的信息
过滤除了精确匹配 还有 模糊匹配
例如
process_open_fds{instance=~"192.168.1.*"}
模糊匹配=~ 模糊不匹配!~
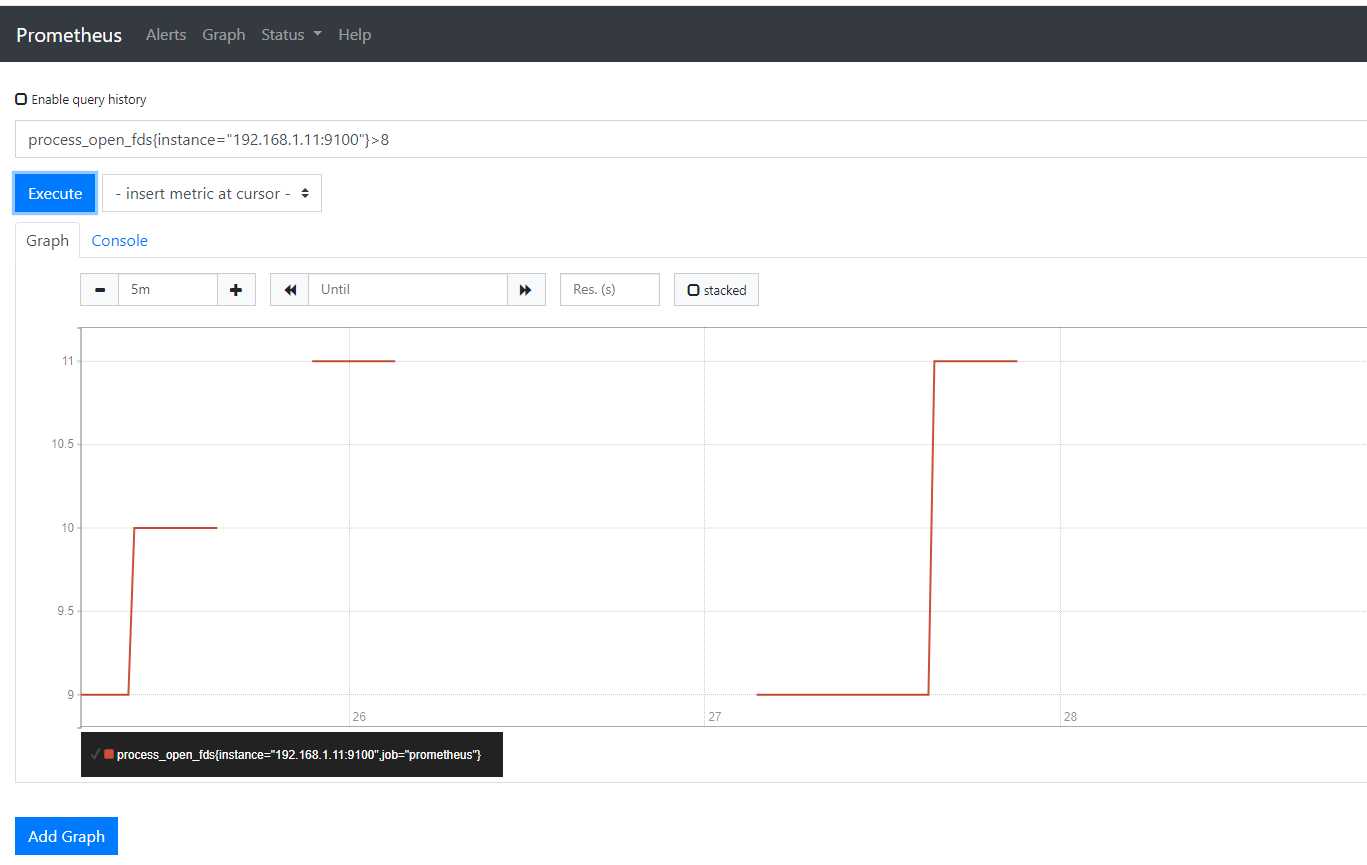
标签过滤之后对数值过滤
process_open_fds{instance="192.168.1.11:9100"}>8
显示的就是一些片段了
rate函数可以说是prometheus提供的最重要的喊
rate函数是专门搭配Counter类型数据使用的函数
它的功能是安装设置一个时间段,取Counter在这个时间段中平均每秒的增量
举例说明
网络流量key
node_network_receive_bytes
获取一分钟内平均每秒的增量
rate(node_network_receive_bytes [1m])
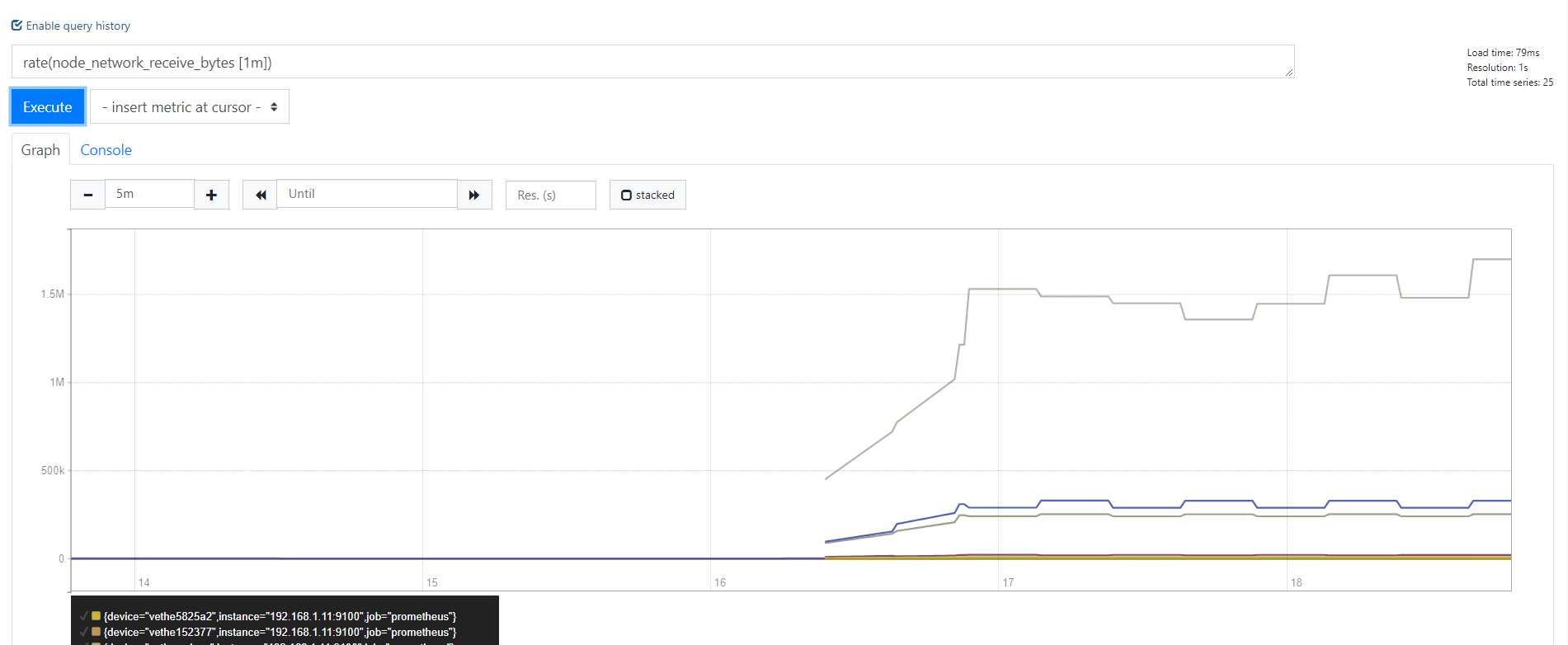
注意:所以说 我们以后在使?任何counter数据类型的时候,永远记 得 别的先不做 先给它加上?个 rate() 或者 increase()
接下来我们把rate()做的事情更加细化来解释一下
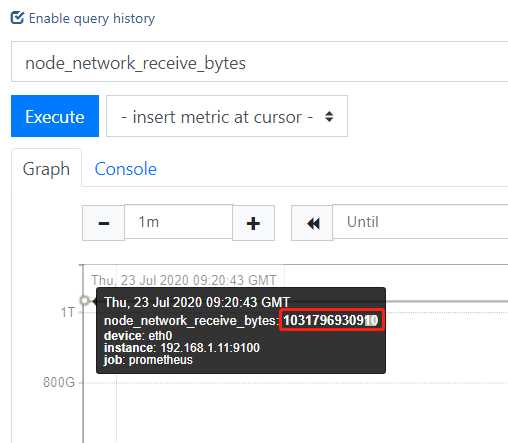
例如从09:20:43-09:21:43
累积量从1031796930910到了1031872038733
一分钟内增加的1000bytes(假设)
从9:21-9:26
五分钟增加了5000bytes(假设)
加入rate(. [1m])之后
会把1000bytes除以1m*60秒 =~16bytes
就是这样计算出在这一分钟内平均每秒增加16bytes
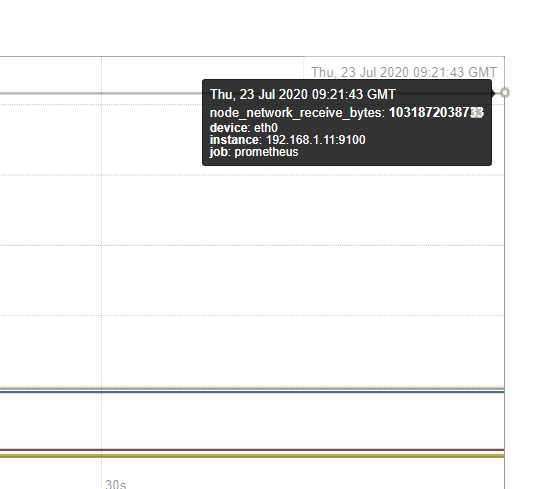
修改把1m=》5m
这样就把5分钟内的增量除以5m*60秒
5分钟的增量加入是5000那么除以300以后还是约等于16bytes/s
感觉好像一模一样
对比1m和5m
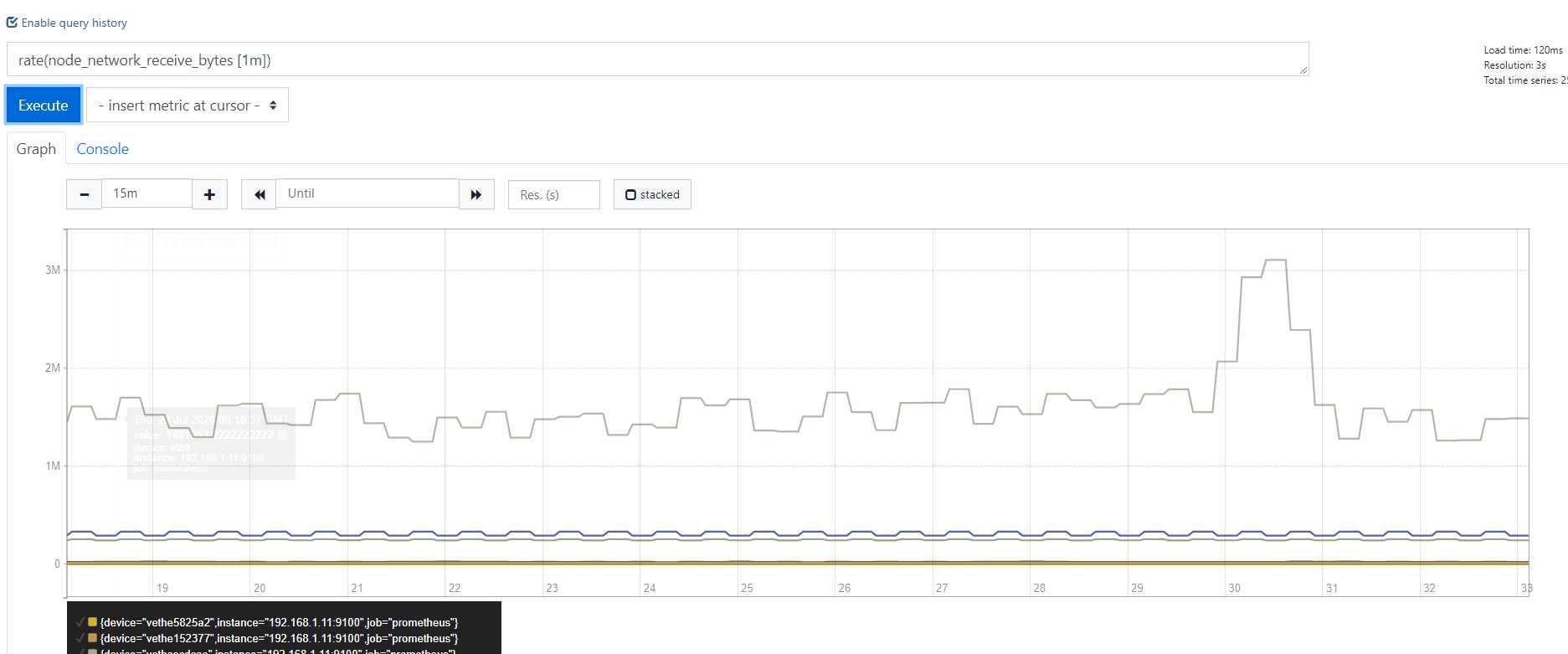
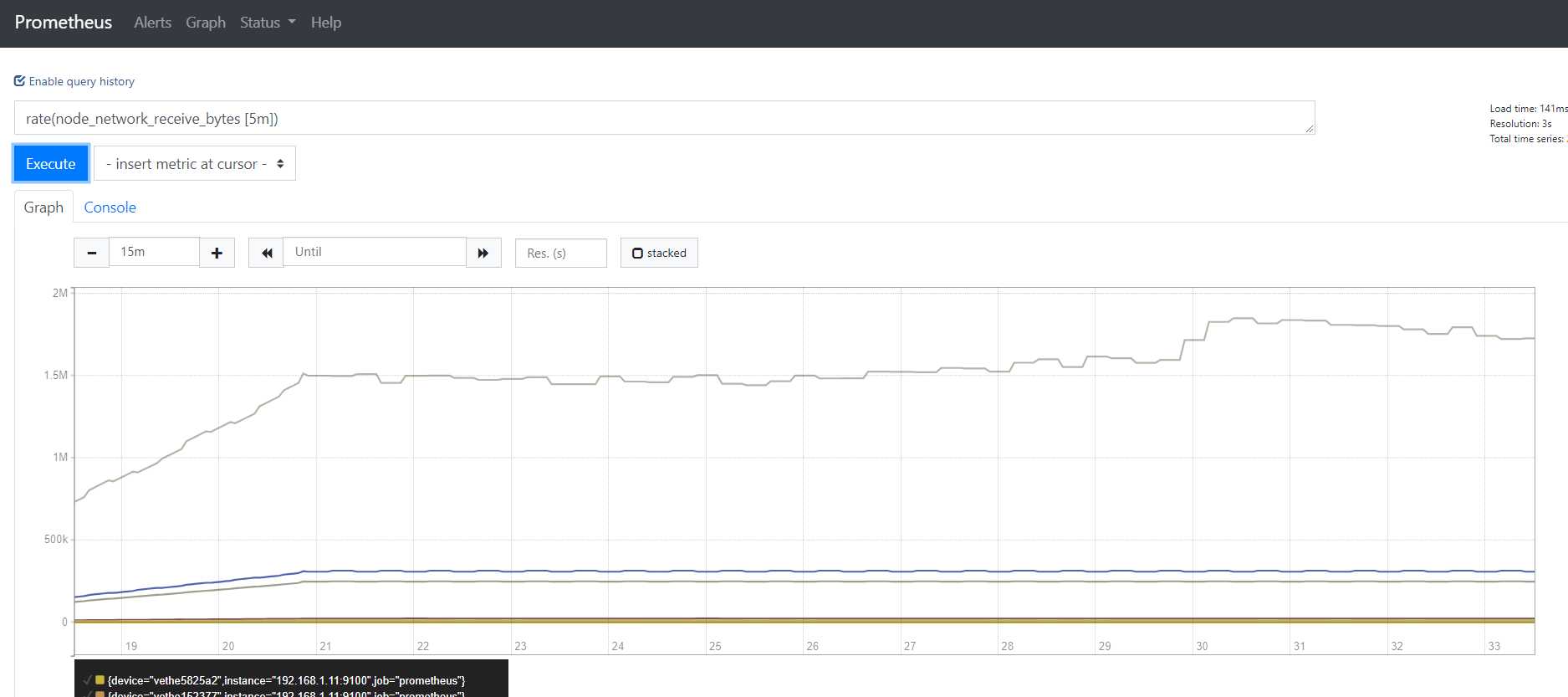
明显1分钟的曲线比5分钟的曲线平缓
虽然平均每秒的速度都是16bytes
如果 我们按照 rate(1m)这样来取,那么是取1分钟内的增量 除 以秒数
如果 我们按照 rate(5m)这样来取,那么是取5分钟内的增量 除 以秒数
?这种取法 是?种平均的取法 ?且是假设的
刚才我们说 counter在 ?分钟 5分钟 之内的增量 1000 和 5000 其实是?种假设的理想状态
事实上 ?产环境 ?络数据接收量 可不是这么平均的 有可能在 第?分钟内 增加了 1000 , 到 第?分钟 就变成增加 了2500 ….
所以 rate(1m) 这样的取值?法 ?起 rate(5m) ,因为它取的时 间段短,所以 任何某?瞬间的凸起或者降低 在成图的时候 会体现的更细致 更敏感
? rate(5m) 把整个5分钟内的 都?起平均了,那么当发?瞬时 凸起的时候 ,会显得图平缓了?些 (因为 取的时间段长 把 波峰波? 都给平均消下去了)
那么我们再放??些 看看 rate(20m) 会怎么样
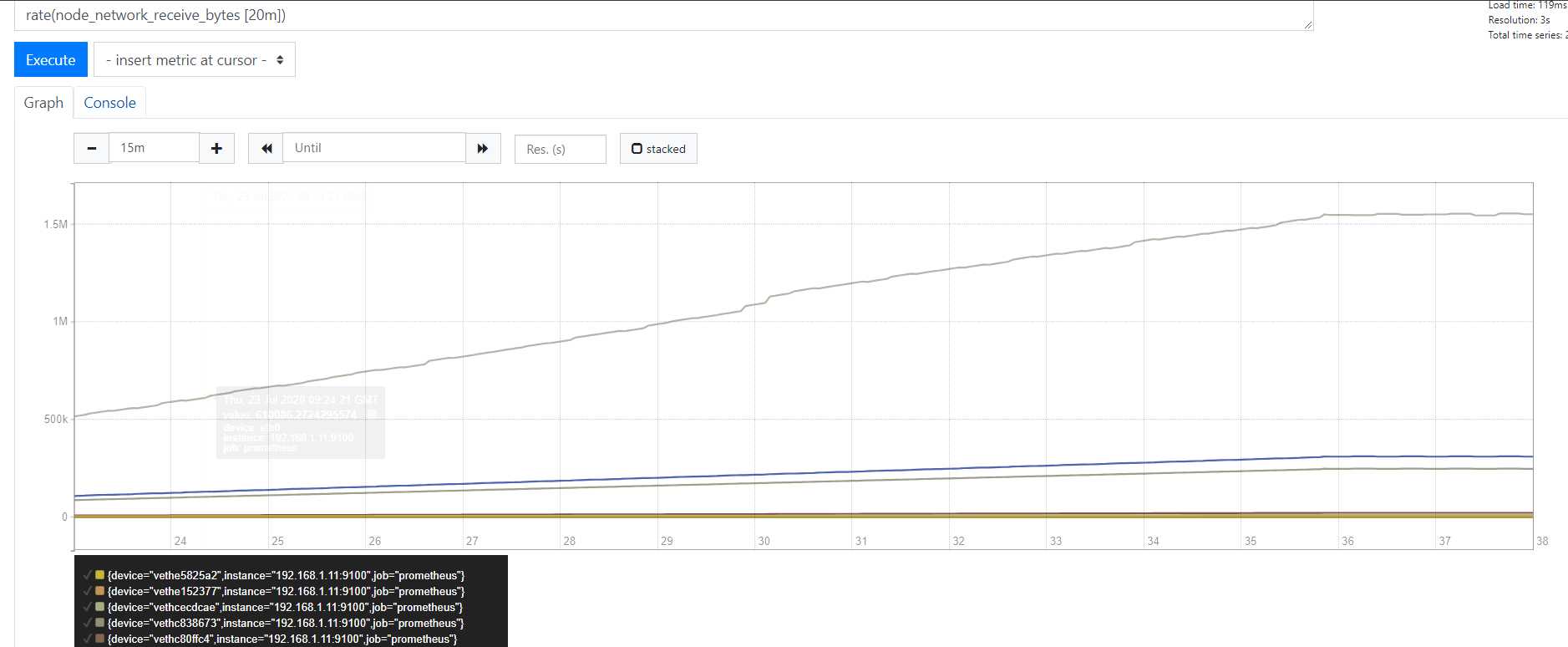
更加平缓了
在我们的?作中 取1m 还是取5m 这个取决于 我们对于监控数据的敏感性程度来挑选
increase 函数 其实和rate() 的概念及使??法 ?常相似
rate(1m) 是取?段时间增量的平均每秒数量 increase(1m) 则是 取?段时间增量的总量
对比
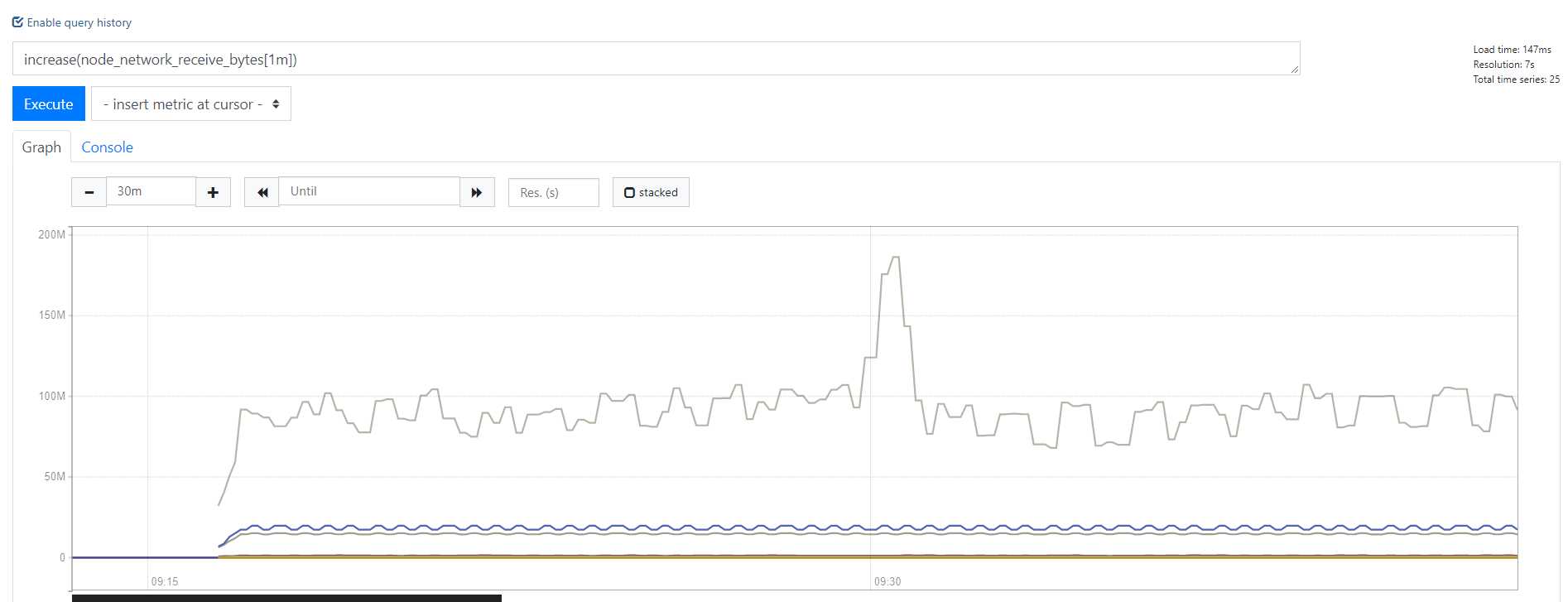
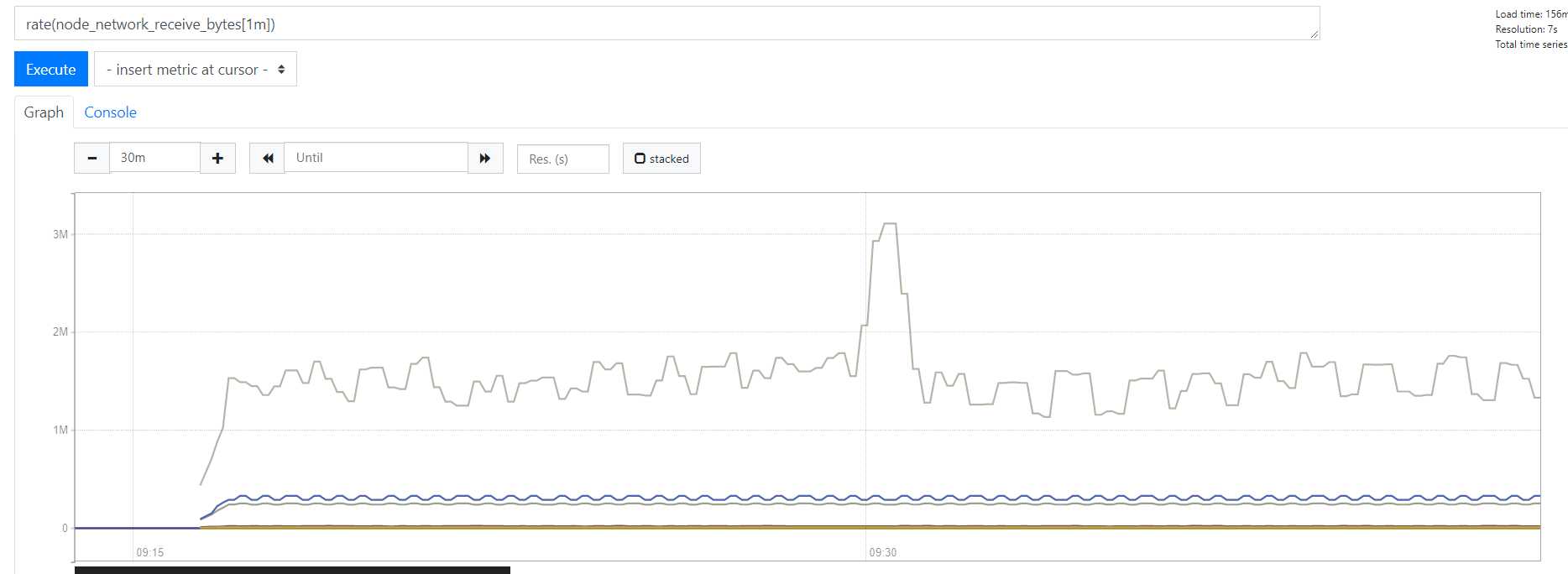
图形形状基本一样,但是y轴的数值是不一样的
从这两个图 我们可以看到 其实曲线的?势 基本是?样的 但是 显?出来的数量级bytes 可不?样 3106868.4 * 60 = 186412104 (发现) 正好是 60倍 也就很好理理解了了,increase() 是不不会取?一秒的平均值的
标签:时间段 gate 设置 wait csharp nbsp class nod 采集
原文地址:https://www.cnblogs.com/minseo/p/13367692.html