标签:数据 注意 返回值 val 20px 清空 上进 primary 内容

初始化环境: -- 创建商品表 create table products( pid int primary key auto_increment, pname varchar(20), price double, pnum int, cno int, pdate timestamp ); insert into products values (null,‘泰国大榴莲‘,98,12,1,null); insert into products values (null,‘新疆大枣‘,38,123,1,null); insert into products values (null,‘新疆切糕‘,68,50,2,null); insert into products values (null,‘十三香‘,10,200,3,null); insert into products values (null,‘老干妈‘,20,180,3,null); insert into products values (null,‘豌豆黄‘,20,120,2,null); 练习: 简单查询: 练习: 1.查询所有的商品 select * from products; 2.查询商品名和商品价格. -- 查看指定的字段 -- 格式: select 字段名1,字段名2 from 表名 select pname,price from products; 3.查询所有商品都有那些价格. -- 去重操作 distinct -- 格式: select distinct 字段名,字段名2 from 表名 select price from products; select distinct price from products; 4.将所有商品的价格+10元进行显示.(别名) -- 可以在查询的结果之上进行运算,不影响数据库中的值 -- 给列起别名 格式: 字段名 [as] 别名 select price+10 from products; select price+10 新价格 from products; select price+10 ‘新价格‘ from products; select price+10 新 价 格 from products;-- 错误 select price+10 ‘新 价 格‘ from products; select price+10 `新 价 格` from products; 条件查询: 练习: 1.查询商品名称为十三香的商品所有信息: select * from products where pname = ‘十三香‘; 2.查询商品价格>60元的所有的商品信息: select * from products where price>60; 3.查询商品名称中包含”新”的商品 -- 模糊匹配 -- 格式: 字段名 like "匹配规则"; -- 匹配内容 % "龙" 值为龙 "%龙" 值以"龙"结尾 "龙%" 值以"龙"开头 "%龙%" 值包含"龙" -- 匹配个数 "__" 占两个位置 select * from products where pname like "%新%"; 4.查询价格为38,68,98的商品 select * from products where price = 38 or price = 68 or price=98; select * from products where price in(38,68,98); where后的条件写法: * > ,<,=,>=,<=,<>,!= * like 使用占位符 _ 和 % _代表一个字符 %代表任意个字符. * select * from product where pname like ‘%新%‘; * in在某个范围中获得值. * select * from product where pid in (2,5,8); * between 较小值 and 较大值 select * from products where price between 50 and 70; 排序查询: 1.查询所有的商品,按价格进行排序.(asc-升序,desc-降序) select * from products order by price desc; 2.查询名称有新的商品的信息并且按价格降序排序. select * from products where pname like ‘%新%‘ order by price desc; 聚合函数: 对一列进行计算 返回值是一个,忽略null值 * sum(),avg(),max(),min(),count(); 1.获得所有商品的价格的总和: select sum(price) from products; 2.获得商品表中价格的平均数: select avg(price) from products; -- round(值,保留小数位) select round(avg(price),2) from products; 3.获得商品表中有多少条记录: select count(*) from products; 分组:使用group by 1.根据cno字段分组,分组后统计商品的个数. select cno,count(*) from products group by cno; 2.根据cno分组,分组统计每组商品的总数量,并且总数量> 200; select cno,sum(pnum) from products group by cno; select cno,sum(pnum) from products group by cno having sum(pnum)>200; 注意: where和having区别: 1.where 是对分组前的数据进行过滤 ;having 是对分组后的数据进行过滤 2.where 后面不能使用聚合函数,having可以

作用:为了保证数据的有效性和完整性
mysql常用的约束:主键约束(primary key) 唯一约束(unique) 非空约束(not null) 外键约束(foreign key)
主键约束:被修饰过的字段唯一非空
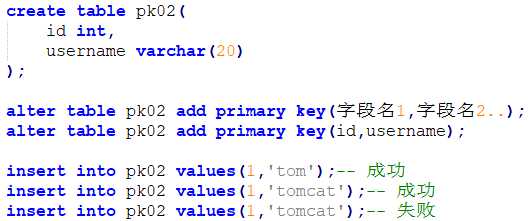
注意:一张表只能由一个主键,这个主键可以包含多个字段
方式1:建表的同时添加约束 格式:字段名称 字段类型 primary key
方式2:建表的同时在约束区域添加约束
所有字段声明完成后就是约束区域 格式:primary key(字段1,字段2)

方式3:建表后,通过修改表结构添加约束
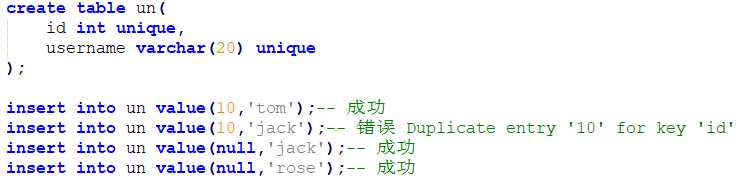
唯一约束:
被修饰过的字段唯一,对null不起作用
方式1:建表的同时添加约束 格式: 字段名称 字段类型 unique
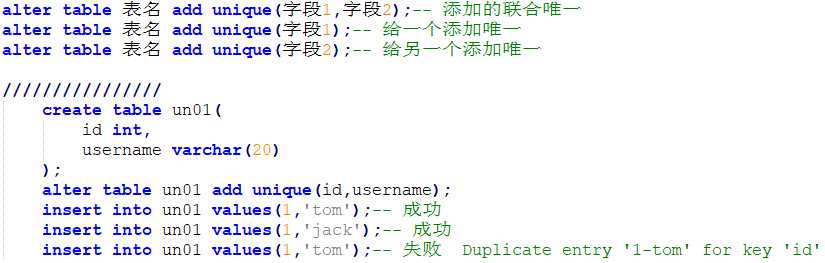
方式2:建表的同时在约束区域添加约束
所有的字段声名完成后就是约束区域:unique(字段1,字段2)
方式3:建表之后,通过修改表结构添加约束
非空约束:
特点:被修饰过的字段非空
方式:

truncate 清空表:
格式:
truncate 表名;干掉表,重新创建一张新表
和delete from 区别
delete属于DML语句 truncate属于DDL语句
delete逐条删除 truncate干掉表,重新创建一张空表
auto_increment 自增:
要求:1.被修饰的字段累心支持自增。一般为int
2.被修饰的字段必须是一个key 一般是primary key

标签:数据 注意 返回值 val 20px 清空 上进 primary 内容
原文地址:https://www.cnblogs.com/yisennnn/p/13373224.html
