标签:数据 image 执行 缓冲 不同 允许 对比 设计者 处理器
TSO Total Store Order。
TSO 就是在SC的基础上放松write-to-read的条件,即允许先写后读的重排序,将写操作延迟,让之后的读操作先执行(当然目前的讨论都是基于不同地址的,相同地址存在数据依赖性一般不允许重排序,但也有允许的模型)。除此之外,TSO的其他条件与SC完全相同,因此是一个非常严格的内存模型。
形式定义(与SC模型的形式定义对比着看):
(1)
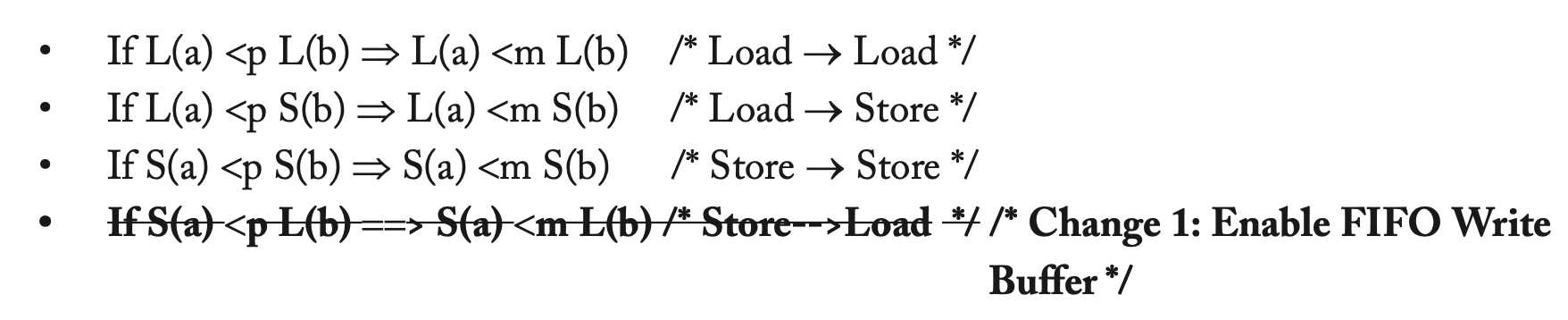
(2)
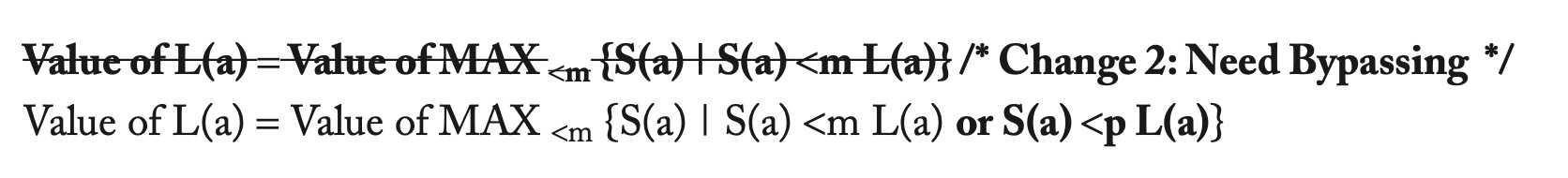
x86使用的内存模型几乎与TSO模型完全一样(由于x86的硬件设计者并没有给出官方的准确的定义,但相当多的证据表明二者的行为完全一致)。
理论上,该重排序的行为其实就是硬件上采用了store buffer。
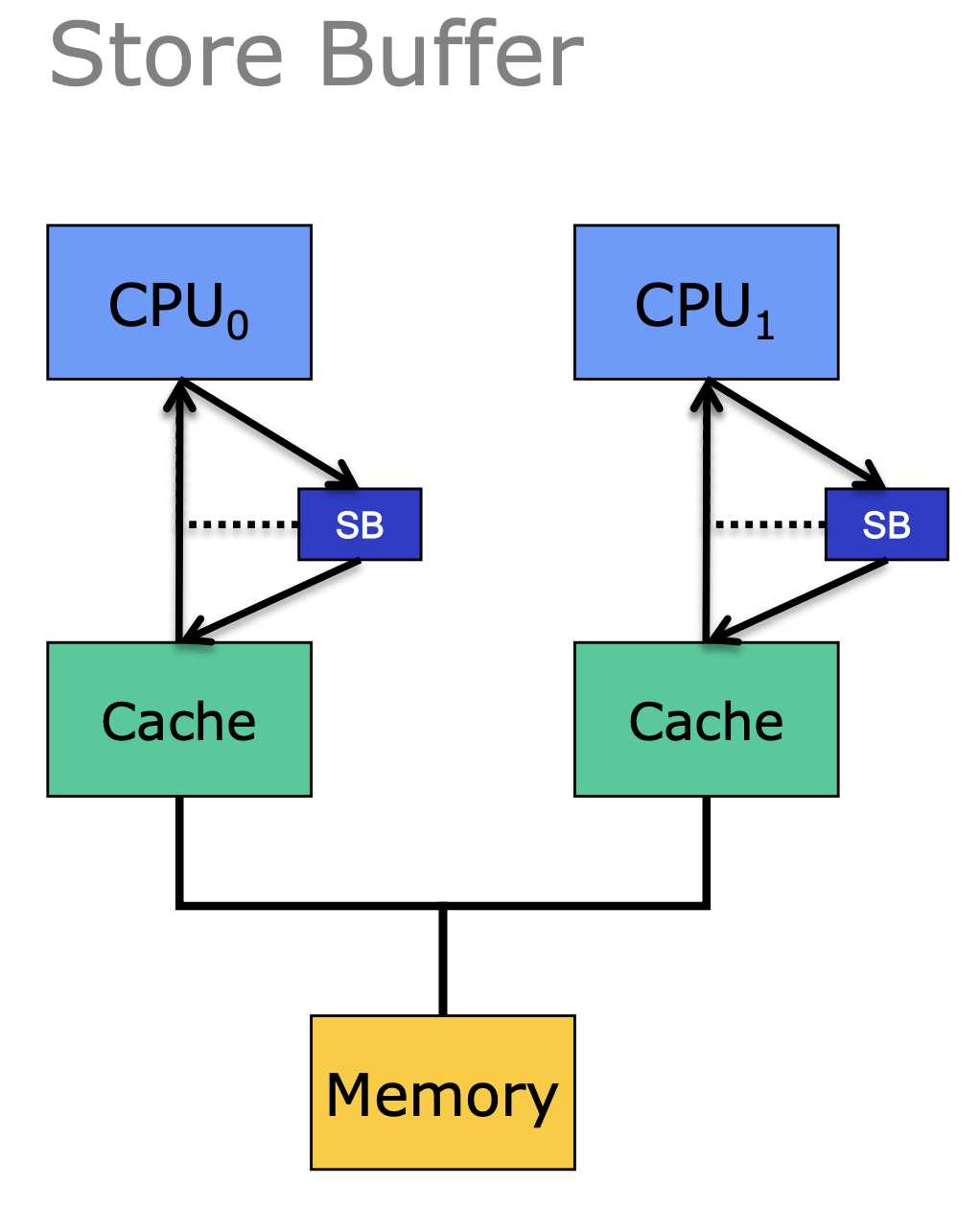
特点:
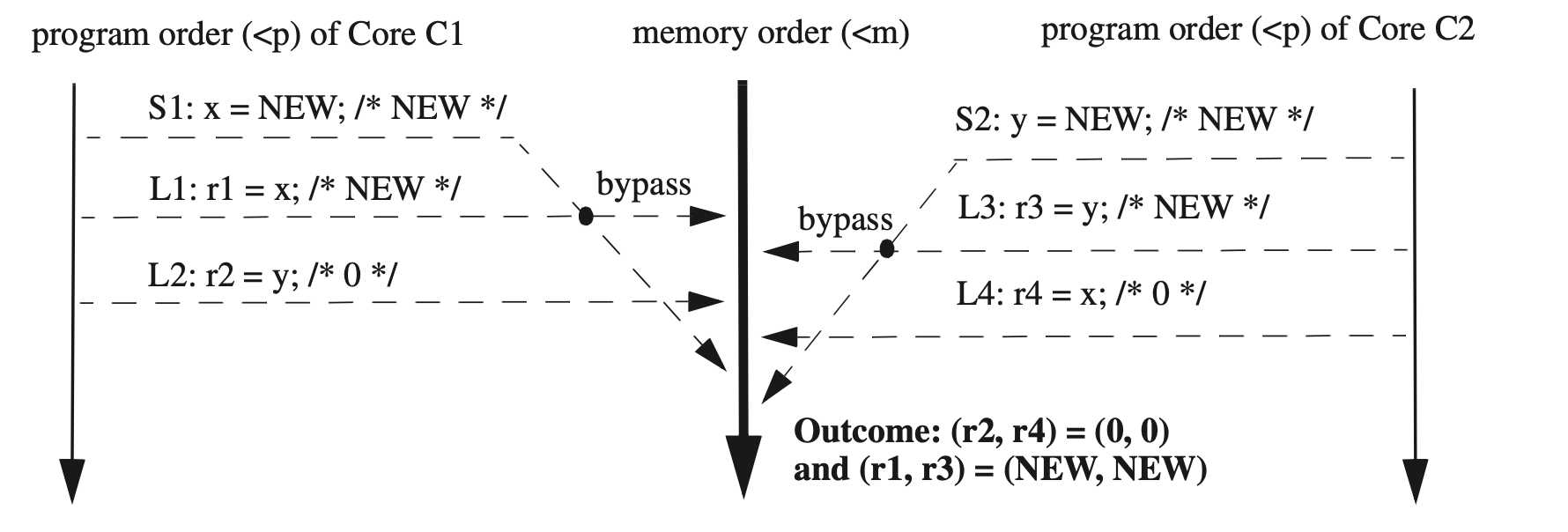
TSO会让某个处理器立即可见它自己buffer中的写值,即使它还未对其他所有处理器可见。
例:如下图所示中的S1和L1,因为重排序,S1被写入write buffer,在很后面才被所有处理器可见,但是由于TSO的设计,和S1同处理器的L1可以读取x的值,S2和L3类似。
TSO中并不常使用FENCE(或者说内存屏障),因为对于大多数程序来说TSO都能保证正确执行。
以下是FENCE的形式定义:
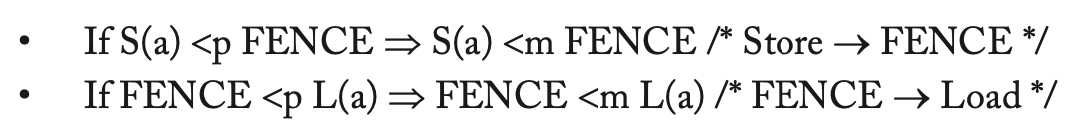
TSO模型是在SC模型上放宽了write-read的重排序限制,并且其机制等价于采用了一个stroe buffer。TSO允许某个处理器立即可见他自己的写值,即使它还在buffer中,未对其他所有处理器可见。
标签:数据 image 执行 缓冲 不同 允许 对比 设计者 处理器
原文地址:https://www.cnblogs.com/chenzhongjie/p/13375052.html