标签:优化 维护 出现 策略 数据包 时间类 ack 图片 生产者
实例:
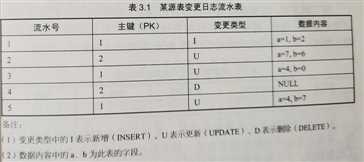
下图为源业务系统中某表变更日志流水表。其含义:存在5条变更日志,其中主键为 1 的记录有 3 条变更日志,主键为 2 的记录有 2 条变更日志。
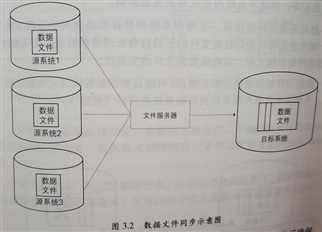
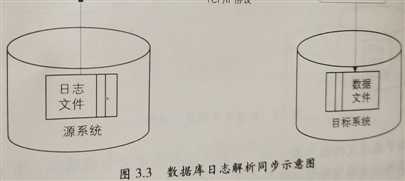
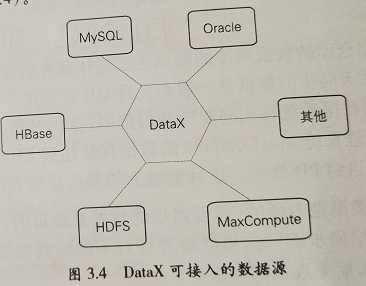
大数据:数据同步
原文地址:https://www.cnblogs.com/volcao/p/13378431.html