标签:加速 batch tensor 字符 维基 dict multi asi utils
作者|DR. VAIBHAV KUMAR
编译|VK
来源|Analytics In Diamag
文本分类是自然语言处理的重要应用之一。在机器学习中有多种方法可以对文本进行分类。但是这些分类技术大多需要大量的预处理和大量的计算资源。在这篇文章中,我们使用PyTorch来进行多类文本分类,因为它有如下优点:
在本文中,我们将使用TorchText演示多类文本分类,TorchText是PyTorch中一个强大的自然语言处理库。
对于这种分类,将使用由EmbeddingBag层和线性层组成的模型。EmbeddingBag通过计算嵌入的平均值来处理长度可变的文本条目。
这个模型将在DBpedia数据集上进行训练,其中文本属于14个类。训练成功后,模型将预测输入文本的类标签。
DBpedia是自然语言处理领域中流行的基准数据集。它包含14个类别的文本,如公司、教育机构、艺术家、电影等。
它实际上是从维基百科项目创建的信息中提取的结构化内容集。TorchText提供的DBpedia数据集有63000个属于14个类的文本实例。它包括5600个训练实例和70000个测试实例。
首先,我们需要安装最新版本的TorchText。
!pip install torchtext==0.4
之后,我们将导入所有必需的库。
import torch
import torchtext
from torchtext.datasets import text_classification
import os
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
import time
from torch.utils.data.dataset import random_split
import re
from torchtext.data.utils import ngrams_iterator
from torchtext.data.utils import get_tokenizer
在下一步中,我们将定义ngrams和batch大小。ngrams特征用于捕获有关本地语序的重要信息。
我们使用bigram,数据集中的示例文本将是单个单词加上bigrams字符串的列表。
NGRAMS = 2
BATCH_SIZE = 16
现在,我们将读取TorchText提供的DBpedia数据集。
if not os.path.isdir(‘./.data‘):
os.mkdir(‘./.data‘)
train_dataset, test_dataset = text_classification.DATASETS[‘DBpedia‘](
root=‘./.data‘, ngrams=NGRAMS, vocab=None)
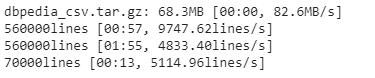
下载数据集后,我们将验证下载数据集的长度和标签数量。
print(len(train_dataset))
print(len(test_dataset))
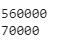
print(len(train_dataset.get_labels()))
print(len(test_dataset.get_labels()))

我们将使用CUDA架构来加速运行和执行。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
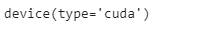
在下一步中,我们将定义分类的模型。
class TextSentiment(nn.Module):
def __init__(self, vocab_size, embed_dim, num_class):
super().__init__()
self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=True)
self.fc = nn.Linear(embed_dim, num_class)
self.init_weights()
def init_weights(self):
initrange = 0.5
self.embedding.weight.data.uniform_(-initrange, initrange)
self.fc.weight.data.uniform_(-initrange, initrange)
self.fc.bias.data.zero_()
def forward(self, text, offsets):
embedded = self.embedding(text, offsets)
return self.fc(embedded)
print(model)

现在,我们将初始化超参数并定义函数以生成训练batch。
VOCAB_SIZE = len(train_dataset.get_vocab())
EMBED_DIM = 32
NUN_CLASS = len(train_dataset.get_labels())
model = TextSentiment(VOCAB_SIZE, EMBED_DIM, NUN_CLASS).to(device)
def generate_batch(batch):
label = torch.tensor([entry[0] for entry in batch])
text = [entry[1] for entry in batch]
offsets = [0] + [len(entry) for entry in text]
offsets = torch.tensor(offsets[:-1]).cumsum(dim=0)
text = torch.cat(text)
return text, offsets, label
在下一步中,我们将定义用于训练和测试模型的函数。
def train_func(sub_train_):
# 训练模型
train_loss = 0
train_acc = 0
data = DataLoader(sub_train_, batch_size=BATCH_SIZE, shuffle=True,
collate_fn=generate_batch)
for i, (text, offsets, cls) in enumerate(data):
optimizer.zero_grad()
text, offsets, cls = text.to(device), offsets.to(device), cls.to(device)
output = model(text, offsets)
loss = criterion(output, cls)
train_loss += loss.item()
loss.backward()
optimizer.step()
train_acc += (output.argmax(1) == cls).sum().item()
# 调整学习率
scheduler.step()
return train_loss / len(sub_train_), train_acc / len(sub_train_)
def test(data_):
loss = 0
acc = 0
data = DataLoader(data_, batch_size=BATCH_SIZE, collate_fn=generate_batch)
for text, offsets, cls in data:
text, offsets, cls = text.to(device), offsets.to(device), cls.to(device)
with torch.no_grad():
output = model(text, offsets)
loss = criterion(output, cls)
loss += loss.item()
acc += (output.argmax(1) == cls).sum().item()
return loss / len(data_), acc / len(data_)
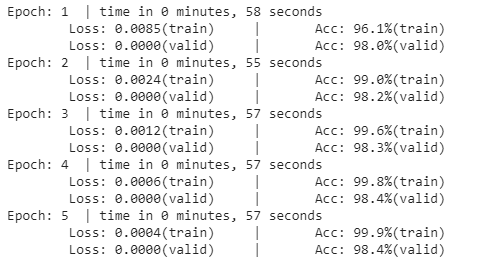
我们将用5个epoch训练模型。
N_EPOCHS = 5
min_valid_loss = float(‘inf‘)
criterion = torch.nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=4.0)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1, gamma=0.9)
train_len = int(len(train_dataset) * 0.95)
sub_train_, sub_valid_ = random_split(train_dataset, [train_len, len(train_dataset) - train_len])
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss, train_acc = train_func(sub_train_)
valid_loss, valid_acc = test(sub_valid_)
secs = int(time.time() - start_time)
mins = secs / 60
secs = secs % 60
print(‘Epoch: %d‘ %(epoch + 1), " | time in %d minutes, %d seconds" %(mins, secs))
print(f‘\tLoss: {train_loss:.4f}(train)\t|\tAcc: {train_acc * 100:.1f}%(train)‘)
print(f‘\tLoss: {valid_loss:.4f}(valid)\t|\tAcc: {valid_acc * 100:.1f}%(valid)‘)
下一步,我们将在测试数据集上测试我们的模型,并检查模型的准确性。
print(‘Checking the results of test dataset...‘)
test_loss, test_acc = test(test_dataset)
print(f‘\tLoss: {test_loss:.4f}(test)\t|\tAcc: {test_acc * 100:.1f}%(test)‘)

现在,我们将在单个新闻文本字符串上测试我们的模型,并预测给定新闻文本的类标签。
DBpedia_label = {0: ‘Company‘,
1: ‘EducationalInstitution‘,
2: ‘Artist‘,
3: ‘Athlete‘,
4: ‘OfficeHolder‘,
5: ‘MeanOfTransportation‘,
6: ‘Building‘,
7: ‘NaturalPlace‘,
8: ‘Village‘,
9: ‘Animal‘,
10: ‘Plant‘,
11: ‘Album‘,
12: ‘Film‘,
13: ‘WrittenWork‘}
def predict(text, model, vocab, ngrams):
tokenizer = get_tokenizer("basic_english")
with torch.no_grad():
text = torch.tensor([vocab[token]
for token in ngrams_iterator(tokenizer(text), ngrams)])
output = model(text, torch.tensor([0]))
return output.argmax(1).item() + 1
vocab = train_dataset.get_vocab()
model = model.to("cpu")
现在,我们将从测试数据中随机抽取一些文本并检查预测的类标签。
第一个预测:
ex_text_str = "Brekke Church (Norwegian: Brekke kyrkje) is a parish church in Gulen Municipality in Sogn og Fjordane county, Norway. It is located in the village of Brekke. The church is part of the Brekke parish in the Nordhordland deanery in the Diocese of Bj??rgvin. The white, wooden church, which has 390 seats, was consecrated on 19 November 1862 by the local Dean Thomas Erichsen. The architect Christian Henrik Grosch made the designs for the church, which is the third church on the site."
print("This is a %s news" %DBpedia_label[predict(ex_text_str, model, vocab, 2)])

第二个预测:
ex_text_str2 = "Cerithiella superba is a species of very small sea snail, a marine gastropod mollusk in the family Newtoniellidae. This species is known from European waters. It was described by Thiele, 1912."
print("This text belongs to %s class" %DBpedia_label[predict(ex_text_str2, model, vocab, 2)])

第三个预测:
ex_text_str3 = " Nithari is a village in the western part of the state of Uttar Pradesh India bordering on New Delhi. Nithari forms part of the New Okhla Industrial Development Authority‘s planned industrial city Noida falling in Sector 31. Nithari made international news headlines in December 2006 when the skeletons of a number of apparently murdered women and children were unearthed in the village."
print("This text belongs to %s class" %DBpedia_label[predict(ex_text_str3, model, vocab, 2)])

因此,通过这种方式,我们使用TorchText实现了多类文本分类。
这是一种简单易行的文本分类方法,使用这个PyTorch库只需很少的预处理量。在5600个训练实例上训练模型只花了不到5分钟。
通过将ngram从2更改为3来重新运行这些代码并查看结果是否有改进。同样的实现也可以在TorchText提供的其他数据集上实现。
参考文献:
原文链接:https://analyticsindiamag.com/multi-class-text-classification-in-pytorch-using-torchtext/
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
标签:加速 batch tensor 字符 维基 dict multi asi utils
原文地址:https://www.cnblogs.com/panchuangai/p/13384742.html