标签:将不 art add 数据类型 block 数据区 meta 不同的 top
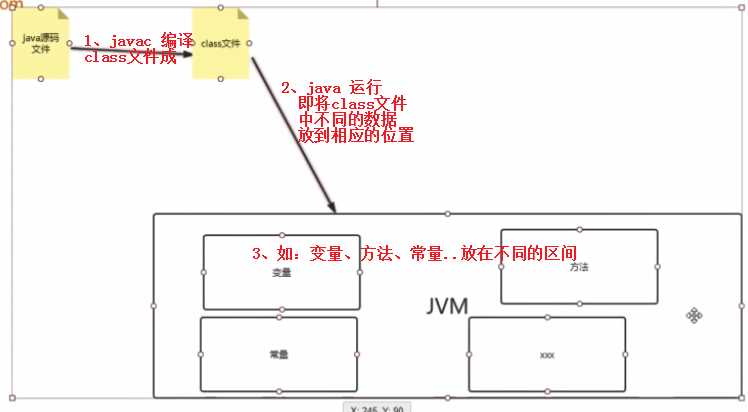
? javac 指令:编译java文件生成class文件
? java指令:运行class文件即将数据放到jvm中
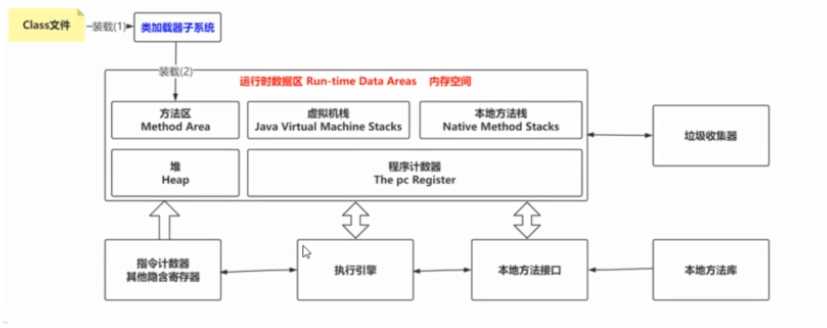
? class文件运行,后将不同的数据放到jvm中不同的位置这就是运行时数据区的由来。
有对象,常量、静态变量、普通成员变量、方法、局部变量、父类,XXX
怎么划分?为什么要这样划分?
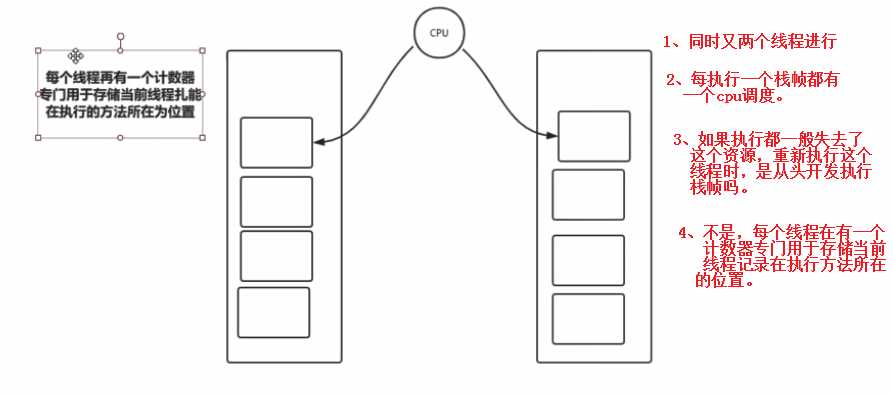
1、The pc Register
<u>4、计数器(存储当前线程执行方法的记录,下次接着下去,不用从头开始。)</u>
2、java Virtual Machine Stacks
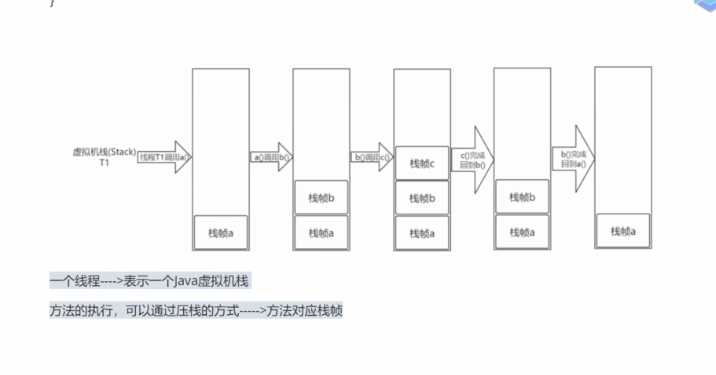
? 3、java虚拟机栈:
一个线程-- > 表示一个java虚拟机栈。
方法的执行,可以通过压栈的方式 --> 方法对应栈帧,方法中:返回地址、局部变量、操作数
3、Heap
1、堆:存储对象【包括普通成员变量】/数组 如:new Person() class
4、Method Area
2、方法区:类的信息【创建时间,元数据信息】、常量、静态变量、即时编译器编译之后的代码
堆和方法区都是线程共享,由于其他线程共享也就是说是线程不安全。
5、Run-time constant pool
? 6、属于方法区的一部分
6、Native Method Stacks
? 5、如果不是Native(本地)方法,那就是用来存储运行到那个方法的位置。
jvm整体图:
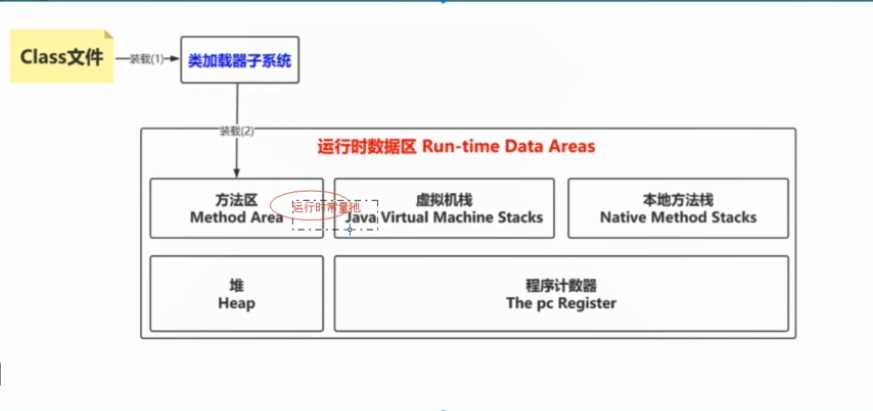
方法区,包含了运行时常量池
Method Area 方法区
? JDK1.7 之前 ---> Perm Space 永久代
? JDK1.8 之后 --> MetaSpace 元空间
/*java文件的方法*/
public static int calc(int op1,int op2) {
op1=3;
int result =op1+op2;
return result;
}
/*生成的class文件*/
public static int calc(int,int);
Code:
0: iconst_3
1: istore_0 # 3这个数值从操作数栈中弹出来
2:iload_0
3: iload_1
4: iadd
5: istore_2
6: iload_2
7: ireturn
? 垃圾回收
? 垃圾判断:
? 垃圾回收算法:复制 标记-整理
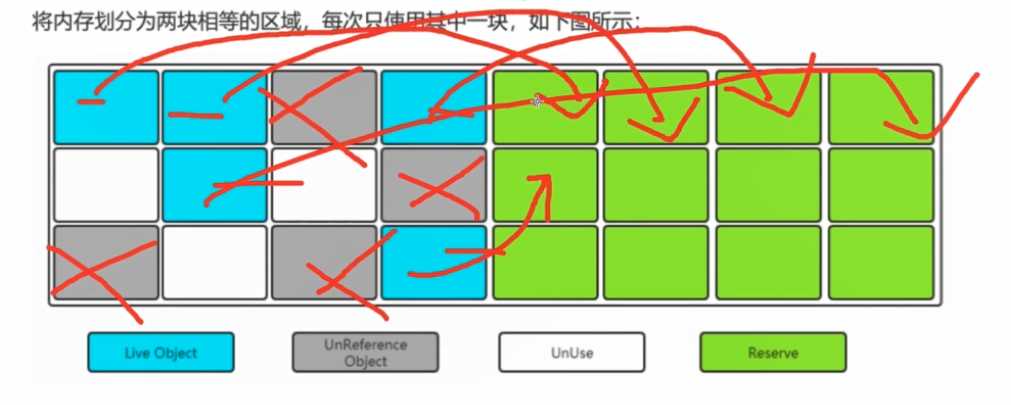
我有一个块内存区域
java进程启动时候,有一个initiaHeapSize,我是可以跟计算机要一个空间的,进行这个进程的数据保存。
initiaHeapSize = 100M --> 有一块100M的物理内存,可以向计算机要内存的。
我有一块内存区域,存着存着,发现不够用了,怎么办? 不够用了将会报错--->OutOfMemoryError
万一这个内存区域中,有些数据已经彻底没用了,我们把它称作垃圾,对应的垃圾回收算法对其进行回收。

相对于新生代而言,老年代占用空间更大,触发GC的时间更长,因此尽量减少从新生代中放对象到老年区。
因此需要一个缓冲,将新生代分为两个部分:Eden(生成新对象放在这里),Suvivor(在Eden的GC处理后的对象放到Suvivor中,Suvivor在GC后才放到老年区)
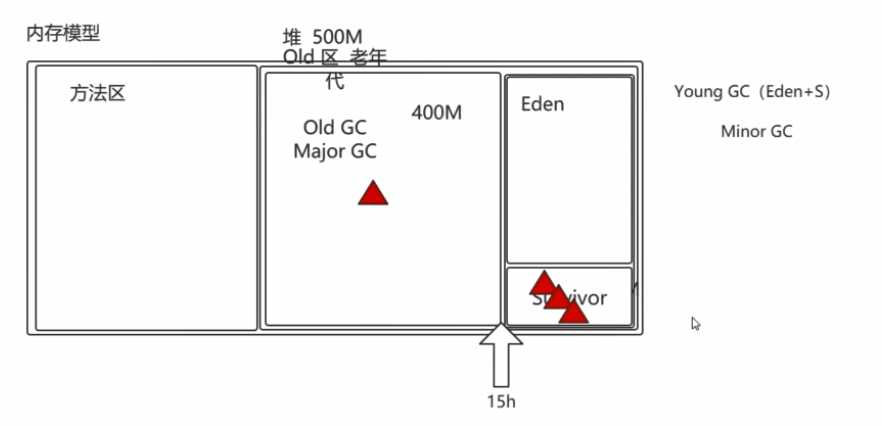
Suvivor中由于有些零碎的空间,但加进来的对象需要相连的空间才能存放,所以Suvivor有分为:两个Suvivor:From 、to,每时每刻永远有一块是空的,永远有一块是满的。
Suvivor中from和to可以相互转换(每时每刻都已一个是空的),如下图:
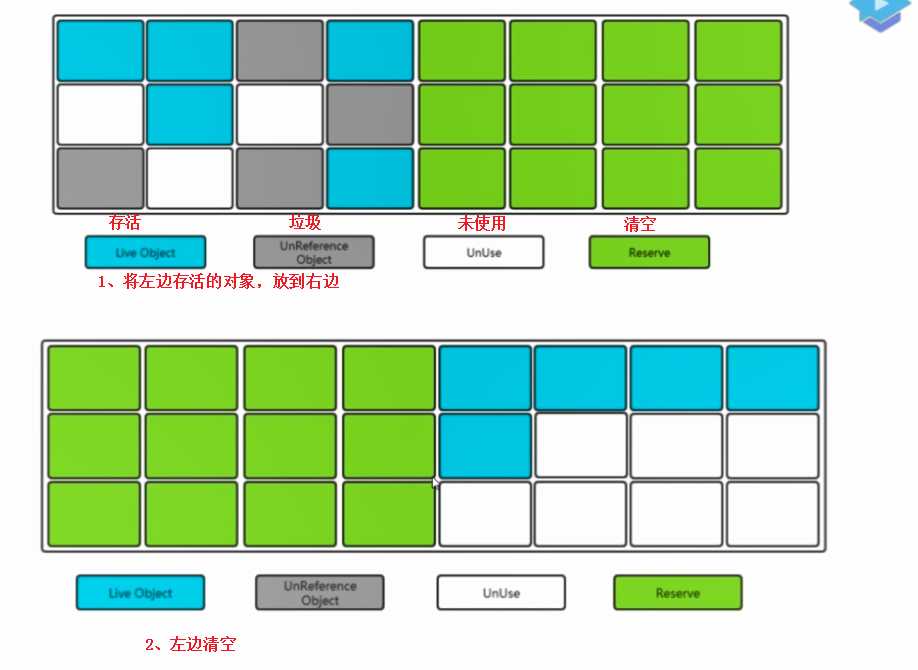
? 没错,我们就是要用这样的浪费来,获取50%的连续。
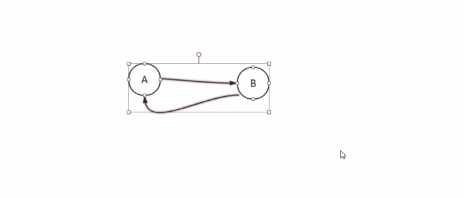
引用法:
如果是A引用B,B引用A,相互引用那么这两者永远都不会成为垃圾,永远都会占用内存空间,这样不合适。
回收 -->
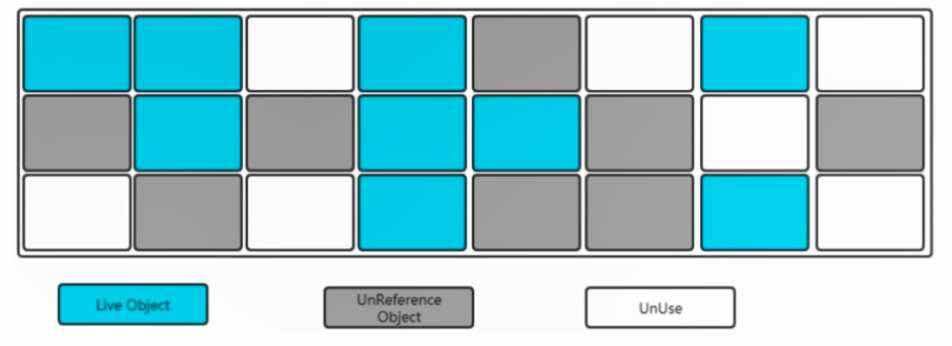
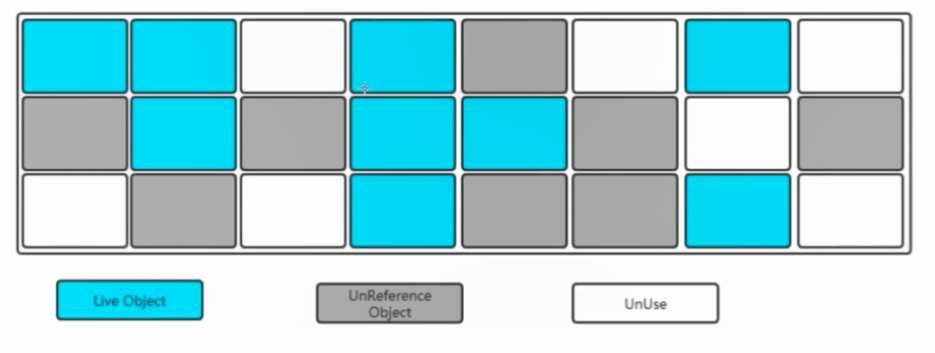
找出内存需要回收的对象,并且把它们标记出来
此时堆中所有的对象都会被扫描一遍,从而才能确定需要回收的对象,比较耗时。
清除垃圾对象
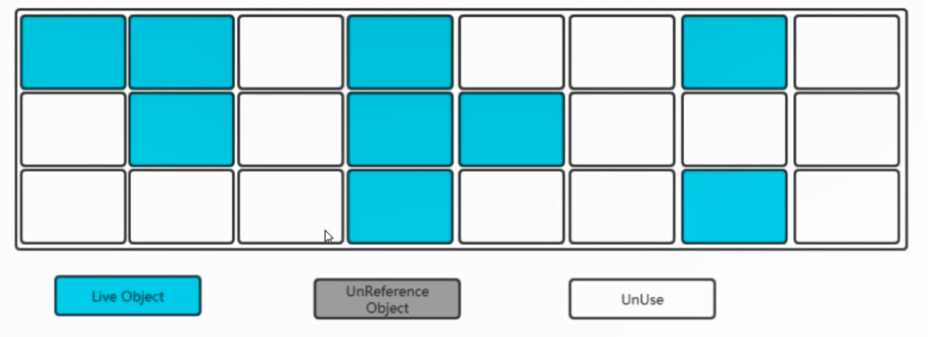
弊端:比较耗时(需要扫描真个内存空间,然后清除垃圾),空间碎片(不连续)
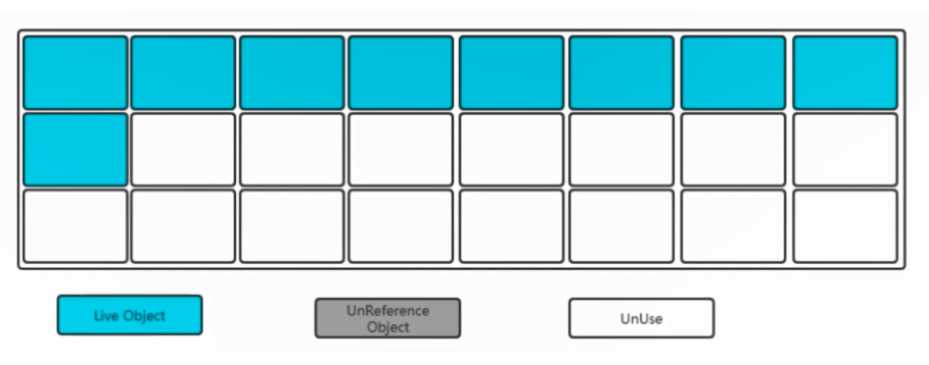
耗时(是将存活的对象移动到,另一个区间的时间)
将存活的对象,移动
堆:Old Young(Eden、S0和S1)
到底哪个算法用在哪个区域呢?
不同的代用不同的垃圾回收算法
Young区,复制--->前提条件:每次垃圾回收 存活的对象都比较少 ---> 复制算法
? 绝大多数的对象都被回收掉 --> Eden和Eden(S0 From和S1 To)
Old区呢?
? 一般是存活时间比较长,意味着很难被回收 ---> 标记-整理、标记清除
垃圾收集器(常用的G1处理器)

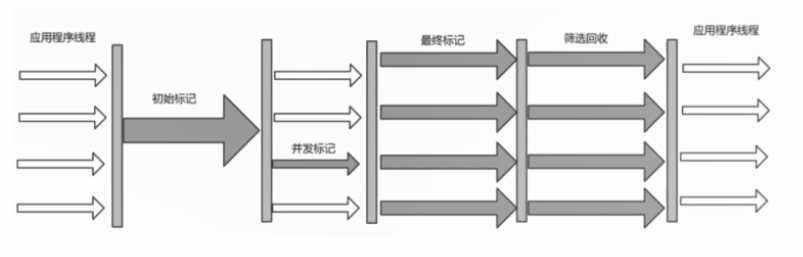
初识标记
使用一个垃圾回收线程,进行初识标记,注意此时其他用户线程暂定了
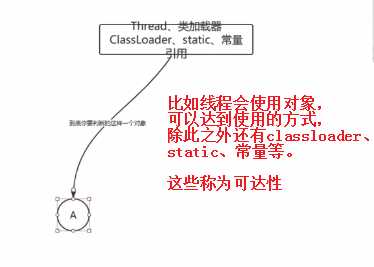
标记的是什么样的对象是垃圾:标记一下GC Roots能够直接关联到的对象,Stop the world
并发标记
从GC Roots触发可达性 存活的对象
最终标记
最终标记 再次标记 many GC Threads
筛选回收
回收垃圾对象 Stop the world
1、适当地增加对内存空间 (这样存放对象的空间变大,GC执行的时间变长)
2、合理的设计G1垃圾收集器的停顿时间 (一般默认都回收一定的停顿时间,可以增加)
3、垃圾回收的临界线
-XX:InitiatingHeapOccupancPercent = 50 (如一般到占内存的40%,就触发GC垃圾回收,可以设置到50%)
4、增加垃圾回收线程数量(增加线程回收,空出内存)
-XX:ConGCThreads =10
Young GC:可以称为 Minor GC
old GC:可以称为 Major
也就是:
Young + Old ===>(等同于) Minor GC + Major GC ===> Full GC
老年区触发的GC 是Full GC
这就是JVM
标签:将不 art add 数据类型 block 数据区 meta 不同的 top
原文地址:https://www.cnblogs.com/zhouyongyin/p/13391006.html