标签:操作 显示 details import pivot ace 设置 html reset
需求:低版本excel对于使用透视表后,索引方向会出现合并,需要将其恢复为“台账”样式。
解决方法:可以使用reset_index()。
在Pandas中如何给多层索引降级: https://blog.csdn.net/qq_36387683/article/details/86616367
pandas中DataFrame的stack()、unstack()和pivot()方法的对比:https://blog.csdn.net/S_o_l_o_n/article/details/80917211
Python: Pandas中stack和unstack的形象理解:https://blog.csdn.net/anshuai_aw1/article/details/82830916
python pandas stack和unstack函数:https://www.cnblogs.com/bambipai/p/7658311.html
Pandas 基础(12) - Stack 和 Unstack:https://www.cnblogs.com/rachelross/p/10439704.html
Python实现一维表与二维表之间的相互转化:https://blog.csdn.net/qq_41080850/article/details/86294173
从源数据转化使用数据透式表的话,最终的样式不方便筛选,存在合并单元格。实际想转化为中间的样式。
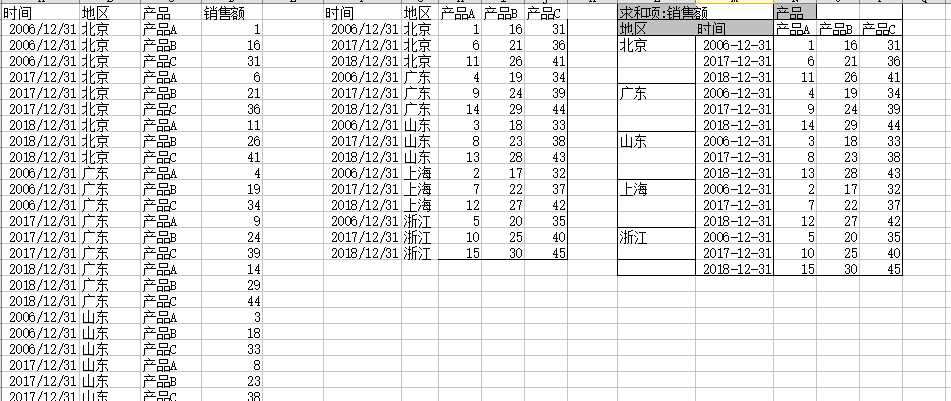
import pandas as pd import numpy as np df = pd.read_excel(r‘data/test2.xls‘) # 数据透式表 table = pd.pivot_table(df, values=‘销售额‘, index=[‘地区‘, ‘时间‘], columns=[‘产品‘], aggfunc=np.sum) table.head()
输出,与EXCEL操作一致,存在合并的格:
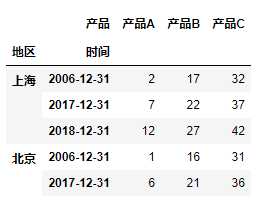
# 重置行索引,默认将原来的索引转化为列 table.reset_index().head()
输出:
注意:reset_index需要列只有一层索引,如果列存在多层索引,需要对列进行重新赋值再进行 reset_index()
# 将多层列索引组合层一层显示 table.columns = ["_".join(x) for x in table.columns.ravel()]
关于 stack 和 unstack 也可以达到同样的效果。
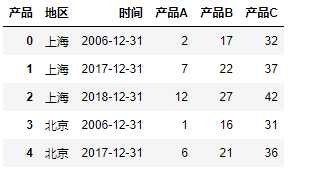
new_data = df.set_index([‘地区‘,‘时间‘,‘产品‘]) # 将df中的地区一列设置为索引列 new_data.head()
输出:
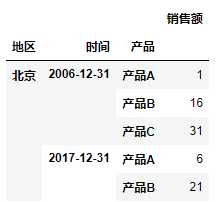
df2 = new_data.unstack(‘产品‘) # 因为列为多层索引,需要转化为1层 df2.columns = [x[1] for x in df2.columns.ravel()] df2.reset_index(inplace=True) df2.head()
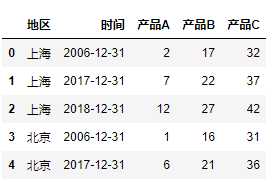
从这个需求来看,pivot_table 用法相对简单。
标签:操作 显示 details import pivot ace 设置 html reset
原文地址:https://www.cnblogs.com/cycxtz/p/13394583.html