标签:ogre 碎片 模拟 thread 改变 try cep amp ica
redis主从是基于redis复制上来使用和配置的,从服务器(slave)可以精确的复制主服务器(master)的内容。当主服务发生宕机之后,那么需要主服务器重启,恢复数据,需要消耗一定的时候,如果做了主从,可以直接切到从服务器。
每一个 Redis master 都有一个 replication ID :这是一个较大的伪随机字符串,标记了一个给定的数据集。每个 master 也持有一个偏移量,master 将自己产生的复制流发送给 slave 时,发送多少个字节的数据,自身的偏移量就会增加多少,目的是当有新的操作修改自己的数据集时,它可以以此更新 slave 的状态。复制偏移量即使在没有一个 slave 连接到 master 时,也会自增,所以基本上每一对给定的
Replication ID, offset
都会标识一个 master 数据集的确切版本。
当 slave 连接到 master 时,它们使用 PSYNC 命令来发送它们记录的旧的 master replication ID 和它们至今为止处理的偏移量。通过这种方式, master 能够仅发送 slave 所需的增量部分。但是如果 master 的缓冲区中没有足够的命令积压缓冲记录,或者如果 slave 引用了不再知道的历史记录(replication ID),则会转而进行一个全量重同步:在这种情况下, slave 会得到一个完整的数据集副本,从头开始。
首先复制两份配置
cp /opt/redis-5.0.5/redis.conf /opt/redis-5.0.5/copy/master.conf
cp /opt/redis-5.0.5/redis.conf /opt/redis-5.0.5/copy/slave.conf
修改一下服务配置信息
#master.conf
port 6379
#修改slave.conf
port 6380
slaveof 127.0.0.1 6379
启动服务
redis-cli ./copy/master.conf
redis-cli ./copy/slave.conf
查看主从节点的信息
#主服务
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6380,state=online,offset=21826,lag=1
master_replid:682b6cb7a4b93f72725c97c1f06096e602936048
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:21826
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:21826
#从服务
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:4
master_sync_in_progress:0
slave_repl_offset:21742
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:682b6cb7a4b93f72725c97c1f06096e602936048
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:21742
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:21742
顾名思义,哨兵的作用就是用来监控redis系统运行状况。主要有以下两个功能
其实哨兵在主从的的服务上减少了一部分运维的工作,如果只是做主从,当主节点挂了时候,需要手动的切换到从节点,那么使用哨兵来监控主和从节点的运行状态,当主服务挂了的时候,会自动选取一个从节点作为主节点,当宕机的主节点启动的时候变成了从节点。
一个哨兵:
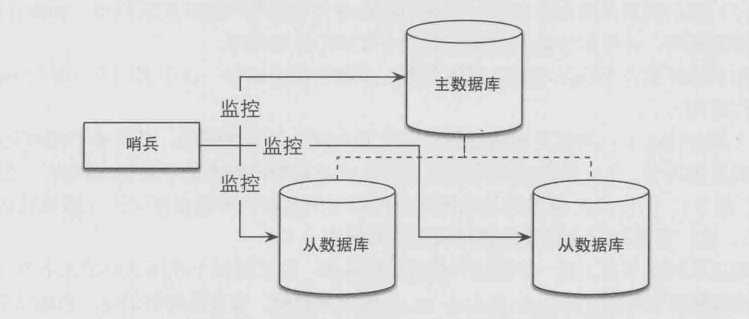
多个哨兵:
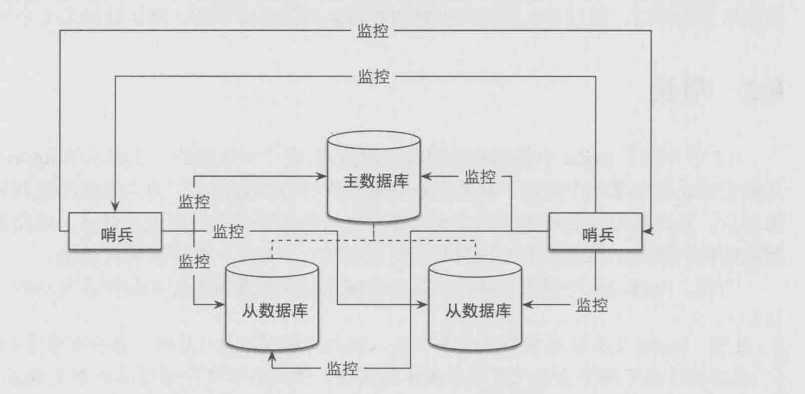
我这个测试是一主两从,在单机上面创建的
首先复制三份配置信息
cp /opt/redis-5.0.5/redis.conf /opt/redis-5.0.5/sentinel/redis1.conf
cp /opt/redis-5.0.5/redis.conf /opt/redis-5.0.5/sentinel/redis2.conf
cp /opt/redis-5.0.5/redis.conf /opt/redis-5.0.5/sentinel/redis3.conf
cp /opt/redis-5.0.5/sentinel.conf /opt/redis-5.0.5/sentinel/sentinel.conf
修改redis服务信息
#redis1.conf作为主节点不用动
port 6379
#redis2.conf
port 6380
slaveof 127.0.0.1 6379
#redis3.conf
port 6381
slaveof 127.0.0.1 6379
修改哨兵配置信息
port 26379
daemonize yes
sentinel monitor mymaster 127.0.0.1 6379 1
#mymaster 这个是主服务的名称,可以随便命名
#127.0.0.1 6379 主服务的ip和port
#1 选择主节点的时候的投票数,1表示有一个sentinel同意则可以升级为master
启动服务
redis-server ./sentinel/redis1.conf &
redis-server ./sentinel/redis2.conf &
redis-server ./sentinel/redis3.conf &
redis-server ./sentinel/sentinel.conf --sentinel &
查看配置信息
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=128067,lag=0
slave1:ip=127.0.0.1,port=6381,state=online,offset=128067,lag=1
master_replid:92256269552621fa0b87c9c2cadbd0efab672cb2
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:128067
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:128067
redis-cli -p 6379 shutdown
从命令窗口看到的日志
#启动哨兵,哨兵发现两个新的节点
11357:X 28 Jul 2020 16:47:09.216 # +monitor master mymaster 127.0.0.1 6379 quorum 2
11357:X 28 Jul 2020 16:47:09.216 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
11357:X 28 Jul 2020 16:47:09.219 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
#哨兵认为主节点挂了
11471:X 28 Jul 2020 16:49:03.528 # +sdown master mymaster 127.0.0.1 6379
#哨兵认为主节点服务停止了
11471:X 28 Jul 2020 16:49:03.528 # +odown master mymaster 127.0.0.1 6379 #quorum 1/1
11471:X 28 Jul 2020 16:49:03.528 # +new-epoch 1
#开始故障恢复
11471:X 28 Jul 2020 16:49:03.528 # +try-failover master mymaster 127.0.0.1 6379
11471:X 28 Jul 2020 16:49:03.531 # +vote-for-leader 497fc511623b8fdd6b63057eeffaa8e918bd835e 1
11471:X 28 Jul 2020 16:49:03.531 # +elected-leader master mymaster 127.0.0.1 6379
11471:X 28 Jul 2020 16:49:03.531 # +failover-state-select-slave master mymaster 127.0.0.1 6379
11471:X 28 Jul 2020 16:49:03.603 # +selected-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
11471:X 28 Jul 2020 16:49:03.603 * +failover-state-send-slaveof-noone slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
11471:X 28 Jul 2020 16:49:03.703 * +failover-state-wait-promotion slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
11471:X 28 Jul 2020 16:49:04.257 # +promoted-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
11471:X 28 Jul 2020 16:49:04.257 # +failover-state-reconf-slaves master mymaster 127.0.0.1 6379
11471:X 28 Jul 2020 16:49:04.310 * +slave-reconf-sent slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
11471:X 28 Jul 2020 16:49:05.299 * +slave-reconf-inprog slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
11471:X 28 Jul 2020 16:49:05.299 * +slave-reconf-done slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
#故障恢复完成
11471:X 28 Jul 2020 16:49:05.371 # +failover-end master mymaster 127.0.0.1 6379
#故障迁移,选择127.0.0.1 6381为主节点
11471:X 28 Jul 2020 16:49:05.371 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6381
11471:X 28 Jul 2020 16:49:05.371 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381
11471:X 28 Jul 2020 16:49:05.371 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381
11471:X 28 Jul 2020 16:49:35.386 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381
查看127.0.0.1 6381信息
127.0.0.1:6381> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6380,state=online,offset=49725,lag=1
master_replid:a7eabb97618a9e8550d436865d639c38fedeedaf
master_replid2:3f2cd991dfcc9641aa852d3876fe7613624504ce
master_repl_offset:49725
second_repl_offset:6100
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:49725
java代码连接
public class RedisTest {
public static void main(String[] args) throws InterruptedException {
RedisURI redisURI = RedisURI.builder()
.withSentinel("139.129.228.249", 26379)
.withSentinelMasterId("mymaster").build();
RedisClient redisClient = RedisClient.create(redisURI);
StatefulRedisConnection<String, String> connect = redisClient.connect();
for (int i=0;i<30;i++){
Thread.sleep(2000);
RedisCommands<String, String> sync =
connect.sync();
String list = sync.get("list");
System.out.println(list);
}
}
}
Redis 集群是一个提供在多个Redis间节点间共享数据的程序集。
Redis集群并不支持处理多个keys的命令,因为这需要在不同的节点间移动数据,从而达不到像Redis那样的性能,在高负载的情况下可能会导致不可预料的错误.
Redis 集群通过分区来提供一定程度的可用性,在实际环境中当某个节点宕机或者不可达的情况下继续处理命令. Redis 集群的优势:
配置redis集群至少配置6个redis节点,为什么需要配置6台,在官方文档当中有写到
Note that the minimal cluster that works as expected requires to contain at least three master nodes.
redis最小的集群需要6个redis节点,三主三从。
因为我这个是在单机上进行测试,所以只需要复制6个redis.conf文件就好了
我这里创建了一个cluster的文件夹分别创建了
cp /opt/redis-5.0.5/redis.conf /opt/redis-5.0.5/cluster/redis1.conf
cp /opt/redis-5.0.5/redis.conf /opt/redis-5.0.5/cluster/redis2.conf
cp /opt/redis-5.0.5/redis.conf /opt/redis-5.0.5/cluster/redis3.conf
cp /opt/redis-5.0.5/redis.conf /opt/redis-5.0.5/cluster/redis4.conf
cp /opt/redis-5.0.5/redis.conf /opt/redis-5.0.5/cluster/redis5.conf
cp /opt/redis-5.0.5/redis.conf /opt/redis-5.0.5/cluster/redis6.conf
如下图所示:

port 6379 ~6384
cluster-enabled yes
cluster-config-file nodes.conf 这个需要看怎么配置(如果在redis.conf在同一个文件夹下,nodes.conf的文件名称不能一致)
cluster-node-timeout
appendonly yesru
如下图所示:

redis-server /opt/redis-5.0.5/cluster/redis1.conf &
redis-server /opt/redis-5.0.5/cluster/redis2.conf &
redis-server /opt/redis-5.0.5/cluster/redis3.conf &
redis-server /opt/redis-5.0.5/cluster/redis4.conf &
redis-server /opt/redis-5.0.5/cluster/redis5.conf &
redis-server /opt/redis-5.0.5/cluster/redis6.conf &

创建redis集群命令如下
redis-cli --cluster create 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 --cluster-replicas 1
创建结果:
[root@iZm5e90lblkm0fx24i4930Z src]# redis-cli --cluster create 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 --cluster-replicas 1
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 127.0.0.1:6383 to 127.0.0.1:6379
Adding replica 127.0.0.1:6384 to 127.0.0.1:6380
Adding replica 127.0.0.1:6382 to 127.0.0.1:6381
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: 08de62ed947790050e41ec92c78f955345ff1477 127.0.0.1:6379
slots:[0-5460] (5461 slots) master
M: 6e17d6b6832a6ac4d3cbb3677ab731d119bc9ce8 127.0.0.1:6380
slots:[5461-10922] (5462 slots) master
M: c33f6ae2025223a04509eebd507e42c515e76b06 127.0.0.1:6381
slots:[10923-16383] (5461 slots) master
S: b05ec5cbdfcd8f6f9cd193bbb62662955e74ef52 127.0.0.1:6382
replicates 08de62ed947790050e41ec92c78f955345ff1477
S: 5eb36c9614fa2b63be65e8a09afb0371490548b3 127.0.0.1:6383
replicates 6e17d6b6832a6ac4d3cbb3677ab731d119bc9ce8
S: e4c47754052c36dccbed4a0f81596138765bf08c 127.0.0.1:6384
replicates c33f6ae2025223a04509eebd507e42c515e76b06
Can I set the above configuration? (type ‘yes‘ to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
...
>>> Performing Cluster Check (using node 127.0.0.1:6379)
M: 08de62ed947790050e41ec92c78f955345ff1477 127.0.0.1:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: b05ec5cbdfcd8f6f9cd193bbb62662955e74ef52 127.0.0.1:6382
slots: (0 slots) slave
replicates 08de62ed947790050e41ec92c78f955345ff1477
S: e4c47754052c36dccbed4a0f81596138765bf08c 127.0.0.1:6384
slots: (0 slots) slave
replicates c33f6ae2025223a04509eebd507e42c515e76b06
M: 6e17d6b6832a6ac4d3cbb3677ab731d119bc9ce8 127.0.0.1:6380
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 5eb36c9614fa2b63be65e8a09afb0371490548b3 127.0.0.1:6383
slots: (0 slots) slave
replicates 6e17d6b6832a6ac4d3cbb3677ab731d119bc9ce8
M: c33f6ae2025223a04509eebd507e42c515e76b06 127.0.0.1:6381
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
查询集群信息
随便登录哪一台redis,输入cluster info
127.0.0.1:6379> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_ping_sent:10951
cluster_stats_messages_pong_sent:10891
cluster_stats_messages_sent:21842
cluster_stats_messages_ping_received:10886
cluster_stats_messages_pong_received:10951
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:21842
cluster_state:ok; cluster_size:3;cluster_slots_ok:16384
在集群中,每个key存储都是存储在槽中(slot),每个节点负责一部分槽,所以redis集群不支持mget等命令。
Redis 集群没有使用一致性hash, 而是引入了 哈希槽的概念.
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽.集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么:
这种结构很容易添加或者删除节点. 比如如果我想新添加个节点D, 我需要从节点 A, B, C中得部分槽到D上. 如果我想移除节点A,需要将A中的槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可. 由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态.
计算哈希槽可以实现哈希标签(hash tags),但这有一个例外。哈希标签是确保两个键都在同一个哈希槽里的一种方式。将来也许会使用到哈希标签,例如为了在集群稳定的情况下(没有在做碎片重组操作)允许某些多键操作。
为了实现哈希标签,哈希槽是用另一种不同的方式计算的。基本来说,如果一个键包含一个 “{…}” 这样的模式,只有 { 和 } 之间的字符串会被用来做哈希以获取哈希槽。但是由于可能出现多个 { 或 },计算的算法如下:
然后不是直接计算键的哈希,只有在第一个 { 和它右边第一个 } 之间的内容会被用来计算哈希值。
例子:
#我这里使用的是lettuce客户端来测试的
public class RedisClusterTest {
public static void main(String[] args) {
RedisURI uri = RedisURI.builder().withHost("139.129.228.249").withPort(6380).build();
RedisClusterClient redisClusterClient = RedisClusterClient.create(uri);
StatefulRedisClusterConnection<String, String> connection = redisClusterClient.connect();
RedisAdvancedClusterCommands<String, String> commands = connection.sync();
// commands.all(); // 所有节点
// commands.masters(); // 主节点
// 从节点只读
NodeSelection<String, String> masters = commands.masters();
NodeSelectionCommands<String, String> nodeSelectionCommands = masters.commands();
// 这里只是演示,一般应该禁用keys *命令
Executions<List<String>> keys = nodeSelectionCommands.keys("*");
keys.forEach(key -> System.out.println("11"+key));
connection.close();
redisClusterClient.shutdown();
}
从上面描述了redis主从、redis哨兵、redis集群,简单的梳理一下三者之间的区别
redis主从:简单的描述就是一个备份的关系,从服务会精确的备份主服务的数据,当主服务挂了的时候可以直接切到从服务。
redis哨兵:哨兵的作用主要是监控作用,保证了故障的切换,当主服务挂了的时候,哨兵会选举出来从服务成为主服务
redis集群:集群的作用高并发,相对于redis主从、redis哨兵单节点,而集群多个主节点,同时数据也会存在不同的槽中
redis主从备份数据、redis哨兵保证故障的切换、redis集群高可用。具体可以根据业务场景来选择
参考:
redis主从、redis哨兵、redis集群配置搭建和使用
标签:ogre 碎片 模拟 thread 改变 try cep amp ica
原文地址:https://www.cnblogs.com/JackQiang/p/13394467.html