标签:action 子目录 版本 引用 建表 系统 信息 提交 ase
HBase拥有出色的扩展性,其中最依赖的就是region的自动split机制。1.split触发时机与策略
前面我们已经知道了,数据写入过程中,需要先写memstore,然后memstore满了以后,flush写入磁盘,形成新的HFile文件。
当HFile文件数量不断累积,Region server就会触发compaction机制,把小文件合并为大的HFIle。
当每次flush完成 或者 compaction完成后,regionSplitPolicy就会判断是否需要进行split。
split触发时机简单来说,就是看一个region里面的最大store是否超过阈值。
当然,hbase支持多种策略来设置这个阈值到底怎么计算,这就是触发策略。
2.split流程
一旦开始region split,那么就会创建两个daughter region。
这时候不会立刻将所有数据写到新的region里面去,而是创建引用文件,叫做Reference files,指向parent region。
reference文件作为一个数据规则文件,在split期间,新的查询会根据这个文件去父region的HStore上查询数据。当经过一次major compaction后,数据迁移到新的region中,reference文件会被删除,表示spilit真正完成。
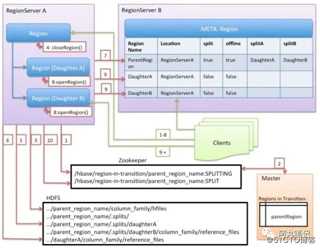
具体过程如下:
1)regionserver在zookeeper中创建一个新的znode在/hbase/region-in-transition/region-name目录下,状态为SPLITTING
2)master通过watch zk上的region-in-transition目录,得知这个region处于split状态
3)region server在HDFS的parent region目录下创建一个子目录叫做“.splits”
4)region server关闭parent region,强制flush这个region下的cache数据,并且标记这个region为下线状态。这个时候,如果有客户端请求落在这个region上,就会抛出NotServingRegionException。
5)Region server创建新的region在.spllits目录下,我们标记为daughter region A和daughter region B,同时创建必要的数据结构。然后就会创建两个Reference文件,指向parent region的那些存储文件。
6)Region Server在HDFS中创建实际的region目录,并将daughterA和daughter B移动到HBase根目录下,形成两个新的region。
7)Region server会发送put请求给.mete. table,然后把parent region设置为offline的状态,并且给新的region添加信息。
8)region server 打开新的region接受读写请求
9)region server将region A和B的信息添加到.meta.表,可以真正对外提供服务了。
扫尾工作:
1)客户端请求.meta.表,发现新的region信息,就会把本地缓存重新设置
2)region server更新zk上/hbase/region-in-transition/region-name目录下的znode状态,改为SPLIT,然后master通过watch得知这个信息。如果有必要,负载均衡器可以选择将新的region分布到新的region server上。
3)完成split工作后,meta和HDFS还是会保留reference文件到parent region。等到下次compaction时,会完成数据到新region的迁移,然后才会删除reference文件。
3.pre-splitting
当一张表被首次创建时,只会分配一个region给这个表。因此,在刚刚开始时,所有读写请求都会落在这个region所在的region server上,而不管你整个集群有多少个region server。不能充分地利用集群的分布式特性。
主要原因跟split的机制有关,一开始的时候,系统无法判断你到底需要用哪个rowkey进行split。
因此,hbase提供了工具让你能自己解决这个问题,叫做pre-splitting。
你可以在创建表的时候,指定哪些split point将region分成几份。如果切分的好,那么自然就可以一开始就充分利用分布式的特性。但是需要注意,如果切分的不好,存在热点region,那么反而会影响读写性能。
这里也没有一个特别好的原则来说到底pre split多少个region最合适,不过最好的方式,还是以region server数量的倍数(较小的倍数)来创建pre split的region数量,然后让集群本身去做自动的spliting。
4.split的事务性保证
2.0版本后,HBase会使用HLog存储单机事务(DDL\Split\Move等)的中间状态,保证了即使事务过程中出现异常,也能安全地回滚或继续提交。
原创:阿丸笔记(微信公众号:aone_note),欢迎 分享,转载请保留出处。
扫描下方二维码可以关注我哦~
标签:action 子目录 版本 引用 建表 系统 信息 提交 ase
原文地址:https://blog.51cto.com/14887261/2514287