标签:文章 EDA get 多用户 包括 nlp 接受 插入 资源
1、问题引出“Ingest node什么场景会遇到它? 一直没搜到它是在什么场景工作的?”
的确我们比较关心集群的节点角色的划分。包括:
集群应该几个节点?
几个节点用于数据存储?
要不要独立Master节点、协调节点?
但是Ingest node的场景用的比较少。
2、集群节点角色划分梳理
之前的文章:刨根问底 | Elasticsearch 5.X集群多节点角色配置深入详解有过解读。本文再参考7.1版本官方文档总结一下:
2.1 主节点
主节点负责集群相关的操作,例如创建或删除索引,跟踪哪些节点是集群的一部分,以及决定将哪些分片分配给哪些节点。
拥有稳定的主节点是衡量集群健康的重要标志。
注意:
1、由于索引和搜索数据都是CPU、内存、IO密集型的,可能会对数据节点的资源造成较大压力。 因此,在较大规模的集群里,最好要设置单独的仅主节点角色。(这点PB级集群调优时重点关注)
2、不要将主节点同时充当协调节点的角色,因为:对于稳定的集群来说,主节点的角色功能越单一越好。
2.2 数据节点
数据节点:保存包含索引文档的分片数据,执行CRUD、搜索、聚合相关的操作。属于:内存、CPU、IO密集型,对硬件资源要求高。
2.3 协调节点
搜索请求在两个阶段中执行(query 和 fetch),这两个阶段由接收客户端请求的节点 - 协调节点协调。
在请求阶段,协调节点将请求转发到保存数据的数据节点。 每个数据节点在本地执行请求并将其结果返回给协调节点。
在收集fetch阶段,协调节点将每个数据节点的结果汇集为单个全局结果集。
2.4 Ingest节点
ingest 节点可以看作是数据前置处理转换的节点,支持 pipeline管道 设置,可以使用 ingest 对数据进行过滤、转换等操作,类似于 logstash 中 filter 的作用,功能相当强大。
我把Ingest节点的功能抽象为:大数据处理环节的“ETL”——抽取、转换、加载。
前Elastic中国架构师吴斌的文章中对Ingest节点的评价很高,他指出
“2018这一年来拜访了很多用户,其中有相当一部分在数据摄取时遇到包括性能在内的各种各样的问题,那么大多数在我们做了ingest节点的调整后得到了很好的解决。Ingest节点不是万能的,但是使用起来简单,而且抛开后面数据节点来看性能提升趋于线性。所以我一直本着能用ingest节点解决的问题,绝不麻烦其他组件的大体原则”。
3、Ingest 节点能解决什么问题?
上面的Ingest节点介绍太官方,看不大懂怎么办?来个实战场景例子吧。
思考问题1:线上写入数据改字段需求
如何在数据写入阶段修改字段名(不是修改字段值)?
思考问题2:线上业务数据添加特定字段需求
如何在批量写入数据的时候,每条document插入实时时间戳?
这时,脑海里开始对已有的知识点进行搜索。
针对思考问题1:字段值的修改无非:update,updatebyquery?但是字段名呢?貌似没有相关接口或实现。
针对思考问题2:插入的时候,业务层面处理,读取当前时间并写入貌似可以,有没有不动业务层面的字段的方法呢?
答案是有的,这就是Ingest节点的妙处。
4、Ingest实践一把
针对问题1:
PUT _ingest/pipeline/rename_hostname
{
"processors": [
{
"field": "hostname",
"target_field": "host",
"ignore_missing": true
}
}]
}
PUT server
POST server/values/?pipeline=rename_hostname
{
"hostname": "myserver"
}
如上,借助Ingest节点的 rename_hostname管道的预处理功能,实现了字段名称的变更:由hostname改成host。
针对问题2:6.5版本ES验证ok如下。
PUT _ingest/pipeline/indexed_at
{
"description": "Adds indexed_at timestamp to documents",
"processors": [
{
"set": {
"field": "_source.indexed_at",
"value": "{{_ingest.timestamp}}"
}
}]
}
PUT ms-test
{
"settings": {
"index.default_pipeline": "indexed_at"}
}
POST ms-test/_doc/1
{"title":"just testing"}
如上,通过indexedat管道的set处理器与ms-test的索引层面关联操作,
ms-test索引每插入一篇document,都会自动添加一个字段indexat=最新时间戳。
5、Ingest节点基本概念
在实际文档索引发生之前,使用Ingest节点预处理文档。Ingest节点拦截批量和索引请求,它应用转换,然后将文档传递回索引或Bulk API。
强调一下: Ingest节点处理时机——在数据被索引之前,通过预定义好的处理管道对数据进行预处理。
默认情况下,所有节点都启用Ingest,因此任何节点都可以处理Ingest任务。我们也可以创建专用的Ingest节点。
要禁用节点的Ingest功能,需要在elasticsearch.yml 设置如下:
node.ingest:false
这里就涉及几个知识点:
1、预处理 pre-process
要在数据索引化(indexing)之前预处理文档。
2、管道 pipeline
每个预处理过程可以指定包含一个或多个处理器的管道。
管道的实际组成:
{
"description" : "...",
"processors" : [ ... ]
}
description:管道功能描述。
processors:注意是数组,可以指定1个或多个处理器。
3、处理器 processors
每个处理器以某种特定方式转换文档。
例如,管道可能有一个从文档中删除字段的处理器,然后是另一个重命名字段的处理器。 这样,再反过来看第4部分就很好理解了。
6、Ingest API
Ingest API共分为4种操作,分别对应:
PUT(新增)、
GET(获取)、
DELETE(删除)、
Simulate (仿真模拟)。
模拟管道AP Simulate 针对请求正文中提供的文档集执行特定管道。
除此之外,高阶操作包括:
1、支持复杂条件的Nested类型的操作;
2、限定条件的管道操作;
3、限定条件的正则操作等。
详细内容,参见官网即可。
常见的处理器有如下28种,举例:
append处理器:添加1个或1组字段值;
convert处理器:支持类型转换。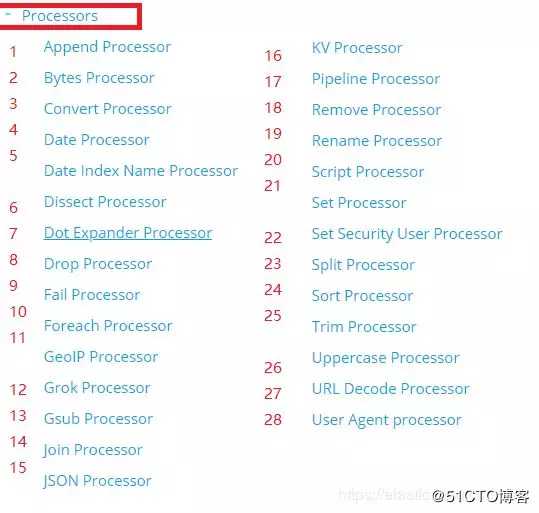
建议:没必要都过一遍,根据业务需求,反查文档即可。
7、Ingest节点和Logstash Filter 啥区别?
业务选型中,肯定会问到这个问题。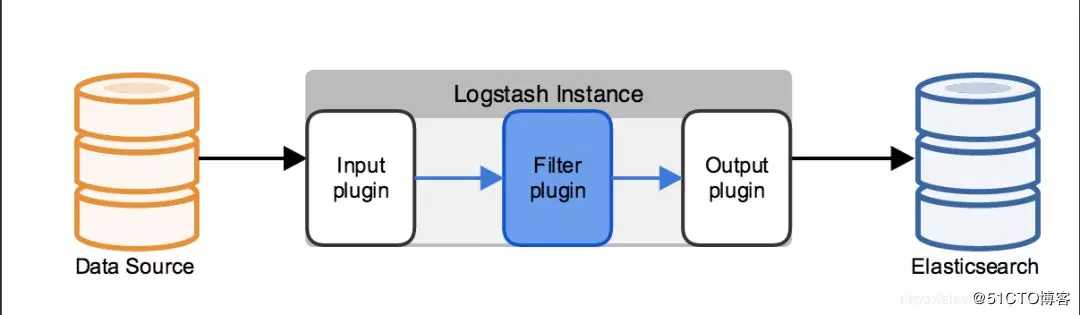
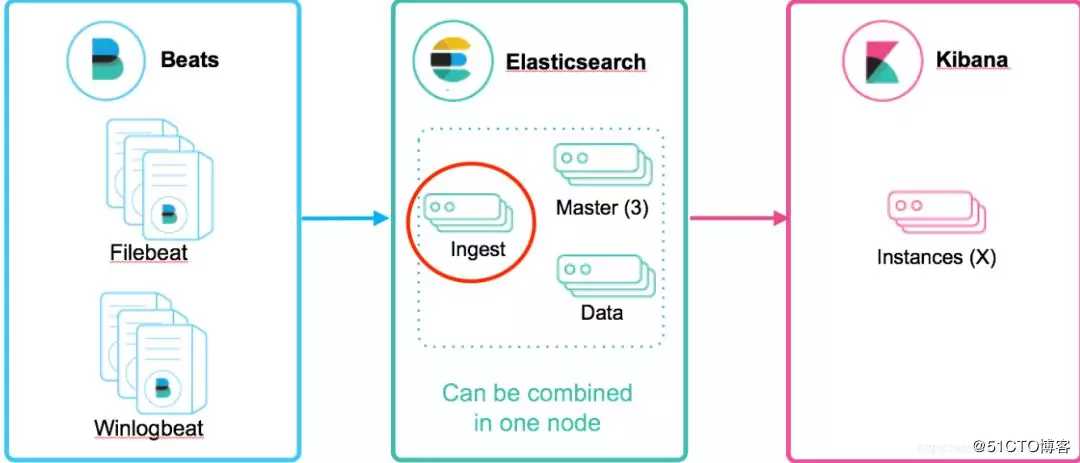
区别一:支持的数据源不同。
Logstash:大量的输入和输出插件(比如:kafka,redis等)可供使用,还可用来支持一系列不同的架构。
Ingest节点:不能从外部来源(例如消息队列或数据库)提取数据,必须批量bulk或索引index请求将数据推送到 Elasticsearch.
区别二:应对数据激增的能力不同。
Logstash:Logstash 可在本地对数据进行缓冲以应对采集骤升情况。如前所述,Logstash 同时还支持与大量不同的消息队列类型进行集成。
Ingest节点:极限情况下会出现:在长时间无法联系上 Elasticsearch 或者 Elasticsearch 无法接受数据的情况下,均有可能会丢失数据。
区别三:处理能力不同。
Logstash:支持的插件和功能点较Ingest节点多很多。
Ingest节点:支持28类处理器操作。Ingest节点管道只能在单一事件的上下文中运行。Ingest通常不能调用其他系统或者从磁盘中读取数据。
区别四:排他式功能支持不同。
Ingest节点:支持采集附件处理器插件,此插件可用来处理和索引常见格式(例如 PPT、XLS 和 PDF)的附件。
Logstash:不支持如上文件附件类型。
选型小结:
1、两种方式各有利弊,建议小数据规模,建议使用Ingest节点。原因:架构模型简单,不需要额外的硬件设备支撑。
2、数据规模大之后,除了建议独立Ingest节点,同时建议架构中使用Logstash结合消息队列如Kafka的架构选型。
3、将Logstash和Ingest节点结合,也是架构选型参考方案之一。
8、小结
Ingest是5.X版本就有的特性,不算是新知识点。
实践很重要!当我们对不熟悉的概念学习的时候,可以先查一下别人的应用场景,大致理解一下,再动手跟着官方文档敲一遍、理解一遍,加深认知。
基于Ingest实现的PDF文档预处理和索引,甚至基于Ingest自定义插件开发可以实现更多复杂的功能,你都可以尝试一下!
参考:
https://elasticsearch.cn/article/6221
https://discuss.elastic.co/t/etl-tool-for-elasticsearch/113803/9
https://github.com/bnafziger/elasticsearch-ingest-opennlp
标签:文章 EDA get 多用户 包括 nlp 接受 插入 资源
原文地址:https://blog.51cto.com/14886891/2515154