标签:可视化 inf 日志分析 华为 sql同步 角度 同事 语言 小结
0、问题引出
经群讨论,建议从以下几个方面展开,大家有好的想法,也欢迎留言交流。
1、可视化展示ELK效果
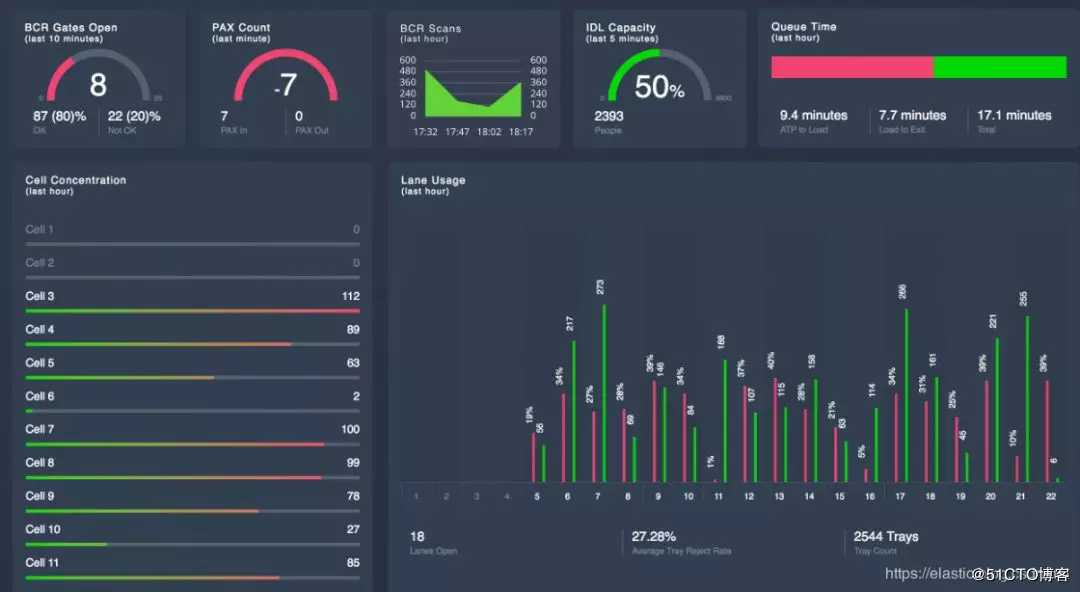
如果条件允许,demo的内容是:通过logstash 同步日志或数据库(oracle、mysql)表的数据到 Elasticsearch,然后通过kibana进行可视化。
1 通过Canvas对数据进行可视化布局与展现,可以实现非常酷炫的大屏展示效果。
2 展示实时数据的数据量。
3 展示你定的几个维度的数据信息。
这么切入的目的:很直观,很明显,很接地气。用到ELK技术栈的内容,有带动性,让参与的同事不犯困且很容易让大家对它产生兴趣。
2、 Elk stack大家族简介
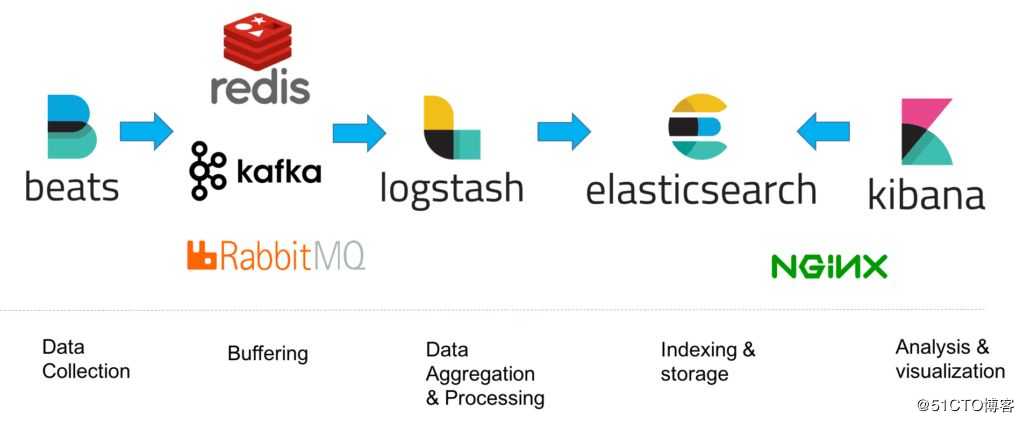
考虑到不同受众关注点不同。结合业务的数据的特点,从输入、中间处理、存储&检索、分析等全数据流环节展开。
2.1 输入
Elastic 支持的输入包含但不限于:
日志类数据:类log4j.log,apache log等,可借助 beats或logstash同步
关系型数据库:mysql oracle pgsql等
非关系型数据库:mongodb redis等
实时数据流:flink spark kafka hdfs等
大数据:hadoop hdfs等
此处的不同数据的导入,Lostash有丰富的input/output插件,支持N多不同数据源接入,估计同事也会眼前一亮。
2.2 中间处理ETL
基础数据很可能是异构的数据,中间的ETL非常重要。
logstash filter、elasticsearch ingest 都具备ETL功能。
2.3 存储&检索
基于合理的数据建模,在Elastic落地存储,Elastic提供全文检索、数据聚合等。
2.4 分析
强调一下,kibana的可视化和监控功能。
2.5 ELKB认知
Elastic Stack数据平台由Logstash、Beats、ElasticSearch和Kibana四大核心产品组成,在数据摄取、存储计算分析及数据可视化方面有着无可比拟的优势。
E = Elasticsearch,在存储、计算和分析方面,ElasticSearch允许执行和合并多种类型的搜索,解决不断涌现的各种用例,并具有极高的可用性及容错性,充分保障集群安全。
L = Logstash, Logstash 是开源的服务器端数据处理管道,可同时从多个来源采集、转换数据,并将数据发送到存储库中。
K = Kibana,Kibana作为用户界面的核心,集成了丰富的可视化工具、界面交互开发工具和管理工具,帮助开发人员将数据轻松分享给任何人,甚至还能通过机器学习来监测数据中的隐藏异常并追溯其来源。
B = Beats,Beats作为轻量级的数据搬运工,集合了多种单一用途数据采集器,将数据发送给Logstash或ElasticSearch,其可扩展的框架及丰富的预置采集器将使工作事半功倍。
以上,主要从大而全的维度,讲解ELK,给大家带来全景认知。
以这四大核心产品为基础构建的Elastic数据平台实现了数据实时性、相关性及扩展性的完美结合,不仅可以处理各种数据,还能深入挖掘数据的内在关联并迅速呈现,彻底解决企业的大数据实时处理难题。
3、 Elasticsearch 是什么?
展示的过程中:可以通过kibana的dsl进行展开的讲解。注意例子:可以提前准备好,规划好时间,不用现场敲代码。
此时可以借助head插件或者kibama-dev讲解。
3.1 Elasticsearch的组成
如果是集群部署的更好。
讲解内容包括:
集群、
索引、
分片、
副本、
分段、
倒排索引。
ES的底层是lucene等。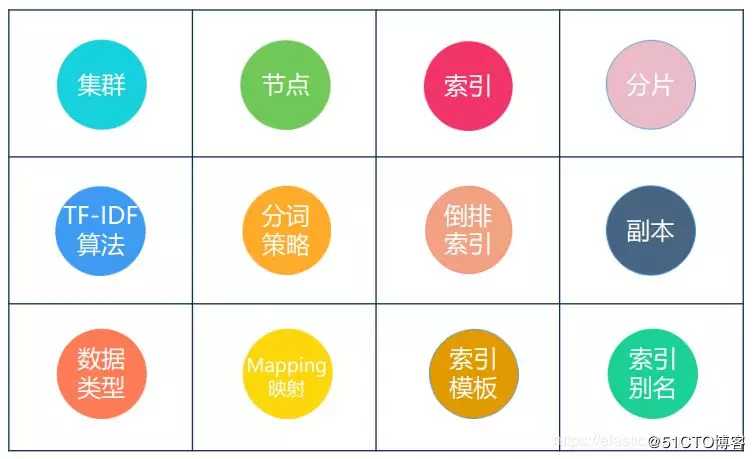
3.2 Elasticsearch分布式可扩展的特性
强调Elasticsearch可以支持PB级别甚至更高级别数据量的存储。
3.3 强调Elasticsearch特点
简单的restful api,天生的兼容多语言开发。
分布式的实时文件存储,每个字段都被索引且可用于搜索。
分布式的实时分析搜索引擎,海量数据下近实时秒级响应。
易扩展,处理PB级结构化或非结构化数据。
4、 Elasticsearch 能做什么?
4.1 全文检索等
其实也可以类比一下mysql,强调一下:关系型数据库一些检索是做不到的。
对比的目的:因为大家都熟悉关系型数据库,这样能够加深理解。
也可以类比下Google,百度等传统的搜索引擎。告诉同事,其实他们可以做的功能我们都可以做。比如:全文检索,高亮,分页,统计聚合,高级检索等。
检索的分类:
精确匹配。
模糊检索。
正则检索。
强调全文检索。强调他的快。基于倒排索引实现。
等等。
检索类型可以画一个脑图。
其实可以,举个例子。演示一下最好。
4.2 聚合分析
这里也可以举一下例子。
比如:对比一下mycle的group by,limit等功能点讲解。
聚合的分类很多,可以抽几个进行讲解。
4.3 应用场景
记录和日志分析
采集和组合公共数据
全文搜索及个性化推荐
事件数据和指标
数据可视化
5、Elasticsearch 极易上手且性能牛逼
主流的Java、python、ruby等。C++等也有个人开源维护API。
可以借助他山之石,把其他公司的应用场景、对应的硬件资源、写入、查询、QPS等性能指标展示出来,凸显牛逼功能和性能。
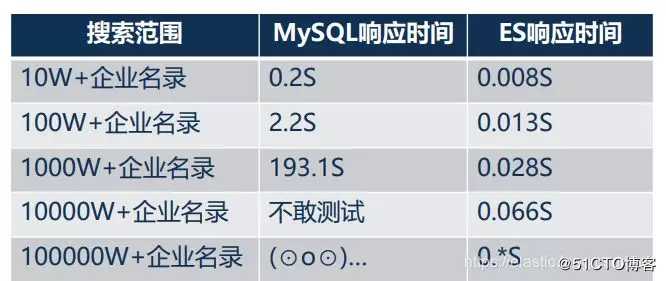
6、Elastic 前景光明
Elasticsearch在DBRanking 数据库排行榜搜索引擎部分近几年一直处于第一名的领先优势。
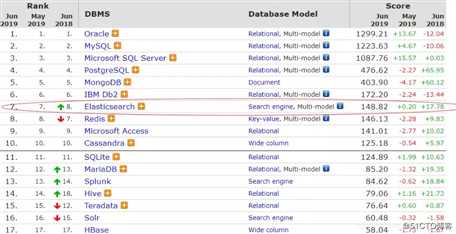
基于Elastic的分布式、可扩展性、良好的性能,BAT、滴滴、美团、小米、华为、携程、360、有赞等几乎所有的主流互联网公司甚至婚庆网站的搜索引擎已经都已经转成ES了。
那么咱们公司还在犹豫什么呢?
7、Elastic技术社区非常活跃
这里主要强调,出了问题也不用怕,一个人搞不定,还有国外、国内官方论坛、社区,基本很短时间都能解决问题。
交流的高效性、问题解决的速度、github迭代更新的速度。以及最近的版本更新的速度:比如7.0的发布,7.0的新特性。大家也会对新的特性充满期待。速度提升快。
估计讲完这些大家都会跃跃欲试了。
8、Elasticsearch 相对薄弱的环节
有所为,有所不为。
8.1 多表关联
不能简单认为,将mysql同步到Elasticsearch就能解决问题了。
我们除了看到基于倒排索引Elasticsearch的全文检索的强大,也要看到Elasticsearch对于关系型数据库多表关联的支持相对薄弱,nested类型、Join类型的多表关联操作大数据场景下都会有性能问题。
8.2 深度分页
从性能角度考虑,Elasticsearch默认支持10000条数据的返回,除非修改max_result_window参数。
也就是会出现越往后翻页越慢的情况。这点,补救方案:scroll+scroll_after实现。
但是,更长远角度,建议:参考Google、百度的深度分页实现。
8.3 实时性
Elasticsearch是近实时的系统,不是准实时。受限于:refresh_inteval设置,有最快1s延时。
准实时要求高的场景,建议选型注意。
9 小结
ELK远不止文章中提到的这些内容,可以说,以上列举的只是冰山一角的点,N多底层原理(索引分片原理、写入原理、检索原理、倒排索引原理、高可靠性原理、大数据实战场景等)都没有提及或展开。
如果,你来分享,你会如何展开,欢迎交流。
标签:可视化 inf 日志分析 华为 sql同步 角度 同事 语言 小结
原文地址:https://blog.51cto.com/14886891/2515137