标签:buffere 解析 system 编码 fileread 进制 http pre style
1.字符编码
编码:字符(能看懂的)-->字节(看不懂的)
解码:字节(看不懂的)-->字符(能看懂的)
乱码:按照A规则存储,同样按照A规则解析,那么会显示正确的文本符号;
反之,按照A规则存储,再按B规则解析,会导致乱码现象。
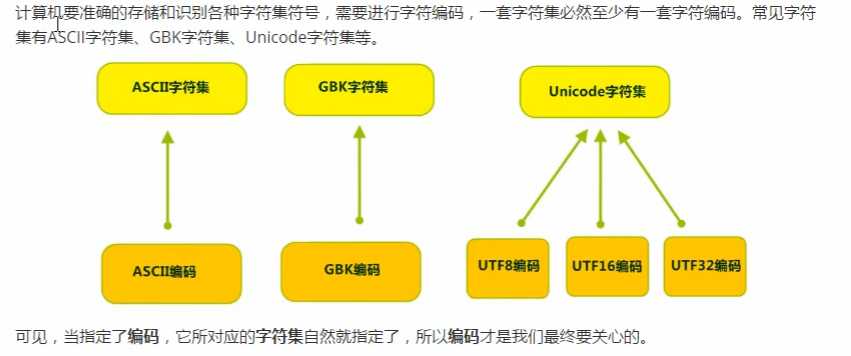
字符编码(Character Encoding):就是一套自然语言的字符与二进制数之间的对应规则
编码表:生活中文字和计算机中二进制的对应规则
2.字符集就是编码表,是系统所有字符的集合,包括各个国家文字、标点符号、图形符号、数字
等


编码引发的乱码问题:
package iotest.bufferedIOtest; /*FileReader在IDEA中默认的编码格式为UTF-8 * FileReader读取系统默认编码(GBK),会出现乱码 * */ import java.io.FileInputStream; import java.io.FileReader; import java.io.IOException; public class ErrorCodeTest { public static void main(String[] args) throws IOException { FileReader fr = new FileReader("C:\\test\\系统默认GBK编码文本1.txt"); int len =0; while ((len = fr.read()) != -1){ System.out.print((char) len); } fr.close(); } }
运行结果为:

源文件内容为:
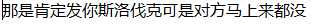
出现了乱码现象
解决乱码的方法:
标签:buffere 解析 system 编码 fileread 进制 http pre style
原文地址:https://www.cnblogs.com/zgmzbhqa/p/13411959.html