标签:问题: 正则 教程 字符 基础 put att 定义 同义词
1、问题抛出现在要精确匹配。 我的想法是:用自定义分词通过分号分词。但是这样我检索Li,LeiLei那么LeiLei Li就不能搜索到,我希望的结果是LeiLei Li也被搜索到。
而且这种分词,Li,LeiLei不加逗号,也不能匹配到。但是不知道为什么我在mapping里面添加停用词也不管用?
2、本文思路
从问题出发,由浅入深逐步探讨
为什么需要分词?
文档转换为倒排索引,发生了什么?
Elasticsearch自带的分词器
自定义分词器的模板
针对问题,实践一把
3、为什么需要分词?
中文分词是自然语言处理的基础。
语义维度:单字很多时候表达不了语义,词往往能表达。分词相当于预处理,能使后面和语义有关的分析更准确。
存储维度:如果所有文章按照单字来索引,需要的存储空间和搜索计算时间就要多的多。
时间维度:通过倒排索引,我们能以o(1) 的时间复杂度,通过词组找到对应的文章。
同理的,英文或者其他语种也需要分词。
设计索引的Mapping阶段,要根据业务用途确定是否需要分词,如果不需要分词,建议设置keyword类型;需要分词,设置为text类型并指定分词器。
推荐阅读:干货 | 论Elasticsearch数据建模的重要性
分词使用的时机:
1)创建或更新文档时,会对文档做分词处理。
2)查询时,会对查询语句进行分词处理。
4、文档转换为倒排索引,发生了什么?
注意:如下文档中部分关键词的翻译后反而不好理解,部分关键词我会使用和官方一致的英文关键词。
文档被发送并加入倒排索引之前,Elasticsearch在其主体上的操作称为分析(analysis)。
而analysis的实现可以是Elasticsearch内置分词器(analyzer)或者是自定义分词器。
Analyzer的由如下三部分组成:
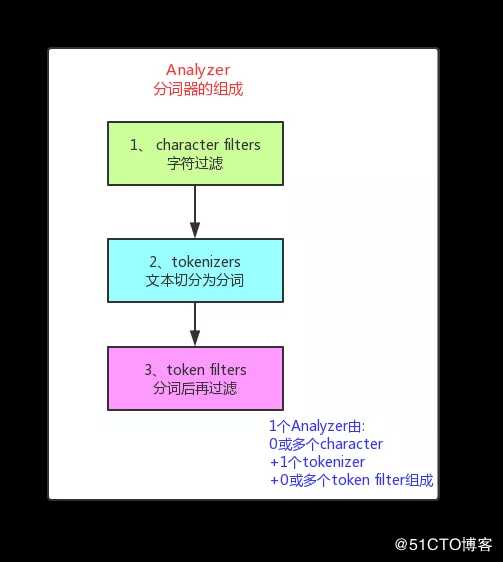
4.1 character filters 字符过滤
字符过滤器将原始文本作为字符流接收,并可以通过添加,删除或更改字符来转换字符流。
字符过滤分类如下:
HTML Strip Character Filter.
用途:删除HTML元素,如<b>,并解码HTML实体,如&amp 。
Mapping Character Filter
用途:替换指定的字符。
Pattern Replace Character Filter
用途:基于正则表达式替换指定的字符。
4.2 tokenizers 文本切分为分词
接收字符流(如果包含了4.1字符过滤,则接收过滤后的字符流;否则,接收原始字符流),将其分词。
同时记录分词后的顺序或位置(position),以及开始值(start_offset)和偏移值(end_offset-start_offset)。
tokenizers分类如下:
Standard Tokenizer
Letter Tokenizer
Lowercase Tokenizer
…..
详细需参考官方文档。
4.3 token filters分词后再过滤
针对tokenizers处理后的字符流进行再加工,比如:转小写、删除(删除停用词)、新增(添加同义词)等。
是不是看着很拗口,甚至不知所云。
没关系,但,脑海中的这张三部分组成的图以及三部分的执行顺序一定要加深印象。
5、Elasticsearch自带的Analyzer
5.1 Standard Analyzer
标准分析器是默认分词器,如果未指定,则使用该分词器。
它基于Unicode文本分割算法,适用于大多数语言。
5.2 Whitespace Analyzer
基于空格字符切词。
5.3 Stop Analyzer
在simple Analyzer的基础上,移除停用词。
5.4 Keyword Analyzer
不切词,将输入的整个串一起返回。
…….
更多分词器参考官方文档。
6、自定义分词器的模板
自定义分词器的在Mapping的Setting部分设置。
PUT my_custom_index
{
"settings":{
"analysis":{
"char_filter":{},
"tokenizer":{},
"filter":{},
"analyzer":{}
}
}
}
脑海中还是上面的三部分组成的图示。
其中:
"char_filter":{},——对应字符过滤部分;
"tokenizer":{},——对应文本切分为分词部分;
"filter":{},——对应分词后再过滤部分;
"analyzer":{}——对应分词器组成部分,其中会包含:1. 2. 3。
7、针对问题,实践一把
7.1 问题拆解
核心问题1:实际检索中,名字不带","。
逗号需要字符过滤掉。在char_filter阶段实现。
核心问题2:思考基于什么进行分词?
Li,LeiLei;Han,MeiMei;的构成中,只能采用基于“;"分词方式。
核心问题3:支持姓名颠倒后的查询。
即:LeileiLi也能被检索到。
需要结合同义词实现。
在分词后再过滤阶段,将:LiLeiLei和LeiLeiLi设定为同义词。
7.2 实践
基于问题的答案如下:
PUT my_index
{
"settings": {
"analysis": {
"char_filter": {
"my_char_filter": {
"type": "mapping",
"mappings": [
", => "
]
}
},
"filter": {
"my_synonym_filter": {
"type": "synonym",
"expand": true,
"synonyms": [
"lileilei => leileili",
"hanmeimei => meimeihan"
]
}
},
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer",
"char_filter": [
"my_char_filter"
],
"filter": [
"my_synonym_filter"
]
}
},
"tokenizer": {
"my_tokenizer": {
"type": "pattern",
"pattern": "\;"
}
}
}
},
"mappings": {
"_doc": {
"properties": {
"text": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
}
7.3 analyze API的妙处
用途:
实际业务场景中,检验分词的正确性。
排查检索结果和预期不一致问题的利器。
用法1:直接验证分词结果。
GET my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "Li,LeiLei"
}
用法2:基于索引字段验证分词结果。
GET my_index/_analyze
{
"field": "my_text",
"text": "Li,LeiLei"
}
8、小结
自定义分词这块,我认为不大好理解。光是:1)"char_filter":2)"tokenizer" 3)"filter" 4)"analyzer"就很容易把人绕进去。
网上中文文档的各种翻译不完全一致,很容易误导,官方英文文档的解读会更准确。
要牢记图中三部分的组成,结合实际业务场景具体分析+实践会加深自定义分词的理解。
参考:
1、官方文档
2、rockybean教程
标签:问题: 正则 教程 字符 基础 put att 定义 同义词
原文地址:https://blog.51cto.com/14886891/2515536