标签:jpg The 难度 随机 距离 合成 precision 评价指标 http
文章来自:微信公众号【机器学习炼丹术】
分类(classification)问题是数据挖掘领域中非常重要的一类问题,目前有琳琅满目的方法来完成分类。然而在真实的应用环境中,分类器(classifier)扮演的角色通常是识别数据中的“少数派”,比如:
在这样的应用环境下,作为少数派的群组在数据总体中往往占了极少的比例:绝大多数的信用卡交易都是正常交易,八成以上的邮件都是正常邮件,大多数的流水线产品是合格产品,在进行检查的人群中特定疾病的发病率通常非常低。
如果这样的话,假设99%的正样本+1%的负样本构成了数据集,那么假设模型的预测结果全是正,这样的完全没有分辨能力的模型也可以得到99%的准确率。这个按照样本个数计算准确率的评价指标叫做——Accuracy.
因此我们为了避免这种情况,最常用的评价指标就是F-score,Precision&Recal,Kappa系数。
【F-Score和Kappa系数已经在历史文章中讲解过啦】
解决办法主要有下面10种不同的方法。
重采样的目的就是让少的样本变多,或者是让多的样本变少。下图很形象的展示出这个过程:
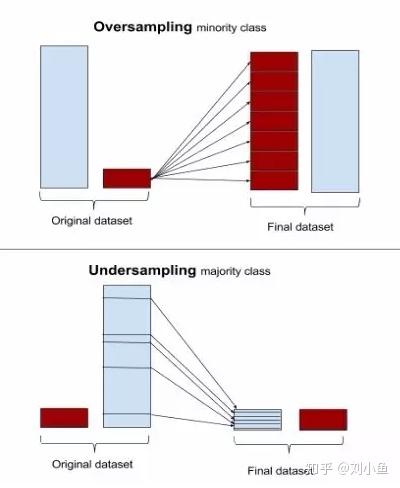
【简单上采样】
就是有放回的随机抽取少数量的样本,饭后不断复制抽取的随机样本,直到少数量的样本与多数量的样本处于同一数量级。但是这样容易造成过拟合问题。
为什么会造成过拟合呢? 最极端的例子就是把一个样本复制100次,这样就有了一个100样本的数据库。模型训练出来很可能得到100%的正确率,但是这模型真的学到东西了吗?
【SMOTE】
核心思想是依据现有的少数类样本人为制造一些新的少数类样本 SMOTE在先用K近邻算法找到K个近邻,利用这个K个近邻的各项指标,乘上一个0~1之间的随机数就可以组成一个新的少数类样本。容易发现的是,就是SMOTE永远不会生成离群样本
【ADASYN】
ADASYN其实是SMOTE的一种衍生技术,相比SMOT在每一个少数类样本的周围随机的创建样本,ADASYN给每一个少数类的样本分配了权重,在学习难度较高的少数类样本周围创建更多的样本。在K近邻分类器分类错误的那些样本周围生成更多的样本,也就是给他们更大的权重,而并不是随机0~1的权重。
这样的话,就好像,一个负样本周围有正样本,经过这样的处理后,这个负样本周围会产生一些相近的负样本。这样的弊端也是显而易见的,就是对离群点异常敏感。
【简单下采样】
这个很简单,就是随机删除一些多数的样本。弊端自然是,样本数量的减少,删除了数据的信息
【聚类】
这个是一个非常有意思的方法。我们先选取样本之间相似度的评估函数,比方说就用欧氏距离(可能需要对样本的数据做归一化来保证不同特征的同一量纲)。
方法1:假设有10个负样本和100个正样本,对100个正样本做kmeans聚类,总共聚10个类出来,然后每一个类中心作为一个正样本。
方法2:使用K近邻,然后用K个样本的中心来代替原来K个样本。一直这样做,直到正样本的数量等于负样本的数量。
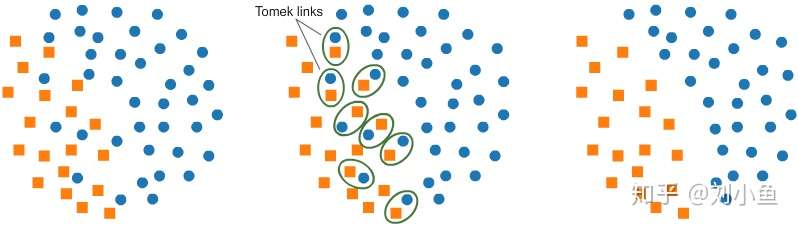
【Tomek links】
Tomek links是指相反类样本的配对,这样的配对距离非常近,也就是说这样的配对中两个样本的各项指标都非常接近,但是属于不同的类。如图所示,这一方法能够找到这样的配对,并删除配对中的多数类样本。经过这样的处理,两类样本之间的分界线变得更加清晰,使少数类的存在更加明显。
下图是操作的过程。
调整损失函数的目的本身是为了使模型对少数量样本更加敏感。训练任何一个机器学习模型的最终目标是损失函数(loss function)的最小化,如果能够在损失函数中加大错判少数类样本的损失,那么模型自然而然能够更好地识别出少数类样本。
比较著名的损失函数就是目标检测任务中的focal loss。不过在处理其他任务的时候,也可以人为的增加少数样本错判的损失。
这个异常值检测框架又是一个非常大的体系,有很多不同的模型,比方说:异常森立等。之后会专门讲讲这个体系的模型的。
(小伙伴关注下公众号呗,不迷路呀)
对于不均衡程度较低的数据,可以将多数量样本进一步分为多个组,虽然二分类问题被转化成了一个多分类问题,但是数据的不平衡问题被解决,接下来就可以使用多分类中的一对多(OVA)或一对一(OVO)的分类方式进行分类。
就是把多数类的样本通过聚类等方法,划分成不同的类别。这样2分类任务就变成了多分类任务。
另外一种欠采样的改进方法是 EasyEnsemble ,它将多数样本划分成若 N个集合,然后将划分过后的集合与少数样本组合,这样就形成了N个训练集合,而且每个训练都正负样本均衡,并且从全局来看却没有信息丢失。
标签:jpg The 难度 随机 距离 合成 precision 评价指标 http
原文地址:https://www.cnblogs.com/PythonLearner/p/13417544.html