标签:存在 field 广度优先 巴巴 要求 案例 agg 速度慢 支持
1、Elasticsearch支持聚合后分页吗,为什么?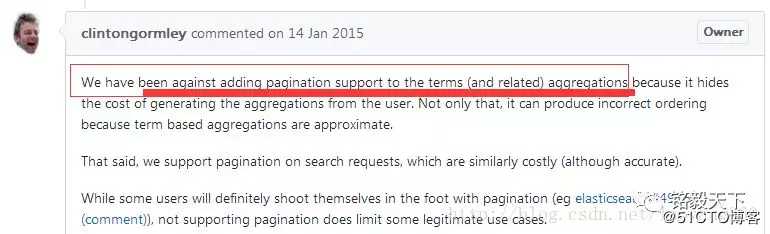
具体为什么会不正确?
这是因为每个分片都提供了自己对有序列表应该是什么的看法,并将这些列表结合起来给出最终的结果值。
举例如下:
对于如下的聚合:聚合出产品数据量的前5名。
GET /_search
{
"aggs" : {
"products" : {
"terms" : {
"field" : "product",
"size" : 5
}
}
}
}
步骤1: 三个分片的统计计数如下: 
步骤2:各分片取前5名。 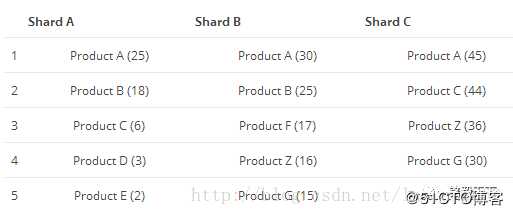
步骤3:依据各分片前5名,聚合得出总前5名。 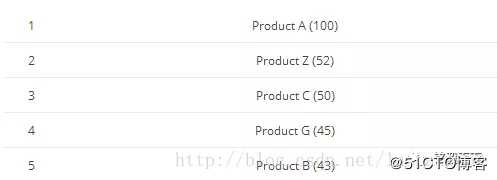
仅以产品C的排名作为举例,产品C(50个)的数据来自分片A(6个)和分片C(44个)之和。
所以,排名第三。
实际产品C在分片B中还存在4个,只不过这四个按照排名处于第10位,取前5的时候,显然取不到。
所以,导致聚合结果不准确。
官网有详细举例解读。
2、Elasticsearch要实现聚合后分页,该怎么办?
方案:需要展示满足条件的全部数据条数,即需要全量聚合,且按照某规则排序。
记住,如果数据基数大(十万、百万甚至千万级),这必然会很慢。
步骤1:全量聚合,size设置为: 2147483647。
ES5.X/6.X版本设置为2147483647 ,
它等于2^31-1, 是32位操作系统中最大的符号型整型常量;
ES1.X 2.X版本设置为0。
步骤2:将聚合结果存入内存中,可以考虑list或map存储。
这里存入list的_id是基于某种规则排序过的,如:基于插入时间。
步骤3:内存内分页,基于list中存储值结合偏移值进行筛选。
如每页10条数据,取第一页就是:取list中第0到第9个元素,以此类推。
步骤4:基于筛选出的值进行二次查询获取详情。
此处的筛选条件已经能唯一确定一篇document。
3、“聚合后不能分页,但能分区来取”,是什么鬼?
貌似,没有起到分页的作用。此处没有深入研究。
4、聚合后分页实战
步骤1:建立索引
PUT book_index
{
"mappings": {
"book_type": {
"properties": {
"_key": {
"type": "keyword",
"ignore_above": 256
},
"pt": {
"type": "date"
},
"url": {
"type": "keyword",
"ignore_above": 256
},
"title": {
"type": "text",
"term_vector": "with_positions_offsets",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
},
"analyzer": "ik_smart"
},
"abstr": {
"type": "text",
"term_vector": "with_positions_offsets",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
},
"analyzer": "ik_smart"
},
"rplyinfo": {
"type": "text",
"term_vector": "with_positions_offsets",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
},
"analyzer": "ik_smart"
},
"author": {
"type": "keyword",
"ignore_above": 256
},
"booktype": {
"type": "keyword",
"ignore_above": 256
},
"price": {
"type": "long"
}
}
}
}
}
步骤2:导入数据
举例原因,假设后来导入百万甚至千万级别数据。
POST book_index/book_type/1
{
"title":"《Elasticsearch深入理解》",
"author":"ERicif",
"abstr":"Elasticsearch实战书籍",
"relyinfo":"不错,值得推荐",
"booktype":"技术",
"price":79,
"pt":1543611840000
}
POST book_index/book_type/2
{
"title":"《大数据之路》",
"author":"阿里巴巴",
"abstr":"大数据实现",
"relyinfo":"不错,值得推荐2",
"booktype":"技术",
"price":89,
"pt":1543011840000
}
POST book_index/book_type/3
{
"title":"《人性的弱点》",
"author":"卡耐基",
"abstr":"直击人性",
"relyinfo":"不错,值得推荐2",
"booktype":"励志",
"price":59,
"pt":1543101840000
}
POST book_index/book_type/4
{
"title":"《Flow案例精编》",
"author":"ERicif",
"abstr":"Flow案例",
"relyinfo":"还可以",
"booktype":"技术",
"price":57,
"pt":1543201840000
}
POST book_index/book_type/5
{
"title":"《kibana案例精编》",
"author":"ERicif",
"abstr":"kibana干货",
"relyinfo":"还可以,不孬",
"booktype":"技术",
"price":53,
"pt":1480539840000
}
步骤3:聚合
要求:按照以下条件聚合
1)相同作者出书量;(聚合)
2)相同作者的书,取时间最大的返回。(聚合后排序)
POST book_index/_search
{
"sort": [
{
"pt": "desc"
}
],
"aggs": {
"count_over_sim": {
"terms": {
"field": "author",
"size": 2147483647,
"order": {
"pt_order": "desc"
}
},
"aggs": {
"pt_order": {
"max": {
"field": "pt"
}
}
}
}
},
"query": {
"bool": {
"must": [
{
"bool": {
"should": [
{
"match": {
"booktype": "技术"
}
}
]
}
},
{
"range": {
"pt": {
"gte": 1451595840000,
"lte": 1603201840000
}
}
}
]
}
},
"_source": {
"includes": [
"title",
"abstr",
"pt",
"booktype",
"author"
]
},
"from": 0,
"size": 10,
"highlight": {
"pre_tags": [
"<span style=\"color:red\">"
],
"post_tags": [
"</span>"
],
"fields": {
"title": {}
}
}
}
步骤4:获取关键信息存入list。
步骤5:二次遍历+偏移截取分页实现。
5、Elasticsearch聚合+分页速度慢,该如何优化?
优化方案:改为广度搜索方式。
“collect_mode” : “breadth_first”,
[ES官网]如果数据量越大,那么默认的使用深度优先的聚合模式生成的总分组数就会非常多,但是预估二级的聚合字段分组后的数据量相比总的分组数会小很多所以这种情况下使用广度优先的模式能大大节省内存,从而通过优化聚合模式来大大提高了在某些特定场景下聚合查询的成功率。
6、小结
待聚合的大小size取值越大,结果就越精确,而且计算最终结果的代价也越高;
耗时主要体现在:
第一:分片级别巨大的优先级队列的管理成本;
第二:集群节点和客户端之间的数据传输成本。
参考:
[1]Github解读:http://t.cn/RQpTzSH
[2]广度优先遍历:http://t.cn/RHndSgY
[3]分区聚合:http://t.cn/RQpTbdO
标签:存在 field 广度优先 巴巴 要求 案例 agg 速度慢 支持
原文地址:https://blog.51cto.com/14886891/2516008