标签:报表性能 ima 基于 str 额外 项目实施 大数据性能 数据库查询 oracl
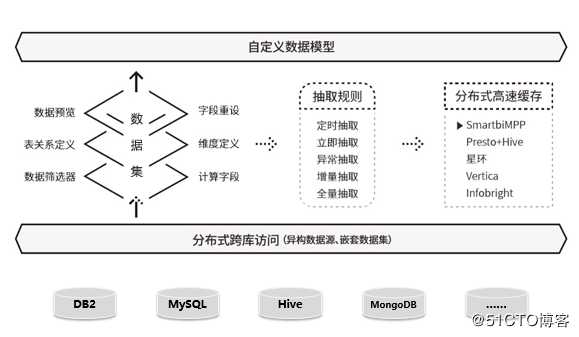
为什么需要跨库整合能力Smartbi支持多种数据源轻松接入,基本涵盖了市面上所有主流的数据库。无可否认多元的数据连接能力使Smartbi能快速连接现有数据源,构建统一的数据分析平台。但在项目实施过程中,往往会遇到以下的问题:
我们企业数据存储在不同甚至不同类型的数据库里面,当用户查询数据的范围比较广,并不限于一个数据库时,需要跨多个数据库进行关联查询分析,如果按照传统的方式:先抽取到要通过ETL把数据都抽取到统一的库中,就会十分费力。或是对现有业务代码进行重构,分别从两个数据库查询数据,然后在业务代码中进行join关联。数据库可能是分布在不同实例和不同的主机上,join关联将变得非常麻烦。
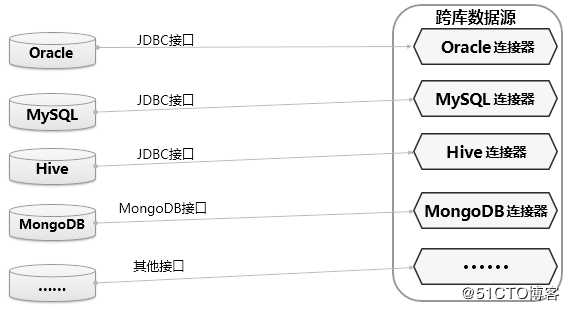
针对这种问题,smartbi提供跨库联合数据源(smartbiUnionDB):是系统内置数据源,用于实现跨库查询的需要。应对不同接口数据统一访问问题,无需再进行数据抽取。比如将Oracle和SQLServer两种数据源关联,让不同接口数据统一访问,无需再进行数据抽取。
跨库整合的功能
跨库联合数据源(smartbiUnionDB):是系统内置数据源,用于实现跨库查询的需要。系统自动将新建的关系数据源信息添加到该跨库联合数据源中,或通过数据库关联界面将需要的数据源手动添加,进行跨库查询时使用。
目前支持做跨库的数据源类型包括:高速缓存库、Hadoop_Hive、星环、Vertica、CH、Greenplum、Infobright、Oracle、DB2 V9、MySQL、MS SQL Server、Spark SQL、Teradata_v12、Informix、IMPALA、PostgreSQL。
跨库整合的亮点
Smartbi提供直接的跨库查询,并且内置了数据跨库查询引擎,在内存中进行关联,数据无需落地。省去了中间抽取环节,保证查询数据的实时性。
系统内置跨库引擎,不需额外安装部署。
对于海量大数据跨库查询,内置的跨库引擎能通过线性扩充,并行处理的方案,满足企业成长需要。
跨库数据源支持应用在数据集定义中,通常在可视化数据集和自助数据集中应用比较广泛。我们常规的这个数据分析底层结构是基于数据源直接连我们的数据连接进行数据的分析展现,那这种情况如果我们的数据量比较少的情况下一般是没有什么问题,但是我们的数据一旦达到某个级别之后我们的报表性能就会出现很大的一个瓶颈,甚至说导致我们的这个报表长时间刷不出来,以至于我们的系统崩溃,那这个时候就可以直接使用高速缓存库机制,以保证系统具有较长的生命力和扩展能力最重要保障。
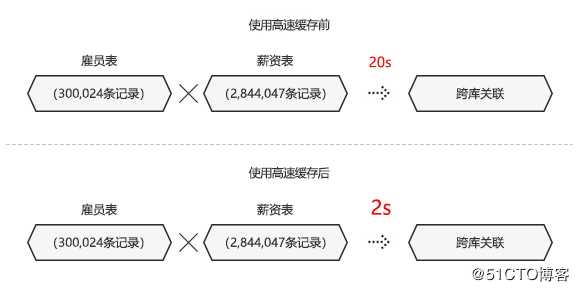
将数据抽取到高速缓存库后,之后的查询直接从高速缓存库取数,来提高查询性能。如在体验中心的“体验式场景5”在分析某公司的emplyees数据情况时,其中的雇员表(300,024条记录)与薪资表(2,844,047条记录)进行跨库关联,使用前高速缓存之前刷新数据至少要20秒;当数据抽取到高速缓存库后,切换年份刷新仅需2秒,甚至更快。
标签:报表性能 ima 基于 str 额外 项目实施 大数据性能 数据库查询 oracl
原文地址:https://blog.51cto.com/14787048/2516336