标签:会话 监控系统 网络 code 情况 其它 建议 通过 监控
作者:Umberto Manferdini 译者:TF编译组BGPaaS是允许虚拟机与Tungsten Fabric(注:原文为Contrail,本文以功能一致的Tungsten Fabric替换)进行BGP对话的一个功能。
请记住,Tungsten Fabric虚拟网络是存在于计算节点上的VRF。这些计算节点就像我们熟知的PE。同样,VM也可以被视为CE。在这种情况下,BGPaaS带来的BGP会话,就像我们在经典***中所具有的PE-CE协议一样。
使用BGPaaS的VM最多可以有2个邻居:VN网关(通常为.1)或VN服务地址(通常为.2)。
假设我有一个属于192.168.100.0/24的VM,其vmi(虚拟端口)地址是192.168.100.3。在这种情况下,如果在该端口上配置了BGPaaS,则VM可以建立2个BGP会话:一个指向192.168.100.1,另一个指向192.168.100.2。
即使BGP邻居地址是vRouter上的(“分布式”)IP,也不会在vRouter级别实现BGP逻辑。
Tungsten Fabric与Junos设备没有太大不同。例如,在MX中,控制平面和转发平面完全分离:路由引擎实现路由协议,而PFE实现转发功能。
同样,在Tungsten Fabric中,vRouter代表转发平面。控制平面位于Tungsten Fabric控制节点内。
因此,BGPaaS会话必须以某种方式到达控制节点。这可以通过让vRouter将任何BGPaaS会话代理到控制节点来实现。
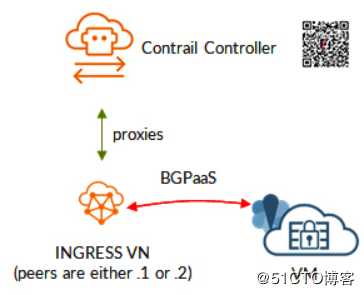
端到端的BGP会话是在VM和控制节点之间运行的。
在POC环境中,我们可能只有一个控制节点,因此所有BGPaaS会话都将被代理到该节点。
另一方面,在实际设置中,为了实现HA,我们将有3个控制节点。创建BGPaaS时,vRouter将使用哈希函数来确定会话必须代理到哪个控制节点。
这也意味着即使vRouter没有任何问题,控制节点故障也将导致BGP会话中断。
这也是为什么要建议,同时建立指向VN网关(gateway)和VN服务(service)地址的会话。这样,一个会话(到.1)将被代理到一个控制节点(例如control1),而另一个会话(到.2)将被代理到另一个控制节点(例如control2),从而使服务能够抵御控制节点的故障。
实际上的过程,比这要复杂一些。最佳解决方案需要一个称为控制节点区域(control node zone)的额外对象,但这不在本讨论的范围之内。
由于vRouter充当了代理角色,这意味着它将把端到端BGP会话分为两个会话:
– 一个在VM和vRouter之间
– 一个在vRouter和控制节点之间
为了端到端监视并解决出现的任何问题,将这两个会话链接起来就变得很重要。
通过introspect可以很容易地实现这一点。
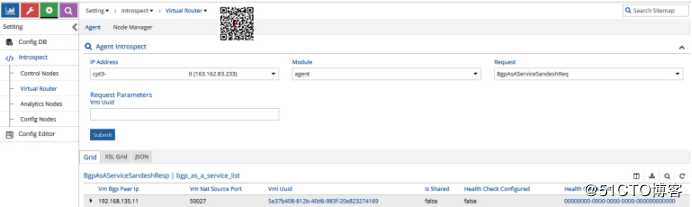
必须针对正确的计算节点运行“BgpAsAServiceSandeshReq”请求。这提供了在该计算节点上配置的BGPaaS对象的列表。
在返回的信息中,我们可以轻松地使用“Vm Nat Source Port”;在这种情况下为50027。
此外,虚拟机端口地址为192.168.135.11。
这足以将vm-vrouter会话映射到vrouter-control_node会话。
一旦知道了这些信息,就可以轻松地验证BGP数据包是否端到端流动。
我们可以通过在vRouter容器中使用vRouter cli实用程序“vifdump”,来检查在vrouter-vm会话上流动的数据包:
1.(vrouter-agent)[root@cpt3-dpdk?/]$?vifdump?-i?vif0/6?port?179?and?host?192.168.135.2??
2.vif0/6??????PMD:?tap5e37b408-81?NH:?80??
3.tcpdump:?verbose?output?suppressed,?use?-v?or?-vv?for?full?protocol?decode??
4.listening?on?mon6,?link-type?EN10MB?(Ethernet),?capture?size?262144?bytes??
5.09:47:15.762169?IP?192.168.135.2.bgp?>?192.168.135.11.11133:?Flags?[P.],?seq?2026783022:2026783041,?ack?1247350197,?win?210,?options?[nop,nop,TS?val?918606763?ecr?607079479],?length?19:?BGP??
6.09:47:15.784239?IP?192.168.135.2.bgp?>?192.168.135.11.11133:?Flags?[.],?ack?20,?win?210,?options?[nop,nop,TS?val?918606785?ecr?607082480],?length?0??
7.09:47:15.784246?IP?192.168.135.11.11133?>?192.168.135.2.bgp:?Flags?[P.],?seq?1:20,?ack?19,?win?8326,?options?[nop,nop,TS?val?607082480?ecr?918606763],?length?19:?BGP??接下来,我们执行相同的操作,但是是在计算节点物理接口vif0/0上执行。
在这里,我们可以捕获流量,并通过之前确定的“Vm Nat Source Port”对其进行过滤。
如果我们通过Wireshark分析捕获的流量,那么可以发现很多东西:
端点正在交换KEEPALIVE消息,表明会话状态良好。
这里关键的细节是IP端点:
– 163.162.83.233是计算节点的vhost0地址;
– 163.162.83.204是控制节点的地址。BGP被代理到了这个控制节点!
从Tungsten Fabric的角度来看,这使我们可以再次使用introspect来验证端到端BGPaaS会话工作正常。
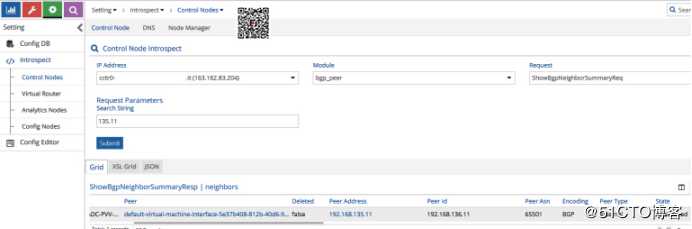
这次,我们对从wireshark抓包中识别出的控制节点运行自省请求。我们选择“bgp_peer”模块并请求“ShowBgpNeighborSummaryReq”。
幸运的是,会话状态已建立。
一切正常!这下没什么神秘的东西了~
Tungsten Fabric入门宝典系列文章——


标签:会话 监控系统 网络 code 情况 其它 建议 通过 监控
原文地址:https://blog.51cto.com/14638699/2516746