标签:案例 补充 实验 ica 换行 free har 写代码 函数调用
本实验分为三部分。第一部分集中在熟悉x86汇编语言,QEMU x86模拟器,以及PC的开机启动过程。第二部分考察6.828内核(即JOS)的启动加载器,它位于目录boot中。最后,第三部分深入研究JOS自身的初始模板,它位于目录kern中。我的实验环境是Ubuntu 18.04,安装课程所需要的软件工具很方便。
课程主页提供了很多x86汇编语言的资料,本人是在读完《x86汇编语言,从实模式到保护模式》[1]一书后再学习此课程的,该书面向使用Intel语法的NASM汇编器,而本课程面向使用AT&A语法的GNU汇编器,二者有一定的区别。但熟悉其中一种语法之后,再阅读另外一种也不成问题,详见文档提供的介绍二者语法差异的材料。在此,也强烈推荐对x86汇编和操作系统基础知识(我指的是感性认识,仅读过操作系统的理论书籍并不算)不熟悉的朋友将这本书作为6.828的先导资料仔细阅读。本实验中老师向学生强调C指针的重要性时有一段话,就像是对没读这本书之前学习6.828时饱受煎熬的我说的,我想把它不加修改地记录在这里:
If you do not really understand pointers in C, you will suffer untold pain and misery in subsequent labs, and then eventually come to understand them the hard way. Trust us; you don‘t want to find out what "the hard way" is.
我们使用QEMU模拟器与GDB调试器的组合,具体安装过程见课程网站。JOS初始模板的代码文件根目录是lab,我们先进入该目录,使用make命令编译JOS,编译完成后还会另外创建文件obj/kern/kernel.img,它是安装有JOS内核和启动加载器的虚拟硬盘映像。接下来我们在lab目录下执行命令make qemu,让QEMU从该虚拟硬盘启动JOS,效果如图1-1所示。目前我们的JOS内核只能执行help和kerninfo两个命令。
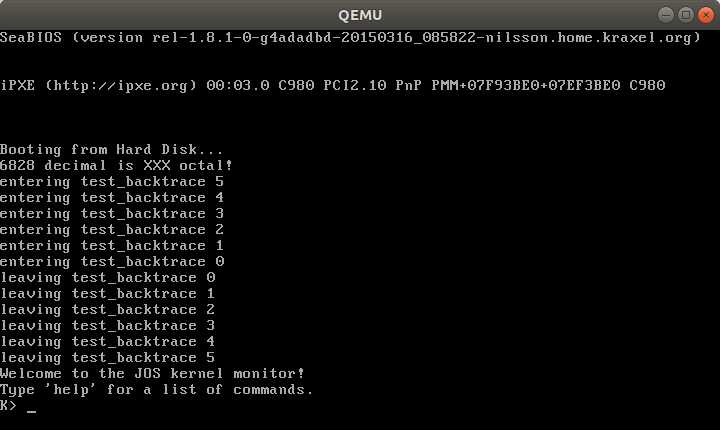
读过材料[1]后,这一节(以及后面多处)的知识就显得很简单了,也没必要翻译一遍,遂不赘述。
我们先启用调试功能。在lab目录下,打开两个shell,先在其中一个输入make qemu-gdb,这会启动虚拟机,但机器在执行第一条指令前停下,等待来自GDB的调试连接。然后,我们在第二个shell中输入make gdb,开始对QEMU进行调试,效果如图1-2所示。lab目录下有课程提供的.gdbinit文件("."开头的文件默认是不可见的),它设置了GDB调试器的工作方式,我们不深究,总而言之就是可以在图1-2所示的环境下对QEMU虚拟机进行调试了。
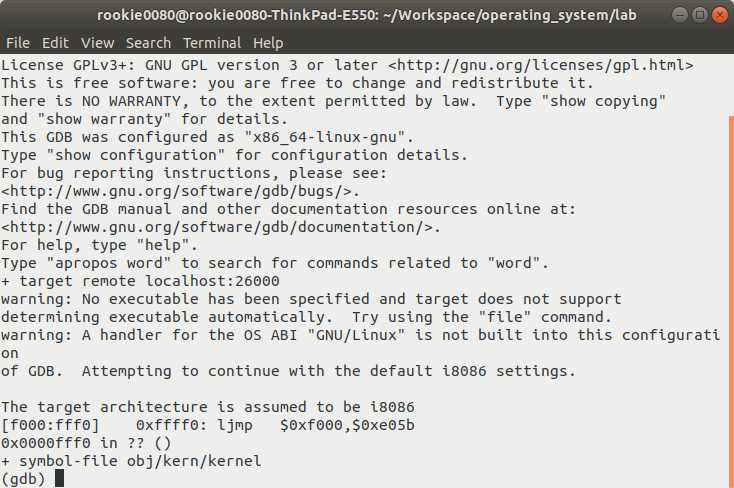
图中[f000:fff0] 0xffff0: ljmp $0xf000,$0xe05b 是GDB对将要执行的下一条机器指令反汇编的结果,该语句的意义和所涉及的相关知识在材料[1]中均有详细讲解,不再赘述。QEMU从BIOS ROM加载BIOS程序,初始化各个硬件设备,并搜寻第一个可启动的存储设备。在找到我们的虚拟硬盘后,QEMU从硬盘中加载启动加载程序,然后把控制权移交给它。
JOS使用传统的硬盘启动机制,所以我们的启动加载程序位于硬盘的第一个扇区内(512字节),它的源代码包括一个汇编语言文件boot/boot.S和一个C语言文件boot/main.c。启动加载程序需要完成两个任务,一是将处理器的工作模式由实模式转为32位保护模式,二是从硬盘加载JOS内核。obj/boot/boot.asm和obj/kern/kernel.asm是在JOS编译时根据编译完成的二进制文件反汇编得到的两个汇编程序,我们在调试时可以结合源文件与这两个汇编文件观察指令执行的情况。相关的GDB调试指令和练习参见课程网页和实验文档。
接下来,我们详细考察启动加载程序的C语言部分,即boot/main.c文件。要弄明白这个文件,我们需要了解一部分关于ELF格式的知识。我们只需要大致读一读关于ELF的标准规定[2]就够用了。
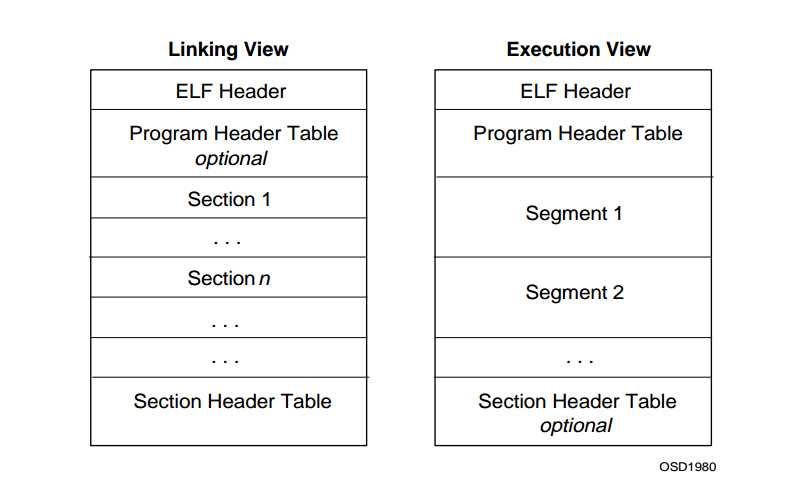
ELF是Linux以及其它类Unix系统的一种标准二进制文件格式,用于可执行文件、目标文件(object file)、共享库等(有的资料对object file的定义更广泛,包括以上三种文件[3])。当我们在Linux上编译C程序时,编译器将它们转换成符合硬件要求的二进制目标文件;接着链接器将这些目标文件组合成单个的二进制文件,如obj/kern/kernel,它就是一个具有ELF格式的可执行文件。ELF格式重要且复杂,但我们在课程中只需要用到很少的一部分。图2-1中分别给出了典型的可重定位ELF目标文件与可执行ELF文件的内部组织[2]。在6.828中我们只关注可执行的ELF文件。如图中所示,一个典型的可执行ELF文件最上面是ELF header(固定长度),它标识ELF文件的类型,指示文件内部是如何组织的,包括program header table和section header table(如有的话)的位置和大小等信息;紧随其后的是一个program header table,它对于可执行ELF文件是必须的,该表说明各个segment的相关属性,并指示文件应该如何加载到内存中;对于可执行文件来说,section header table是可选的。我们需要注意,图中所示仅仅是一个可执行ELF文件组织的典型案例。实际上,除了ELF header外,其余部分的分布并不是固定不变的,只要在ELF header中给出文件组织的相关信息即可。另外,一个segment可以包含多个section,二者只存在逻辑上的区别,加载程序以segment为单位。JOS的ELF格式比标准精简了很多,相关格式定义在一个C语言文件inc/elf.h中,我们可以对照材料[2]进行阅读。
我们使用命令objdump -h obj/kern/kernel来查看内核的ELF可执行文件中各个section的信息,结果如图2-2所示。我们比较关心的是.text,.rodata(read only data)和.data。另外,.bss并不占可执行文件的空间,链接器只将它的地址和大小等信息保存在文件内(未求证是否为section header中),因为该section中保存的数据全是0(比如未初始化和初始化为0的全局变量),所以安排让加载器将文件加载到内存后再分配相应的空间并清零。图中其它的section我们不用关心,它们中的大部分用于调试,并不会加载到内存中。
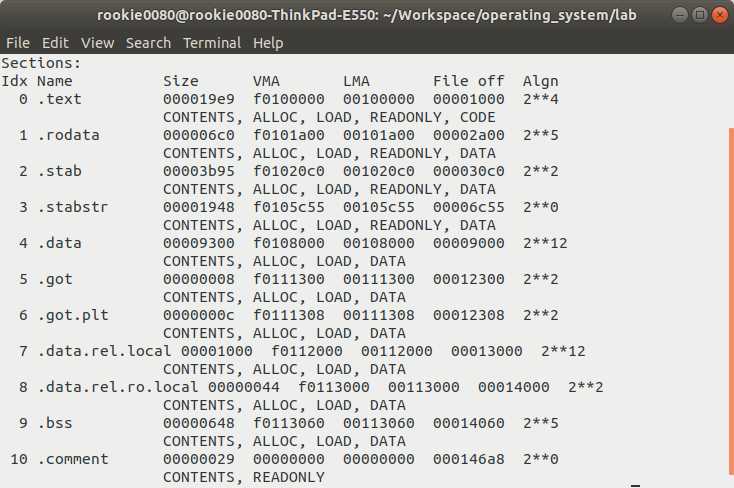
我们留意图2-2中所示的“VMA”和"LMA"两个字段。LMA(load address),即加载地址,是section加载到内存中的线性地址(当处理器未启用页机制时就是物理地址);VMA(link address),即链接地址,是进程映像在内存中执行时section的线性地址。大部分时候,它们两的值是相同的。材料[4]中给出了一个二者不相同的例子(材料[5]中也给出了一个类似的关于flash存储的例子):在一个基于ROM的系统中经常会出现这样的情况,某个数据section被加载到ROM中,但当程序开始执行时,这个section又会被加载到RAM中。在该情境下,section在ROM中的地址就是加载地址LMA,在RAM中的地址就是链接地址VMA。回到我们的JOS上来,由于操作系统会被加载到低址段,但是通过页机制运行在高址端(这又涉及不少知识,此处不便展开,参见材料[1]),所以此处.text的LMA为0x00100000,VMA为0xf0100000。
注意:所谓内核运行在高址端,是指在内核开始运行时,内核中的指令和数据就已经具有高端的线性地址了;所以内核在开启页机制前只使用物理地址而一定不能使用标号,因为加载到内存后,标号对应的地址是线性地址;而此时页硬件并不会将高端的线性地址映射到内核实际所在的物理地址的低址区域。因此,千万不能以为在开启页机制前,内核的线性地址就是低址区域的。图2-3很好地展示了这一点,在kernel.asm中,每一条指令的前面显示的都是指令加载到内存后的线性地址,可以看到它们位于VMA指示的0xf0100000之上。 Exersice 5就在引导我们思考这个问题。
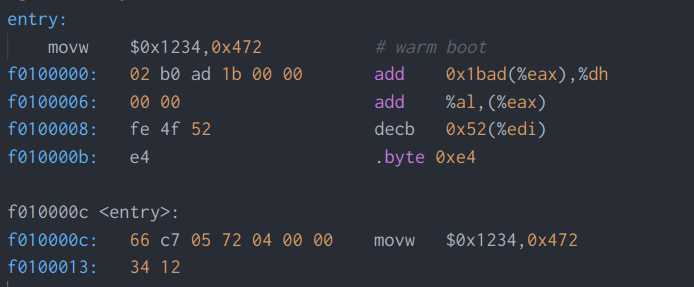
进入练习5之前,实验文档告诉我们:在/boot/Makefrag文件中,通过传递给链接器-TExt 0x7c00这个参数,使得链接器能够在生成的代码中产生正确的内存地址,练习让我们试图修改这个参数,看看boot loader运行是否会出错。这里所说的“内存地址”是指线性地址,因为BIOS默认会把boot loader加载到物理地址0x7c00并从该处开始执行;如果参数指示的是物理地址,那么进入boot loader后第一条指令就会出错,然而并没有。我将该参数修改为0x8c00,并通过make clean和make重新编译,发现反汇编生成的obj/boot/boot.asm文件中,线性地址被均被改动了,如图2-4所示。经过调试,发现boot loader执行到ljmp $PROT_MODE_CSEG, $protcseg这条指令时发生错误。之所以会这样,是因为boot loader在这里使用了标号protcseg,而标号使用的是线性地址!也就是说ljmp指令试图跳转到0x8c32处,但事实上那里可能根本不是一条合法的指令,它真正期望的目标指令位于0x7c32处。
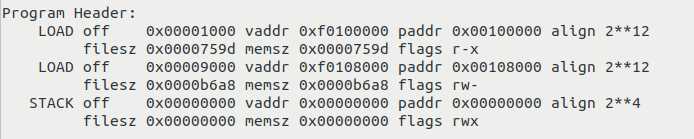
最后,命令objdump -x obj/kern/kernel可以查看到ELF文件的program header相关信息,如图2-5所示(命令还显示section和符号表信息,未予截图)。一个program header条目对应一个segment,所以内核可执行文件分为了三个segment;其中前两个标记为LOAD,它们将会被加载到内存。图中还显示了segment的线性地址vaddr和物理地址paddr,以及加载区域的大小、对齐、权限等信息,我们可以再一次认识到是program header table决定了程序如何被加载到内存中。对照图2-2我们不难发现,这里的第一个segment是从.text这个section开始的,第二个则是从.data开始的。segment的vaddr和.text的VMA值相同,我并不确定到底是哪一个真正决定了指令和数据在内存中的线性地址。
在这一部分中,我们需要写一些代码。
JOS使用PC物理地址空间的低端256MB,通过页机制将线性地址区间0xf0000000~0xfffffff映射到物理地址区间0x00000000~0x0fffffff(文档中仅使用map一词描述从物理地址到线性地址的方向,反方向称为translate,我认为问题不大)。出于某些原因(将在xv6 book Ch.2中介绍),我们在内核的入口代码entry.S只先创建两个映射关系,将线性地址区间0xf0000000~0xf0400000和0x00000000~0x00400000均映射到物理地址区间0x00000000~0x00400000。实际上这里只创建页目录,不会创建页表,页目录项会直接指向4MB的物理页。
在C语言中,很多人把printf视为是理所当然的,但事实上,它并不属于C语言本身,而是C语言标准库的一部分。printf是提供给用户程序员使用的,而非内核程序员,因为printf本身使用了操作系统内核提供的系统调用。绝大部分的标准库函数都使用了系统调用,所以开发内核时如果需要对应的功能只有自己去设计和实现。
我们需要稍微研究一下kern/printf.c、lib/printfmt.c和kern/console.c三个文件,练习8补充关于八进制打印的几行代码,参考十进制和十六进制的代码照葫芦画瓢很简单。现在我们来回答一下实验给出的几个问题。第2题中的代码是当信息在控制台窗口一屏显示不下时,将当前内容整体向上移一行,同时把最后一行清空,并把光标移到最后一行的起始位置。后面的几个问题需要参考lecture 2 note中关于GCC在x86上函数调用约定的相关知识。
int x = 1, y = 3, z = 4;
cprintf("x %d, y %x, z %d\n", x, y, z);
从实验文档下一小节我们可以知道,只需要把上面的代码放在monitor.c的monitor函数内就可以执行到了。monitor函数用于在JOS的shell窗口显示欢迎信息并准备执行用户输入的命令。我们通过b monitor.c:119(具体的行数当然不是固定的,调试方法亦然)设置断点并执行到cprintf调用之前,然后再设置断点b printf.c:32并单步执行到vcprintf调用之前。在这个位置,我们可以观察到在上面代码执行时,cprintf函数调用过程中参数fmt与ap指向的内容(经调试验证,在va_start函数执行后,无法马上通过p指令查看ap的值,暂不深究),调试信息如下图所示:
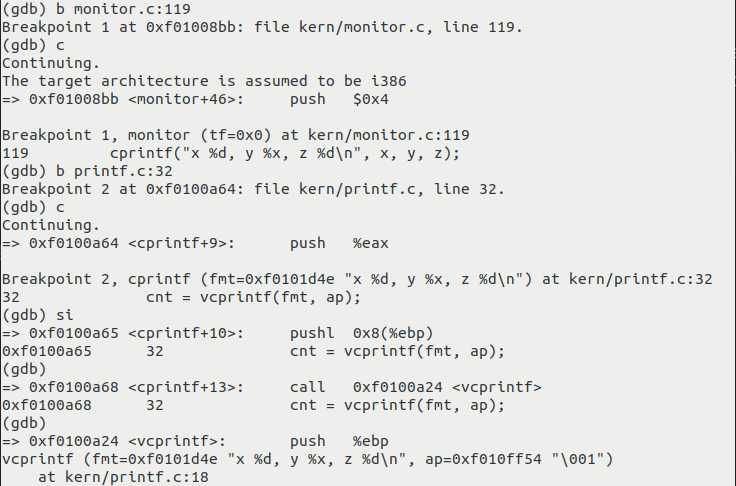
显然,fmt指向字符串"x %d, y %x, z %d\n"。而参数ap指向的内容是"\001",这是C语言的一种八进制数表示法,反斜杠后面接三个八进制数值;此处的ap是一个va_list可变参数列表(variable argument list),va_list以及可变参数列表相关的va_start、va_arg和va_end都是内置在GCC中的,我们在C语言程序中直接使用即可。
接下来我们检查在cprintf执行过程中,cons_putc、va_arg以及vcprintf的执行情况。我们对3个函数分别检查。对cons_putc,同样需要先设置断点b monitor.c:119锁定到目标cprintf语句;通过调试不难发现,cprintf的执行调用了14次cons_putc函数,每次输出一个字符(包括最后的\n换行符)。对va_arg,无法直接锁定va_arg函数本身(可能是由于它是GCC内置函数的缘故,我暂时没有找到有效的办法),只能通过判断哪些函数会调用到va_arg,从而间接锁定。也不难发现,这里的cprintf执行时,在printfmt.c中的getuint和getint两个函数会实际调用到va_arg。接下来浪费了我很多时间,决定详细记录下来:我开始试图通过getuint和getint的行数来设置断点,但在调试时始终不能在getuint处停下;后来发现kernel.asm中对应switch (ch = *(unsigned char *) fmt++) 这条语句的线性地址竟然有6处(猜测是由源码中的goto reswitch语句导致的)!而跟在后面的getuint相关代码也有不止一个版本,导致我通过行数定设置的断点被随机选定了一处,成为一个预料之外的断点。今后若通过行数设置断点一定要格外注意。最后我通过将断点定位在while ((ch = *(unsigned char *) fmt++) != ‘%‘处,然后通过单步和单语句调试慢慢执行到va_arg的位置。具体的调试过程不赘述了,总之,va_arg函数会使得ap指向可变参数列表中的下一个参数。关于vcprintf则没有什么可说的。
unsigned int i = 0x00646c72;
cprintf("H%x Wo%s", 57616, &i);
结果为he110 World,跟在字符h后面的是57616的十六进制表示0xe110。值0x00646c72采用小端法在内存中的存储形式为72 6c 64 00,当cprintf以字符串的形式读取它时,会在内存中逐字节读取,并以ASCII码形式输出,因此输出结果为依次为r、l、d。若在大端法存储的机器上,只需将i的值改为0x726c6400,而无须更改57616。
cprintf("x=%d y=%d", 3)的执行,x的输出正常;但在输出x后,ap被va_arg往后移动了4个字节(调试信息显示从0xf010ff64到0xf010ff68),而那里并没有被初始化过,因此该内存地址的内容是不确定的,导致y的输出异常。内核在entry.S中通过movl $(bootstacktop),%esp确定了栈顶的位置,从kernel.asm中知道实际传给寄存器esp的值为0xf010002f;另外,内核栈段的基址在boot.S中定义为0x0。所以内核栈以线性地址0xf010002f为栈顶,往低址端是栈的前进方向。
ebp基址寄存器让程序员可以从软件层面读写栈中的内容而不会影响栈指针的值。一个C函数被调用时,都会先保存调用者的ebp寄存器,然后将当前esp的值赋予ebp,我们可以利用这一机制来实现栈的回溯。
通过在练习10中调试test_backtrace函数,以及结合lecture2 note中关于C语言函数调用约定的相关内容,我们可以大致知道如何实现栈回溯。再次记录调试过程中几个花了很长时间的的地方:GDB的s和n调试命令是针对C语言源程序的,而si和ni是针对机器指令(汇编)的,正确使用调试指令真的非常重要;__x86.get_pc_thunk.bx的作用是获取它被调用的位置的下一条指令的地址,相当于用它来获取当前的eip,因为在32位x86上是无法直接读取eip的。
栈回溯的大致流程为:获取当前执行函数的ebp(通过read_ebp函数),根据ebp获得当前函数调用者的ebp和它传入的参数,以及当前函数的返回地址;接着用调用者的ebp重复前面的过程,直到ebp为0(在entry.S中设置的初始值)。
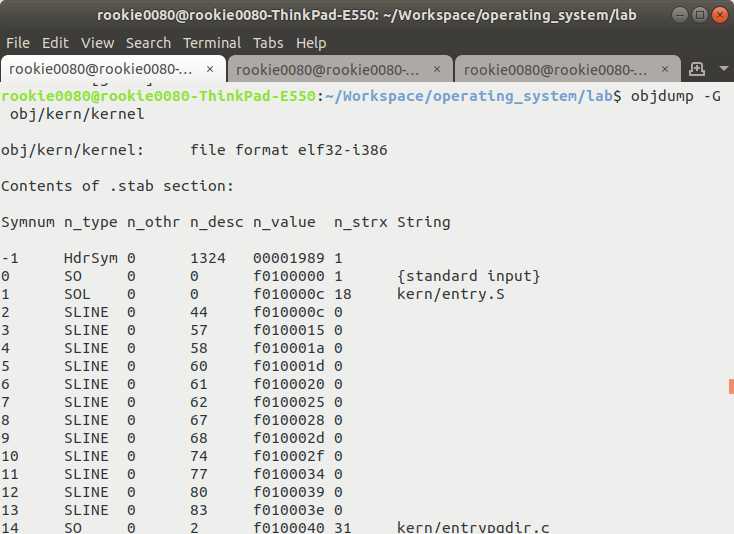
实现上述流程的难点在于,我们需要借助一个叫做.stab的section(可以通过bjdump -h obj/kern/kernel进行查看),而我们得清楚stab到底是什么。在此直接参阅资料[6],这是stab的格式文档,网上的多数中英文资料也是参考它的。同样地,我们只需要大致读一部分内容就够用了,这不会花很多时间。简单点说,stab格式是用来进行调试的,以本实验为例:编译器将C程序编译为.S汇编文件后,在汇编文件中包含了许多stab格式的汇编语句;接着汇编器会将.S程序翻译成.o目标文件,并将之前散落在汇编文件各处的stab语句集中存放在一个符号表和一个字符串表中;最后,链接器将所有.o文件组合成一个可执行文件,该文件中整合了所有.o文件的调试信息,将它们全部置于一个符号表和一个字符串表中,即.stab和.stabstr两个部分。启动加载器会把它们加载到内存中,这样才能用于调试。我们需要重点了解.stab这个section,通过objdump -G obj/kern/kernel可以查看其全部内容,如图3-2所示。.stab中内容的形式为一个结构数组,每一个元素就是一条调试信息。如图所示,Symnum是调试信息的索引;n_type是调试信息的类型,比如SO是程序源文件的调试信息,SLINE则是某一行语句的调试信息;n_value就是某个源文件、某个函数、某条语句在内存中的地址。详细的信息可以参考材料[6]。特别需要注意的是,在SLINE类型的调试信息中,n_desc就是该行在源文件中的行数,这在编写代码时会用到。
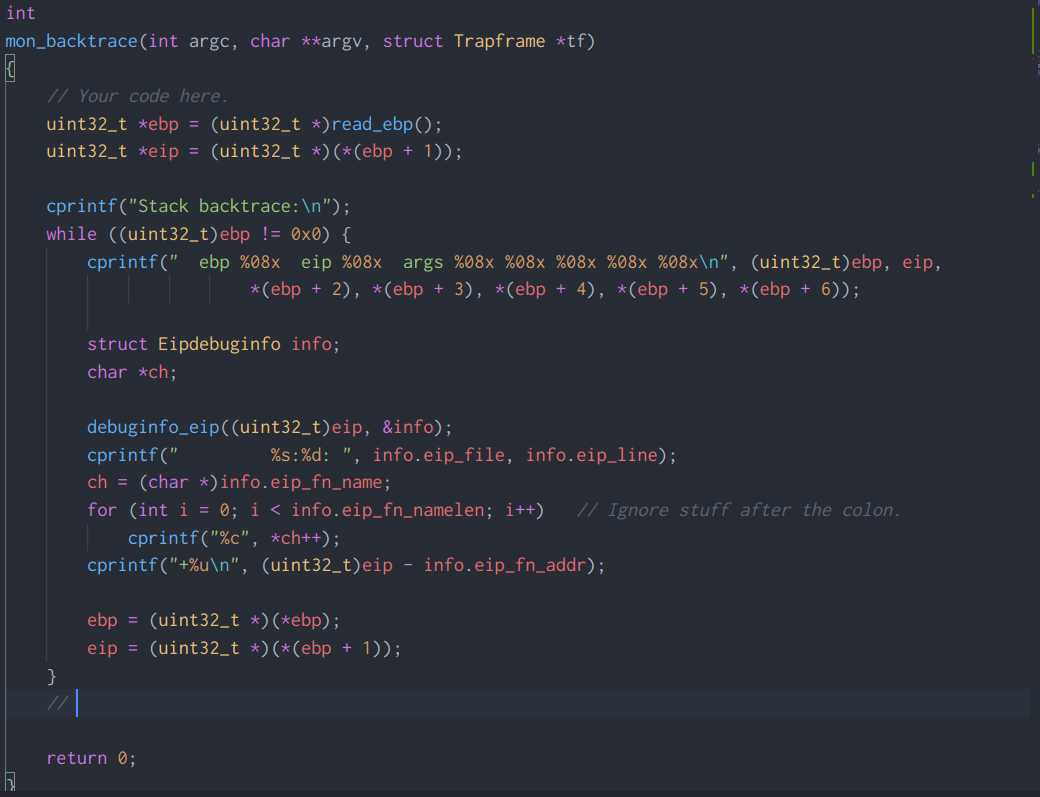
我们需要编写monitor.c文件中的mon_backtrace函数,输出ebp、eip和args相对简单;而在输出eip的源文件、文件内行数、函数名称、相对函数的偏移等调试信息时需要用到Eipdebuginfo结构体。另外,在补充kdebug.c中debuginfo_eip关于查找函数的代码时,会用到stab结构体中的n_desc。代码截图如下:

标签:案例 补充 实验 ica 换行 free har 写代码 函数调用
原文地址:https://www.cnblogs.com/rookie0080/p/13436829.html