标签:anti 上下 支持 保留 operation dex文件 topic src skiplist
Kafka消息以日志文件的形式存储,不同主题下不同分区的消息分开存储,同一个分区的不同副本分布在不同的broker上存储
逻辑上看来日志是以副本为单位的,每个副本对应一个log对象,实际在物理上,一个log划分为多个logSegment
创建一个topic为3个分区,会在log.dirs路径下创建三个文件夹,代表3个分区,命名规则为“topic名称-分区编号”
logSegment并不代表这个文件夹,logSegment代表逻辑上的一组文件,这组文件就是.log、.index、.timeindex这三个不同文件扩展名,但是同文件名的文件
同一个logSegment的三个文件,文件名是一样的。命名规则为.log文件中第一条消息的前一条消息偏移量,也称为基础偏移量,左边补0,补齐20位。比如说第一个LogSegement的日志文件名为00000000000000000000.log,假如存储了200条消息后,达到了log.segment.bytes配置的阈值(默认1个G),那么将会创建新的logSegment,文件名为00000000000000000200.log。以此类推。另外即使没有达到log.segment.bytes的阈值,而是达到了log.roll.ms或者log.roll.hours设置的时间触发阈值,同样会触发产生新的logSegment。
日志定位也就是消息定位,输入一个消息的offset,kafka如何定位到这条消息呢?
日志定位的过程如下:
1、根据offset定位logSegment。(kafka将基础偏移量也就是logsegment的名称作为key存在concurrentSkipListMap中)
2、根据logSegment的index文件查找到距离目标offset最近的被索引的offset的position x。
3、找到logSegment的.log文件中的x位置,向下逐条查找,找到目标offset的消息。
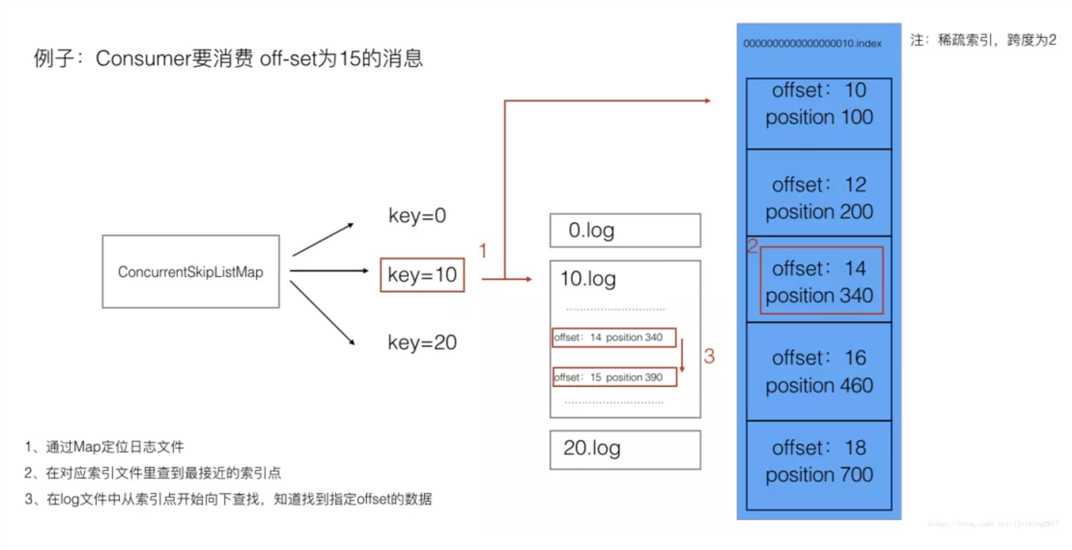
这里先说明一下.index文件的存储方式。.index文件中存储了消息的索引,存储内容是消息的offset及物理位置position。并不是每条消息都有自己的索引,kafka采用的是稀疏索引,说白了就是隔n条消息存一条索引数据。这样做比每一条消息都建索引,查找起来会慢,但是也极大的节省了存储空间。此例中我们假设跨度为2,实际kafka中跨度并不是固定条数,而是取决于消息累积字节数大小。
例子中consumer要消费offset=15的消息。我们假设目前可供消费的消息已经存储了三个logsegment,分别是00000000000000000,0000000000000000010,0000000000000000020。为了讲解方便,下面提到名称时,会把前面零去掉。
下面我们详细讲一下查找过程。
可以看到通过稀疏索引,kafka既加快了消息查找的速度,也顾及了存储的开销
Kafka提供了两种日志清理的方式:
1.日志删除(Log Retention):直接删除
2.日志压缩(Log Compaction):对相同key的不同value值,只保留最后一个版本
通过log.cleanup.policy参数来设置清理策略,默认值为"delete",如果要设置为压缩,需要改为"compact",还可以同时支持两种策略
根据日志分段中最大的时间戳来查找过期的日志分段文件
检查当前日志大小是否超过retentionSize,默认值为-1,表示无穷大,该值代表所有日志文件的总大小,不是单个日志分段的大小,单个日志分段大小默认为1GB
判断某个日志分段的下一个日志分段的起始偏移量baseOffset是否小于等于logStartOffset
页缓存是操作系统实现的一种主要的磁盘缓存,用来减少对磁盘I/O的操作,将磁盘中的数据缓存到内存中,将对磁盘的访问转变为对内存的访问
当一个进程准备读取磁盘上的文件内容时,操作系统会首先查看待读取的数据所在的页是否在页缓存中,如果在直接返回数据,如果没有,操作系统会向磁盘发起读取请求并将读取的数据页存入页缓存,再将数据返回,写入的时候也是类似
优点:对于进程而言,会在进程内部缓存数据,同时有可能这些数据缓存在操作系统的页缓存中,被缓存了两次,使用页缓存可以省去进程内部的缓存消耗,还可以通过结构紧凑的字节码替代使用对象的方式节省更多空间,假设服务重启页缓存还是保持有效
Kafka大量使用了页缓存,这是Kafka实现高吞吐的重要因素之一。在Kafka中提供了同步刷盘和间断性强制刷盘的功能,但不建议使用,因为会严重影响性能
Linux系统使用磁盘的一部分作为swap分区,把非活跃进程放入swap分区,对于Kafka而言,应该避免这种内存的交换,否则会影响性能,建议把vm.swappiness值设为1,保留了该机制又使得它对Kafka的影响最小
I/O调度策略:
1.NOOP
No Operation,I/O请求大致按照先来后到顺序进行操作,做了相邻I/O请求的合并
2.CFQ
Completely Fair Queuing(默认),按照I/O请求地址进行排序
3.DEADLINE
除了CFQ本身具有的I/O队列,还为读I/O和写I/O提供了FIFO队列
4.ANTICIPATORY
满足随机I/O和顺序I/O混合的场景
将数据直接从磁盘文件复制到网卡设备中,不需要经过应用程序,减少了内核和用户态之间的上下文切换,依赖sendFile()方法实现
通过DMA(Direct Memory Access)方式数据只需要复制2次,上下文切换也只需要两次,零拷贝是针对内核模式的
标签:anti 上下 支持 保留 operation dex文件 topic src skiplist
原文地址:https://www.cnblogs.com/jordan95225/p/13437110.html