栈 stack
栈(stack)又名堆栈,它是一种运算受限的线性表。限定仅在表尾进行插入和删除操作的线性表。这一端被称为栈顶,把另一端称为栈底。向一个栈插入新元素又称作 进栈、入栈或压栈,它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素;从一个栈删除元素又称作出栈或退栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。栈作为一种数据结构,是一种只能在一端进行插入和删除操作的特殊线性表。它按照先进后出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据(最后一个数据被第一个读出来)。栈具有记忆作用,对栈的插入与删除操作中,不需要改变栈底指针。栈是允许在同一端进行插入和删除操作的特殊线性表。允许进行插入和删除操作的一端称为栈顶(top),另一端为栈底(bottom);栈底固定,而栈顶浮动;栈中元素个数为零时称为空栈。插入一般称为进栈(PUSH),删除则称为退栈(POP)。栈也称为先进后出表。
栈可以用来在函数调用的时候存储断点,做递归时要用到栈!
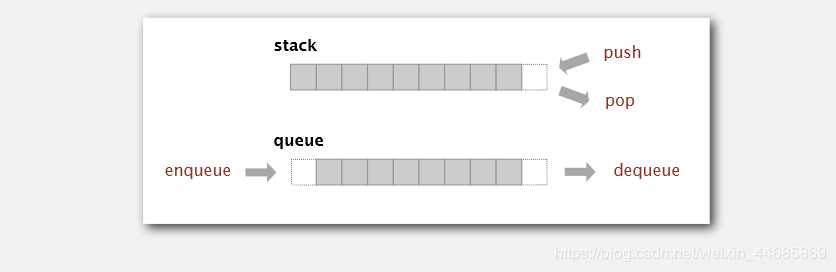
栈的特点:
后进先出,最后插入的元素最先出来。
Python实现

# 栈的顺序表实现 class Stack(object): def __init__(self): self.items = [] def isEmpty(self): return self.items == [] def push(self, item): return self.items.append(item) def pop(self): return self.items.pop() def top(self): return self.items[len(self.items)-1] def size(self): return len(self.items) if __name__ == ‘__main__‘: stack = Stack() stack.push("Hello") stack.push("World") stack.push("!") print(stack.size()) print(stack.top()) print(stack.pop()) print(stack.pop()) print(stack.pop()) # 结果 3 ! ! World Hello
# 栈的链接表实现 class SingleNode(object): def __init__(self, item): self.item = item self.next = None class Stack(object): def __init__(self): self._head = None def isEmpty(self): return self._head == None def push(self, item): node = SingleNode(item) node.next = self._head self._head = node def pop(self): cur = self._head self._head = cur.next return cur.item def top(self): return self._head.item def size(self): cur = self._head count = 0 while cur != None: count += 1 cur = cur.next return count if __name__ == ‘__main__‘: stack = Stack() stack.push("Hello") stack.push("World") stack.push("!") print(stack.size()) print(stack.top()) print(stack.pop()) print(stack.pop()) print(stack.pop()) # 结果 3 ! ! World Hello
队列
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。队列中没有元素时,称为空队列。
队列的数据元素又称为队列元素。在队列中插入一个队列元素称为入队,从队列中删除一个队列元素称为出队。因为队列只允许在一端插入,在另一端删除,所以只有最早进入队列的元素才能最先从队列中删除,故队列又称为先进先出(FIFO—first in first out)线性表.
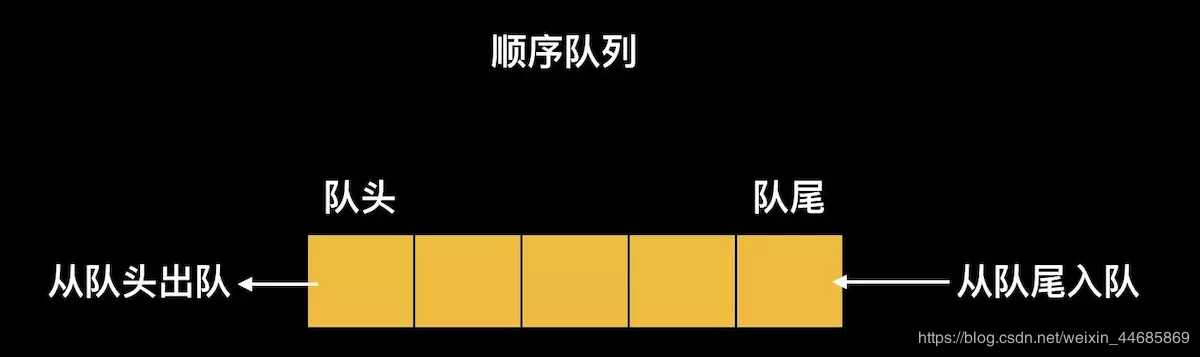
队列的特点:
先进者先出,最先插入的元素最先出来。
我们可以想象成,排队买票,先来的先买,后来的只能在末尾,不允许插队。
队列的两个基本操作:入队 将一个数据放到队列尾部;出队 从队列的头部取出一个元素。队列也是一种操作受限的线性表数据结构 它具有先进先出的特性,支持队尾插入元素,在队头删除元素。
队列的概念很好理解,队列的应用也非常广泛如:循环队列、阻塞队列、并发队列、优先级队列等。下面将会介绍。
顺序队列:
顺序队列就是我们常说的 “FIFO”(先进先出)队列,它主要包括的方法有:取第一个元素(first方法)、进入队列(enqueue方法)、出队列(dequeue方法)、清空队列(clear方法)、判断队列是否为空(empty方法)、获取队列长度(length方法),具体的实现看下面的源代码。同样,这里在取队列的第一个元素、以及出队列的时候,也需要判断下队列是否为空。
class Queue: """ 顺序队列实现 """ def __init__(self): """ 初始化一个空队列,因为队列是私有的 """ self.__queue = [] def first(self): """ 获取队列的第一个元素 :return:如果队列为空,则返回None,否则返回第一个元素 """ return None if self.isEmpty() else self.__queue[0] def enqueue(self, obj): """ 将元素加入队列 :param obj:要加入队列的对象 """ self.__queue.append(obj) def dequeue(self): """ 从队列中删除第一个元素 :return:如果队列为空,则返回None,否则返回dequeued元素 """ return None if self.isEmpty() else self.__queue.pop(0) def clear(self): """ 清除整个队列 """ self.__queue.clear() def isEmpty(self): """ 判断队列是否为空 返回:bool值 """ return self.length() == 0 def length(self): """ 获取队列长度 并返回 """ return len(self.__queue)
优先队列:
优先队列简单说就是一个有序队列,排序的规则就是自定义的优先级大小。在下面的代码实现中,主要使用的是数值大小进行比较排序,数值越小则优先级越高,理论上应该把优先级高的放在队列首位。值得注意的是,笔者这里用list来实现的时候恰好顺序是反的,即list中元素是从大到小的顺序,这样做的好处是取队列的第一个元素、以及出队列这两个操作的时间复杂度为O(1),仅仅入队列操作的时间复杂度为O(n)。如果是按照从小到大的顺序,那么将会产生两个时间复杂度为O(n),一个时间复杂度为O(1)。
class PriorQueue: """ 优先队列实现 """ def __init__(self, objs=[]): """ 初始化优先队列,默认队列为空 :参数objs:对象列表初始化 """ self.__prior_queue = list(objs) # 排序从最大值到最小值,最小值具有最高的优先级 # 使得“dequeue”的效率为O(1) self.__prior_queue.sort(reverse=True) def first(self): """ 获取优先队列的最高优先级元素O(1) :return:如果优先队列为空,则返回None,否则返回优先级最高的元素 """ return None if self.isEmpty() else self.__prior_queue[-1] def enqueue(self, obj): """ 将一个元素加入优先队列,O(n) :param obj:要加入队列的对象 """ index = self.length() while index > 0: if self.__prior_queue[index - 1] < obj: index -= 1 else: break self.__prior_queue.insert(index, obj) def dequeue(self): """ 从优先队列中取出最高优先级的元素,O(1) :return:如果优先队列为空,则返回None,否则返回dequeued元素 """ return None if self.isEmpty() else self.__prior_queue.pop() def clear(self): """ 清除整个优先队列 """ self.__prior_queue.clear() def isEmpty(self): """ 判断优先队列是否为空 返回:bool值 """ return self.length() == 0 def length(self): """ 获取优先队列的长度 返回: """ return len(self.__prior_queue)
循环队列:
循环队列,就是将普通的队列首尾连接起来, 形成一个环状,并分别设置首尾指针,用来指明队列的头和尾。每当我们插入一个元素,尾指针就向后移动一位,当然,在这里我们队列的最大长度是提前定义好的,当我们弹出一个元素,头指针就向后移动一位。
这样,列表中就不存在删除操作,只有修改操作,从而避免了删除前面节点造成的代价大的问题。
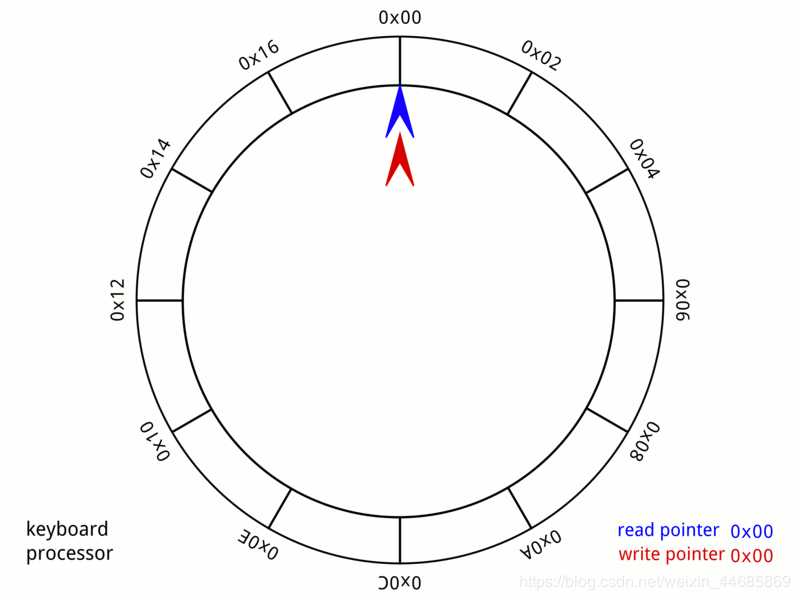
class Loopqueue: ‘‘‘ 循环队列实现 ‘‘‘ def __init__(self, length): self.head = 0 self.tail = 0 self.maxSize = length self.cnt = 0 self.__list = [None]*length def __len__(self): ‘‘‘ 定义长度 ‘‘‘ return self.cnt def __str__(self): ‘‘‘ 定义返回值 类型 ‘‘‘ s = ‘‘ for i in range(self.cnt): index = (i + self.head) % self.maxSize s += str(self.__list[index])+‘ ‘ return s def isEmpty(self): ‘‘‘ 判断是否为空 ‘‘‘ return self.cnt == 0 def isFull(self): ‘‘‘ 判断是否装满 ‘‘‘ return self.cnt == self.maxSize def push(self, data): ‘‘‘ 添加元素 ‘‘‘ if self.isFull(): return False if self.isEmpty(): self.__list[0] = data self.head = 0 self.tail = 0 self.cnt = 1 return True self.tail = (self.tail+1)%self.maxSize self.cnt += 1 self.__list[self.tail] = data return True def pop(self): ‘‘‘ 弹出元素 ‘‘‘ if self.isEmpty(): return False data = self.__list[self.head] self.head = (self.head+1)%self.maxSize self.cnt -= 1 return data def clear(self): ‘‘‘ 清空队列 ‘‘‘ self.head = 0 self.tail = 0 self.cnt = 0 return True
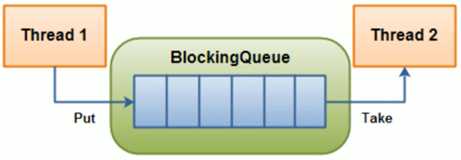
阻塞队列
阻塞队列是一个在队列基础上又支持了两个附加操作的队列。
阻塞(并发)队列与普通队列的区别在于,当队列是空的时,从队列中获取元素的操作将会被阻塞,或者当队列是满时,往队列里添加元素的操作会被阻塞。试图从空的阻塞队列中获取元素的线程将会被阻塞,直到其他的线程往空的队列插入新的元素。同样,试图往已满的阻塞队列中添加新元素的线程同样也会被阻塞,直到其他的线程使队列重新变得空闲起来,如从队列中移除一个或者多个元素,或者完全清空队列.
2个附加操作:
支持阻塞的插入方法:队列满时,队列会阻塞插入元素的线程,直到队列不满。
支持阻塞的移除方法:队列空时,获取元素的线程会等待队列变为非空。
怎么实现阻塞队列?当然是靠锁,但是应该怎么锁?一把锁能在not_empty,not_full,all_tasks_done三个条件之间共享。好比说,现在有线程A线程B,他们准备向队列put任务,队列的最大长度是5,线程A在put时,还没完事,线程B就开始put,队列就塞不下了,所以当线程A抢占到put权时应该加把锁,不让线程B对队列操作。鬼畜区经常看到的计数君,在线程中也同样重要,每次put完unfinished要加一,get完unfinished要减一。
import threading #引入线程 上锁 import time from collections import deque # 导入队列 class BlockQueue: def __init__(self, maxsize=0): ‘‘‘ 一把锁三个条件(self.mutex,(self.not_full, self.not_empty, self.all_task_done)), 最大长度与计数君(self.maxsize,self.unfinished) ‘‘‘ self.mutex = threading.Lock() # 线程上锁 self.maxsize = maxsize self.not_full = threading.Condition(self.mutex) self.not_empty = threading.Condition(self.mutex) self.all_task_done = threading.Condition(self.mutex) self.unfinished = 0 def task_done(self): ‘‘‘ 每一次put完都会调用一次task_done,而且调用的次数不能比队列的元素多。计数君对应的方法, unfinished<0时的意思是调用task_done的次数比列表的元素多,这种情况就会抛出异常。 ‘‘‘ with self.all_task_done: unfinish = self.unfinished - 1 if unfinish <= 0: if unfinish < 0: raise ValueError("The number of calls to task_done() is greater than the number of queue elements") self.all_task_done.notify_all() self.unfinished = unfinish def join(self): ‘‘‘ 阻塞方法,是一个十分重要的方法,但它的实现也不难,只要没有完成任务就一直wait(), 就是当计数君unfinished > 0 时就一直wait()知道unfinished=0跳出循环。 ‘‘‘ with self.all_task_done: while self.unfinished: self.all_task_done.wait() def put(self, item, block=True, timeout=None): ‘‘‘ block=True一直阻塞直到有一个空闲的插槽可用,n秒内阻塞,如果在那个时间没有空闲的插槽,则会引发完全的异常。 Block=False如果一个空闲的槽立即可用,则在队列上放置一个条目,否则就会引发完全的异常(在这种情况下,“超时”将被忽略)。 有空位,添加到队列没结束的任务+1,他最后要唤醒not_empty.notify(),因为一开始是要在没满的情况下加锁,满了就等待not_full.wait, 当put完以后就有东西了,每当一个item被添加到队列时,通知not_empty等待获取的线程会被通知。 ‘‘‘ with self.not_full: if self.maxsize > 0: if not block: if self._size() >= self.maxsize: raise Exception("The BlockQueue is full") elif timeout is not None: self.not_full.wait() elif timeout < 0: raise Exception("The timeout period cannot be negative") else: endtime = time.time() + timeout while self._size() >= self.maxsize: remaining = endtime - time.time() if remaining <= 0.0: raise Exception("The BlockQueue is full") self.not_full.wait(remaining) self.queue.append(item) self.unfinished += 1 self.not_empty.notify() def get(self, block=True, timeout=None): ‘‘‘ 如果可选的args“block”为True,并且timeout是None,则在必要时阻塞,直到有一个项目可用为止。 如果“超时”是一个非负数,它会阻塞n秒,如果在那个时间内没有可get()的项,则会抛出空异常。 否则‘block‘是False,如果立即可用,否则就会抛出空异常,在这种情况下会忽略超时。 同理要唤醒not_full.notify ‘‘‘ with self.not_empty: if not block: if self._size() <= 0: raise Exception("The queue is empty and you can‘t call get ()") elif timeout is None: while not self._size(): self.not_empty.wait() elif timeout < 0: raise ValueError("The timeout cannot be an integer") else: endtime = time.time() + timeout remaining = endtime - time.time() if remaining <= 0.0: raise Exception("The BlockQueue is empty") self.not_empty.wait(remaining) item = self._get() self.not_full.notify() return item
并发队列:
在并发队列上JDK提供了两套实现,
一个是以ConcurrentLinkedQueue为代表的高性能队列非阻塞,
一个是以BlockingQueue接口为代表的阻塞队列,无论哪种都继承自Queue。
链式队列:
链式队列在创建一个队列时,队头指针front和队尾指针rear指向结点的data域和next域均为空。
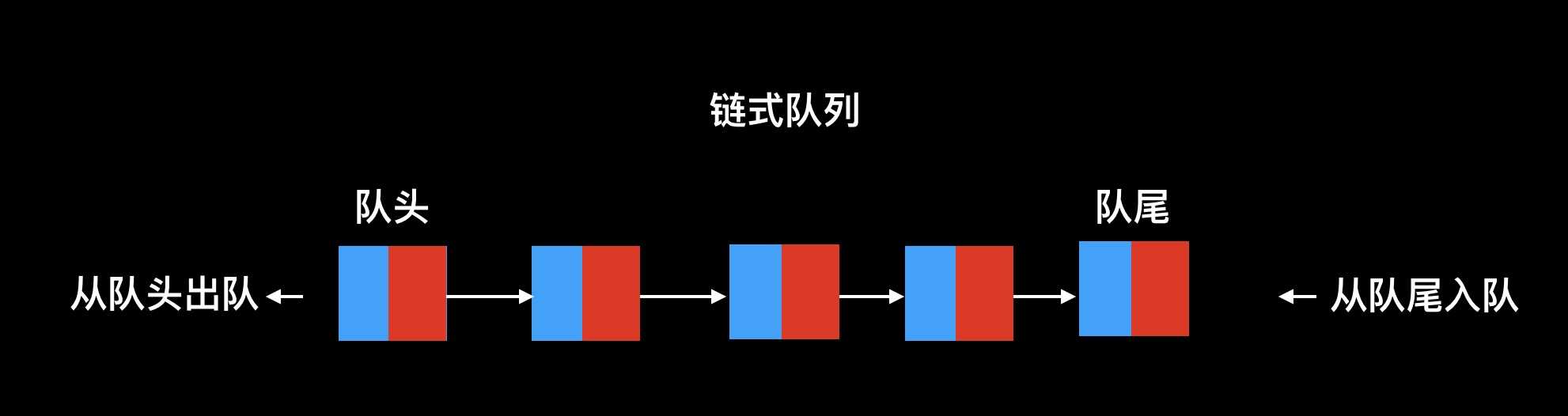
class QueueNode(): def __init__(self): self.data = None self.next = None class LinkQueue(): def __init__(self): tQueueNode = QueueNode() self.front = tQueueNode self.rear = tQueueNode ‘‘‘判断是否为空‘‘‘ def IsEmptyQueue(self): if self.front == self.rear: iQueue = True else: iQueue = False return iQueue ‘‘‘进队列‘‘‘ def EnQueue(self,da): tQueueNode = QueueNode() tQueueNode.data = da self.rear.next = tQueueNode self.rear = tQueueNode print("当前进队的元素为:",da) ‘‘‘出队列‘‘‘ def DeQueue(self): if self.IsEmptyQueue(): print("队列为空") return else: tQueueNode = self.front.next self.front.next = tQueueNode.next if self.rear == tQueueNode: self.rear = self.front return tQueueNode.data def GetHead(self): if self.IsEmptyQueue(): print("队列为空") return else: return self.front.next.data def CreateQueueByInput(self): data = input("请输入元素(回车键确定,#结束)") while data != "#": self.EnQueue(data) data = input("请输入元素(回车键确定,#结束)") ‘‘‘遍历顺序队列内的所有元素‘‘‘ def QueueTraverse(self): if self.IsEmptyQueue(): print("队列为空") return else: while self.front != self.rear: result = self.DeQueue() print(result,end = ‘ ‘) lq = LinkQueue() lq.CreateQueueByInput() print("队列里元素为:") lq.QueueTraverse() # 结果 请输入元素(回车键确定,#结束)5 当前进队的元素为:5 请输入元素(回车键确定,#结束)8 当前进队的元素为:8 请输入元素(回车键确定,#结束)9 当前进队的元素为:9 请输入元素(回车键确定,#结束)# 队列的元素为: 5 8 9
链表
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。 相比于线性表顺序结构,操作复杂。由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而线性表和顺序表相应的时间复杂度分别是O(logn)和O(1)。
链表是一种物理存储结构上非连续,非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。

链表的结构是多式多样的,当时通常用的也就是两种:

无头单向非循环列表:结构简单,一般不会单独用来存放数据。实际中更多是作为其他数据结构的子结构,比如说哈希桶等等。
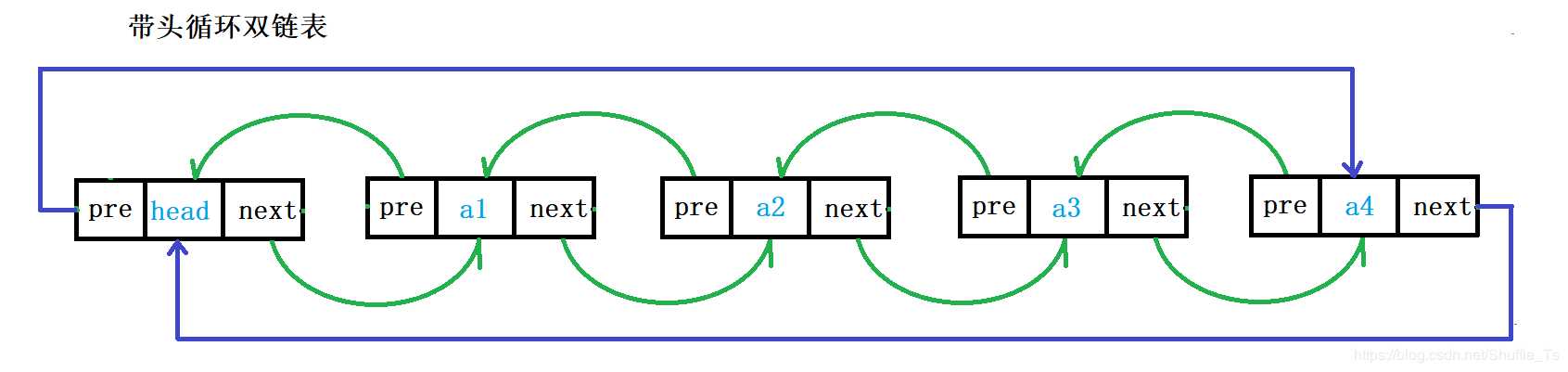
带头双向循环链表:结构最复杂,一般单独存储数据。实际中经常使用的链表数据结构,都是带头双向循环链表。这个结构虽然复杂,但是使用代码实现后会发现这个结构会带来很多优势,实现反而简单了。
链表的优点
插入和删除的效率高,只需要改变指针的指向就可以进行插入和删除。
内存利用率高,不会浪费内存,可以使用内存中细小的不连续的空间,只有在需要的时候才去创建空间。大小不固定,拓展很灵活。
链表的缺点
查找的效率低,因为链表是从第一个节点向后遍历查找。
单向链表
单向链表(单链表)是链表的一种,其特点是链表的链接方向是单向的,对链表的访问要通过顺序读取从头部开始;链表是使用指针进行构造的列表;又称为结点列表,因为链表是由一个个结点组装起来的;其中每个结点都有指针成员变量指向列表中的下一个结点;列表是由结点构成,head指针指向第一个成为表头结点,而终止于最后一个指向NULL的指针。

单链表的每一个节点中只有指向下一个结点的指针,不能进行回溯,适用于节点的增加和删除。
class Node(object): """节点""" def __init__(self, elem): self.elem = elem self.next = None # 初始设置下一节点为空 ‘‘‘ 上面定义了一个节点的类,当然也可以直接使用python的一些结构。比如通过元组(elem, None) ‘‘‘ # 下面创建单链表,并实现其应有的功能 class SingleLinkList(object): """单链表""" def __init__(self, node=None): # 使用一个默认参数,在传入头结点时则接收,在没有传入时,就默认头结点为空 self.__head = node def is_empty(self): ‘‘‘链表是否为空‘‘‘ return self.__head == None def length(self): ‘‘‘链表长度‘‘‘ # cur游标,用来移动遍历节点 cur = self.__head # count记录数量 count = 0 while cur != None: count += 1 cur = cur.next return count def travel(self): ‘‘‘遍历整个列表‘‘‘ cur = self.__head while cur != None: print(cur.elem, end=‘ ‘) cur = cur.next print("\n") def add(self, item): ‘‘‘链表头部添加元素‘‘‘ node = Node(item) node.next = self.__head self.__head = node def append(self, item): ‘‘‘链表尾部添加元素‘‘‘ node = Node(item) # 由于特殊情况当链表为空时没有next,所以在前面要做个判断 if self.is_empty(): self.__head = node else: cur = self.__head while cur.next != None: cur = cur.next cur.next = node def insert(self, pos, item): ‘‘‘指定位置添加元素‘‘‘ if pos <= 0: # 如果pos位置在0或者以前,那么都当做头插法来做 self.add(item) elif pos > self.length() - 1: # 如果pos位置比原链表长,那么都当做尾插法来做 self.append(item) else: per = self.__head count = 0 while count < pos - 1: count += 1 per = per.next # 当循环退出后,pre指向pos-1位置 node = Node(item) node.next = per.next per.next = node def remove(self, item): ‘‘‘删除节点‘‘‘ cur = self.__head pre = None while cur != None: if cur.elem == item: # 先判断该节点是否是头结点 if cur == self.__head: self.__head = cur.next else: pre.next = cur.next break else: pre = cur cur = cur.next def search(self, item): ‘‘‘查找节点是否存在‘‘‘ cur = self.__head while not cur: if cur.elem == item: return True else: cur = cur.next return False if __name__ == "__main__": # node = Node(100) # 先创建一个节点传进去 ll = SingleLinkList() print(ll.is_empty()) print(ll.length()) ll.append(3) ll.add(999) ll.insert(-3, 110) ll.insert(99, 111) print(ll.is_empty()) print(ll.length()) ll.travel() ll.remove(111) ll.travel()
双向链表
双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。一般我们都构造双向循环链表。
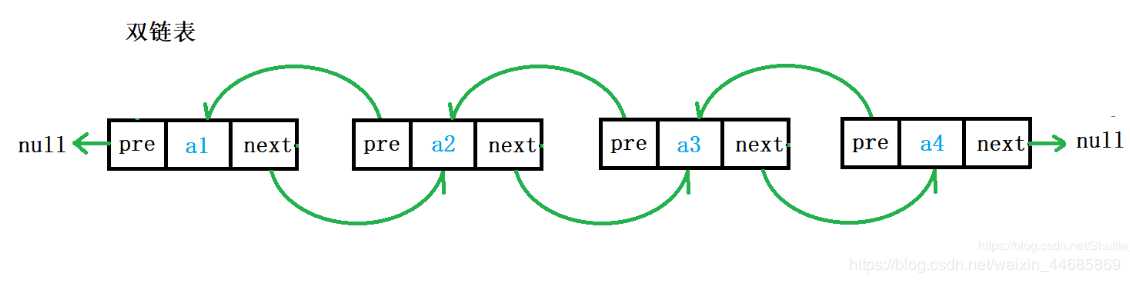
双链表的每一个节点给中既有指向下一个结点的指针,也有指向上一个结点的指针,可以快速的找到当前节点的前一个节点,适用于需要双向查找节点值的情况。
和单链表类似,只不过是增加了一个指向前面一个元素的指针而已。
class Node(object): def __init__(self,val,p=0): self.data = val self.next = p self.prev = p class LinkList(object): def __init__(self): self.head = 0 def __getitem__(self, key): if self.is_empty(): print ‘linklist is empty.‘ return elif key <0 or key > self.getlength(): print ‘the given key is error‘ return else: return self.getitem(key) def __setitem__(self, key, value): if self.is_empty(): print ‘linklist is empty.‘ return elif key <0 or key > self.getlength(): print ‘the given key is error‘ return else: self.delete(key) return self.insert(key) def initlist(self,data): self.head = Node(data[0]) p = self.head for i in data[1:]: node = Node(i) p.next = node node.prev = p p = p.next def getlength(self): p = self.head length = 0 while p!=0: length+=1 p = p.next return length def is_empty(self): if self.getlength() ==0: return True else: return False def clear(self): self.head = 0 def append(self,item): q = Node(item) if self.head ==0: self.head = q else: p = self.head while p.next!=0: p = p.next p.next = q q.prev = p def getitem(self,index): if self.is_empty(): print ‘Linklist is empty.‘ return j = 0 p = self.head while p.next!=0 and j <index: p = p.next j+=1 if j ==index: return p.data else: print ‘target is not exist!‘ def insert(self,index,item): if self.is_empty() or index<0 or index >self.getlength(): print ‘Linklist is empty.‘ return if index ==0: q = Node(item,self.head) self.head = q p = self.head post = self.head j = 0 while p.next!=0 and j<index: post = p p = p.next j+=1 if index ==j: q = Node(item,p) post.next = q q.prev = post q.next = p p.prev = q def delete(self,index): if self.is_empty() or index<0 or index >self.getlength(): print ‘Linklist is empty.‘ return if index ==0: q = Node(item,self.head) self.head = q p = self.head post = self.head j = 0 while p.next!=0 and j<index: post = p p = p.next j+=1 if index ==j: post.next = p.next p.next.prev = post def index(self,value): if self.is_empty(): print ‘Linklist is empty.‘ return p = self.head i = 0 while p.next!=0 and not p.data ==value: p = p.next i+=1 if p.data == value: return i else: return -1 l = LinkList() l.initlist([1,2,3,4,5]) print l.getitem(4) l.append(6) print l.getitem(5) l.insert(4,40) print l.getitem(3) print l.getitem(4) print l.getitem(5) l.delete(5) print l.getitem(5) l.index(5) # 结果 5 6 4 40 5 6
双链表相对于单链表的优点:
删除单链表中的某个节点时,一定要得到待删除节点的前驱,得到其前驱的方法一般是在定位待删除节点的时候一路保存当前节点的前驱,这样指针的总的的移动操作为2n次,如果是用双链表,就不需要去定位前驱,所以指针的总的的移动操作为n次。
查找时也是一样的,可以用二分法的思路,从头节点向后和尾节点向前同时进行,这样效率也可以提高一倍,但是为什么市场上对于单链表的使用要超过双链表呢?从存储结构来看,每一个双链表的节点都比单链表的节点多一个指针,如果长度是n,就需要n*lenght(32位是4字节,64位是8字节)的空间,这在一些追求时间效率不高的应用下就不适用了,因为他占的空间大于单链表的1/3,所以设计者就会一时间换空间。
单向链表的反转
名如其意:将单链表进行反转。
举例:将 1234 反转为 4321 怎么操作
1234->2134->2314->2341->3241->3421->4321,这样也太费劲了,类似冒泡排序了
应该是每次把n后面的数字放到前面来,1234n->1n234->21n34->321n4->4321n
那么接下来用 Python 实现
第一种方法 循环方法
循环方法的思想是建立三个变量,分别指向当前结点,当前结点的前一个结点,新的head结点,从head开始,每次循环将相邻两个结点的方向反转。当整个链表循环遍历过一遍之后,链表的方向就被反转过来了。
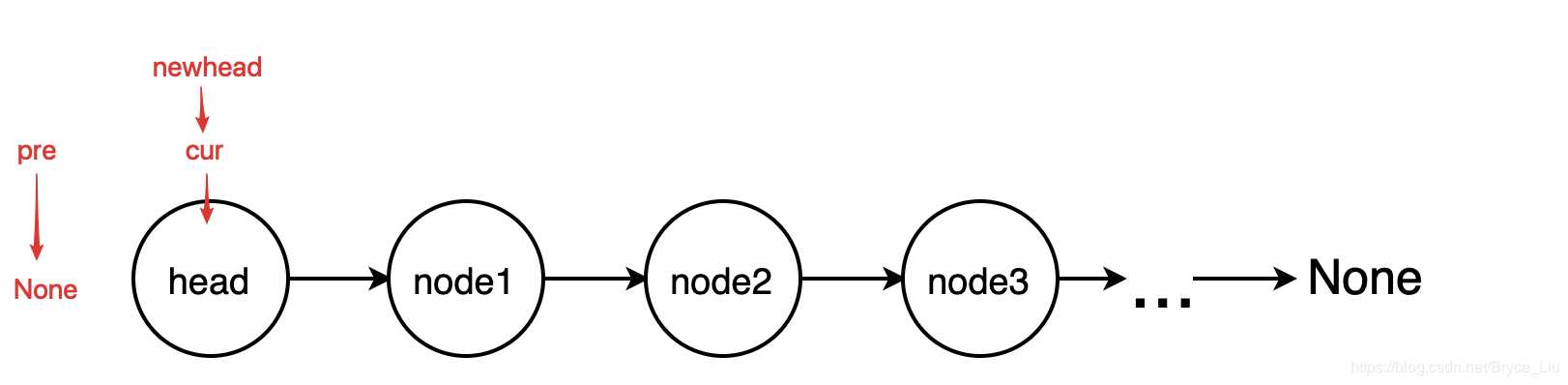
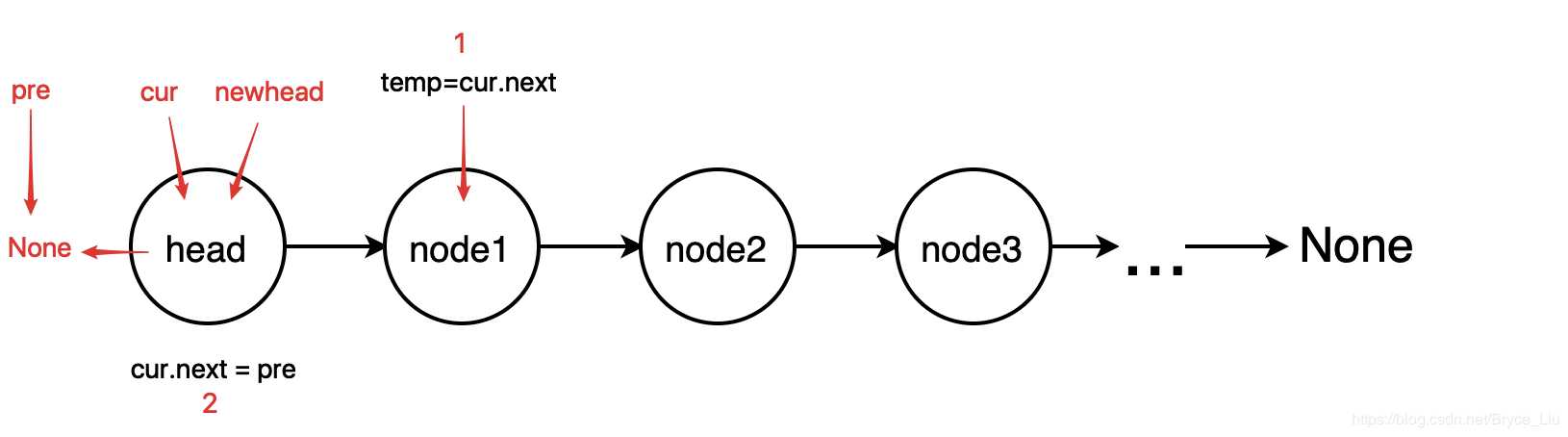
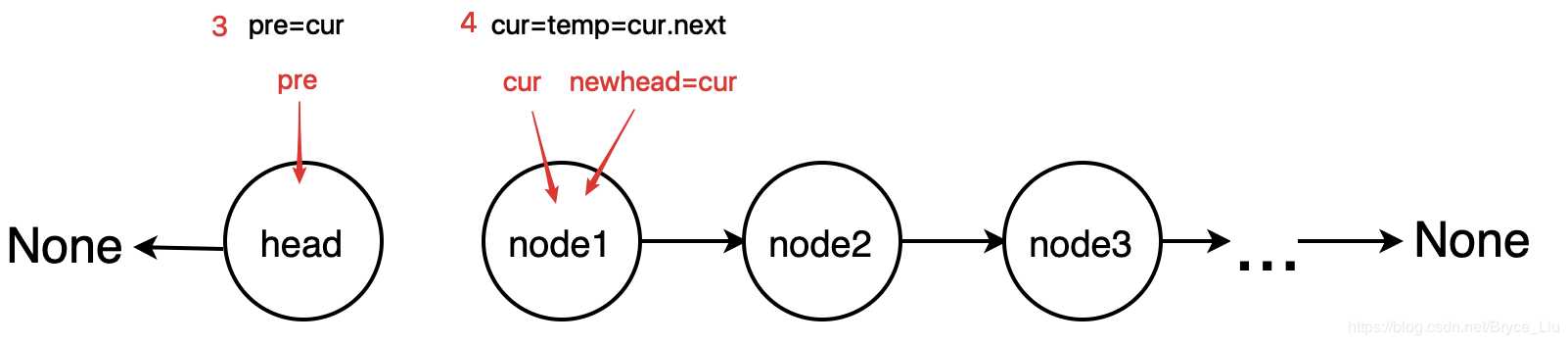
class ListNode: def __init__(self, x): self.val = x self.next = None def reverse(head): # 循环的方法反转链表 if head is None or head.next is None: return head # 定义反转的初始状态 pre = None cur = head newhead = head while cur: newhead = cur tmp = cur.next cur.next = pre pre = cur cur = tmp return newhead if __name__ == ‘__main__‘: head = ListNode(1) # 测试代码 p1 = ListNode(2) # 建立链表1->2->3->4->None; p2 = ListNode(3) p3 = ListNode(4) head.next = p1 p1.next = p2 p2.next = p3 p = reverse(head) # 输出链表 4->3->2->1->None while p: print(p.val) p = p.next
第二种呢 就是 递归方法
根据递归的概念,我们只需要关注递归的基例条件,也就是递归的出口或递归的终止条件,以及长度为n的链表与长度为n-1的链表的关系即可
长度为n的链表的反转结果,只需要将长度为n-1的链表反转后,将链表最后指向None修改为指向长度为n的链表的head,并让head指向None(或者说在链表与None之间添加长度为n的链表的head结点)
即反转长度为n的链表,首先反转n-1链表,然后再操作反转好的链表与head结点的关系;至于n-1长度的链表怎么反转,只需要把它再拆分成node1和n-2的链表…
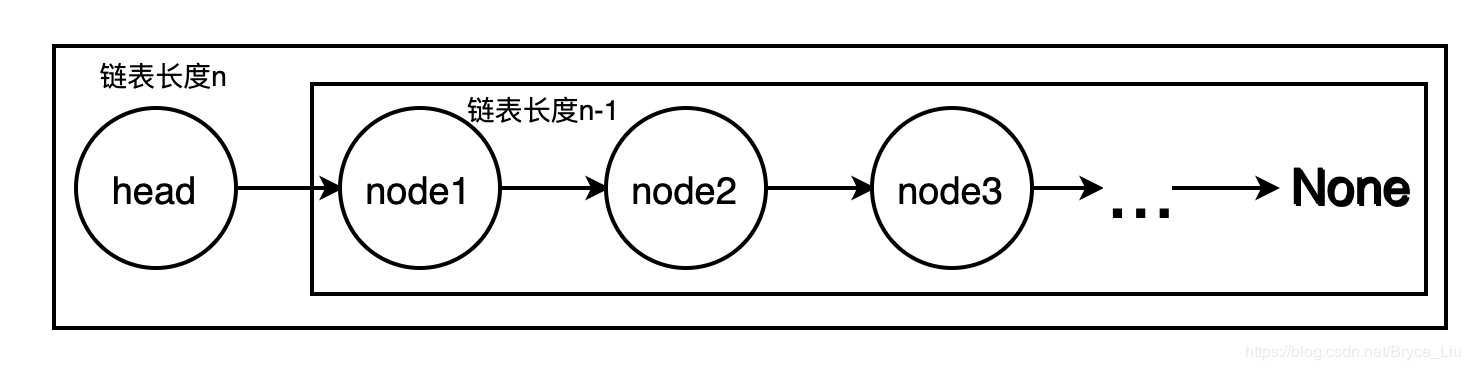
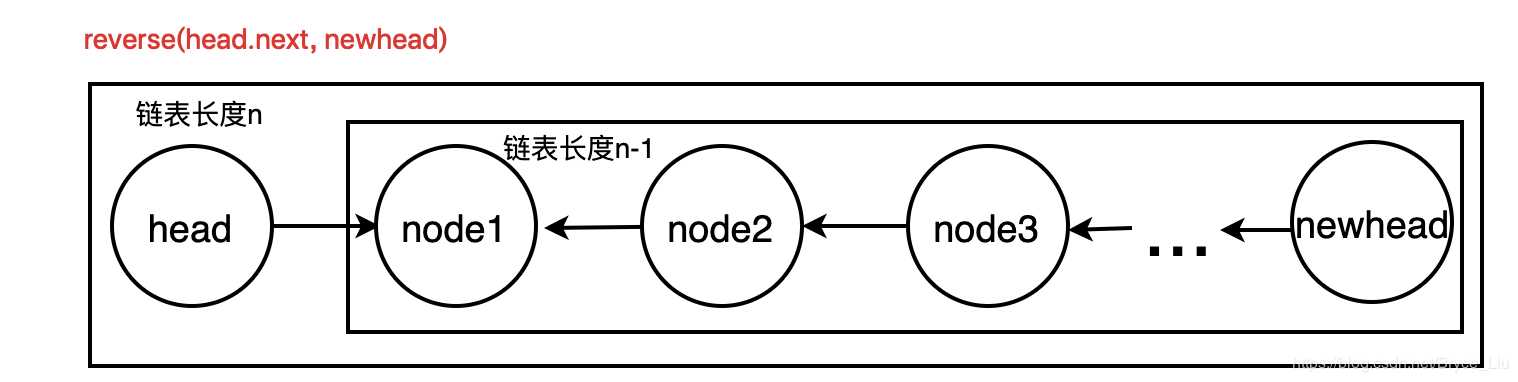
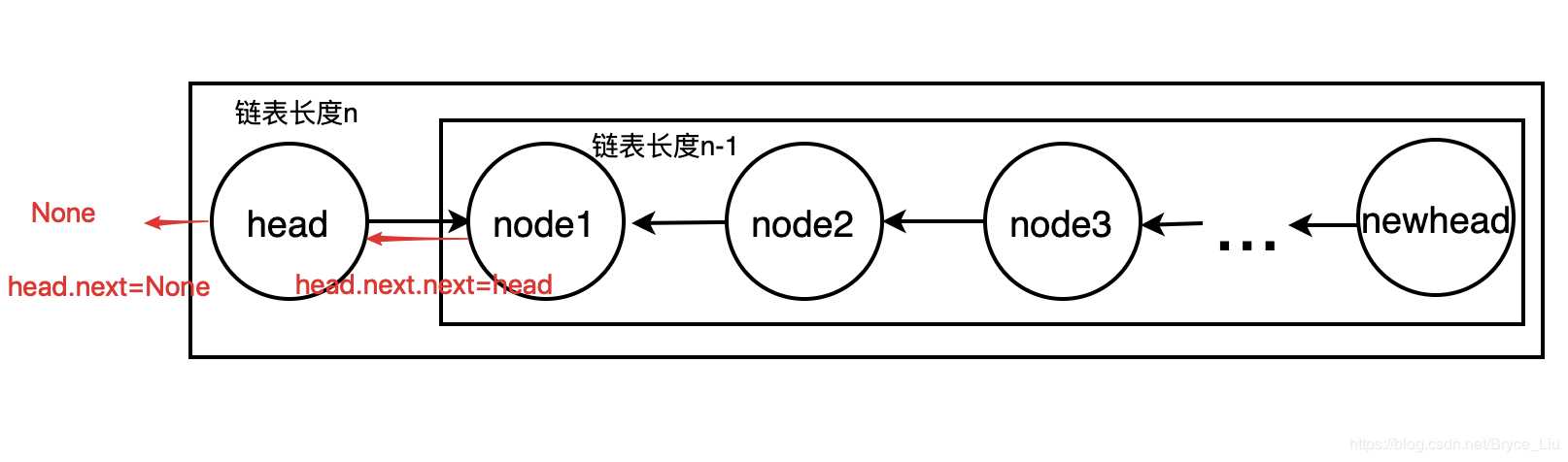
class ListNode: def __init__(self, x): self.val = x self.next = None def reverse(head, newhead): # 递归,head为原链表的头结点,newhead为反转后链表的头结点 if head is None: return if head.next is None: newhead = head else: newhead = reverse(head.next, newhead) head.next.next = head head.next = None return newhead if __name__ == ‘__main__‘: head = ListNode(1) # 测试代码 p1 = ListNode(2) # 建立链表1->2->3->4->None p2 = ListNode(3) p3 = ListNode(4) head.next = p1 p1.next = p2 p2.next = p3 newhead = None p = reverse(head, newhead) # 输出链表4->3->2->1->None while p: print(p.val) p = p.next
数组
所谓数组,是有序的元素序列。若将有限个类型相同的变量的集合命名,那么这个名称为数组名。组成数组的各个变量称为数组的分量,也称为数组的元素,有时也称为下标变量。用于区分数组的各个元素的数字编号称为下标。数组是在程序设计中,为了处理方便, 把具有相同类型的若干元素按无序的形式组织起来的一种形式。 这些无序排列的同类数据元素的集合称为数组。
数组是用于储存多个相同类型数据的集合。
Python 没有内置对数组的支持,但可以使用 Python 列表代替。
一维数组
一维数组是最简单的数组,其逻辑结构是线性表。要使用一维数组,需经过定义、初始化和应用等过程。
在数组的声明格式里,“数据类型”是声明数组元素的数据类型,可以是java语言中任意的数据类型,包括简单类型和结构类型。“数组名”是用来统一这些相同数据类型的名称,其命名规则和变量的命名规则相同。
数组声明之后,接下来便是要分配数组所需要的内存,这时必须用运算符new,其中“个数”是告诉编译器,所声明的数组要存放多少个元素,所以new运算符是通知编译器根据括号里的个数,在内存中分配一块空间供该数组使用。利用new运算符为数组元素分配内存空间的方式称为动态分配方式。
二维数组
前面介绍的数组只有一个下标,称为一维数组, 其数组元素也称为单下标变量。在实际问题中有很多量是二维的或多维的, 因此多维数组元素有多个下标, 以标识它在数组中的位置,所以也称为多下标变量。
二维数组在概念上是二维的,即是说其下标在两个方向上变化, 下标变量在数组中的位置也处于一个平面之中, 而不是象一维数组只是一个向量。但是,实际的硬件存储器却是连续编址的, 也就是说存储器单元是按一维线性排列的。如何在一维存储器中存放二维数组,可有两种方式:一种是按行排列, 即放完一行之后顺次放入第二行。另一种是按列排列, 即放完一列之后再顺次放入第二列。在C语言中,二维数组是按行排列的。在如上中,按行顺次存放,先存放a[0]行,再存放a[1]行,最后存放a[2]行。每行中有四个元素也是依次存放。由于数组a说明为
int类型,该类型占两个字节的内存空间,所以每个元素均占有两个 字节(图中每一格为一字节)。
三维数组
三维数组,是指维数为三的数组结构。三维数组是最常见的多维数组,由于其可以用来描述三维空间中的位置或状态而被广泛使用。
三维数组就是维度为三的数组,可以认为它表示对该数组存储的内容使用了三个独立参量去描述,但更多的是认为该数组的下标是由三个不同的参量组成的。
数组这一概念主要用在编写程序当中,和数学中的向量、矩阵等概念有一定的差别,主要表现:在数组内的元素可以是任意的相同数据类型,包括向量和矩阵。
对数组的访问一般是通过下标进行的。在三维数组中,数组的下标是由三个数字构成的,通过这三个数字组成的下标对数组的内容进行访问。
字符数组
用来存放字符量的数组称为字符数组。
字符数组类型说明的形式与前面介绍的数值数组相同。例如:char c[10]; 由于字符型和整型通用,也可以定义为int c[10]但这时每个数组元素占2个字节的内存单元。
字符数组也可以是二维或多维数组,例如:char c[5][10];即为二维字符数组
字典实现原理 NSDictionary
Python 中 dict 对象是表明了其是一个原始的Python数据类型,按照键值对的方式存储,其中文名字翻译为字典,顾名思义其通过键名查找对应的值会有很高的效率,时间复杂度在常数级别O(1)
dict底层实现
在Python中,字典是通过 哈希表 实现的。也就是说,字典是一个数组,而数组的索引是键经过哈希函数处理后得到的。
哈希表
是根据关键码值(Key value)而直接进行访问的数据结构。它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。
这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表.
函数f(key)为哈希(Hash) 函数。
>>> map(hash, (0, 1, 2, 3)) [0, 1, 2, 3] >>> map(hash, ("namea", "nameb", "namec", "named")) [-1658398457, -1658398460, -1658398459, -1658398462]
哈希概念:哈希表的本质是一个数组,数组中每一个元素称为一个箱子(bin),箱子中存放的是键值对。
哈希函数
哈希函数就是一个映射,因此哈希函数的设定很灵活,只要使得任何关键字由此所得的哈希函数值都落在表长允许的范围之内即可;
并不是所有的输入都只对应唯一一个输出,也就是哈希函数不可能做成一个一对一的映射关系,其本质是一个多对一的映射,这也就引出了下面一个概念–冲突。
冲突
只要不是一对一的映射关系,冲突就必然会发生,还是上面的极端例子,这时新加了一个员工号为2的员工,先不考虑我们的数组大小已经定为2了,按照之前的哈希函数,工号为2的员工哈希值也是2,这与100000000001的员工一样了,这就是一个冲突,针对不同的解决思路,提出三个不同的解决方法。
冲突解决方法
开放地址
开放地址的意思是除了哈希函数得出的地址可用,当出现冲突的时候其他的地址也一样可用,常见的开放地址思想的方法有线性探测再散列,二次探测再散列,这些方法都是在第一选择被占用的情况下的解决方法。
再哈希法
这个方法是按顺序规定多个哈希函数,每次查询的时候按顺序调用哈希函数,调用到第一个为空的时候返回不存在,调用到此键的时候返回其值。
链地址法
将所有关键字哈希值相同的记录都存在同一线性链表中,这样不需要占用其他的哈希地址,相同的哈希值在一条链表上,按顺序遍历就可以找到。
公共溢出区
其基本思想是:所有关键字和基本表中关键字为相同哈希值的记录,不管他们由哈希函数得到的哈希地址是什么,一旦发生冲突,都填入溢出表。
装填因子α
一般情况下,处理冲突方法相同的哈希表,其平均查找长度依赖于哈希表的装填因子。哈希表的装填因子定义为表中填入的记录数和哈希表长度的壁纸,也就是标志着哈希表的装满程度。直观看来,α越小,发生冲突的可能性就越小,反之越大。一般0.75比较合适,涉及数学推导。
哈希存储过程
1.根据 key 计算出它的哈希值 h。
2.假设箱子的个数为 n,那么这个键值对应该放在第 (h % n) 个箱子中。
3.如果该箱子中已经有了键值对,就使用开放寻址法或者拉链法解决冲突。
在使用拉链法解决哈希冲突时,每个箱子其实是一个链表,属于同一个箱子的所有键值对都会排列在链表中。哈希表还有一个重要的属性: 负载因子(load factor),它用来衡量哈希表的空/满程度,一定程度上也可以体现查询的效率,计算公式为:负载因子 = 总键值对数 / 箱子个数负载因子越大,意味着哈希表越满,越容易导致冲突,性能也就越低。因此,一般来说,当负载因子大于某个常数(可能是 1,或者 0.75 等)时,哈希表将自动扩容。哈希表在自动扩容时,一般会创建两倍于原来个数的箱子,因此即使 key 的哈希值不变,对箱子个数取余的结果也会发生改变,因此所有键值对的存放位置都有可能发生改变,这个过程也称为重哈希(rehash)。哈希表的扩容并不总是能够有效解决负载因子过大的问题。假设所有 key 的哈希值都一样,那么即使扩容以后他们的位置也不会变化。虽然负载因子会降低,但实际存储在每个箱子中的链表长度并不发生改变,因此也就不能提高哈希表的查询性能。基于以上总结,细心的朋友可能会发现哈希表的两个问题:
1.如果哈希表中本来箱子就比较多,扩容时需要重新哈希并移动数据,性能影响较大。
2.如果哈希函数设计不合理,哈希表在极端情况下会变成线性表,性能极低。
Python中所有不可变的内置类型都是可哈希的。
可变类型(如列表,字典和集合)就是不可哈希的,因此不能作为字典的键。
树
树是一种数据结构,它是由n(n>=1)个有限结点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
每个结点有零个或多个子结点;没有父结点的结点称为根结点;每一个非根结点有且只有一个父结点;除了根结点外,每个子结点可以分为多个不相交的子树;
树是一种重要的非线性数据结构,直观地看,它是数据元素(在树中称为结点)按分支关系组织起来的结构,很象自然界中的树那样。
树的定义:
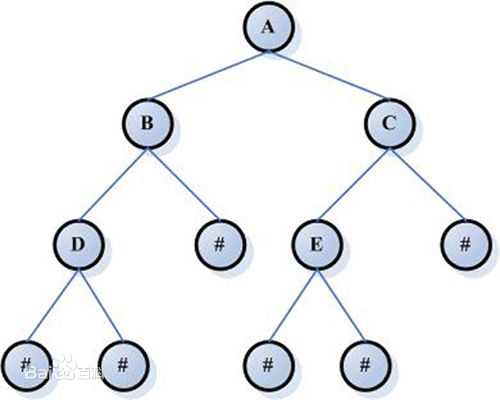
树是由边连接的节点或顶点的分层集合。树不能有循环,并且只有节点和它的下降节点或子节点之间存在边。同一父级的两个子节点在它们之间不能有任何边。每个节点可以有一个父节点除非是顶部节点,也称为根节点。每棵树只能有一个根节点。每个节点可以有零个或多个子节点。在下面的图中,A是根节点,B、C和D是A的子节点。我们也可以说,A是B、C、D的父节点。B、C和D被称为兄弟姐妹,因为它们是来自同一父节点A。
树的种类:
无序树:树中任意节点的子结点之间没有顺序关系,这种树称为无序树,也称为自由树;
有序树:树中任意节点的子结点之间有顺序关系,这种树称为有序树;
二叉树:每个节点最多含有两个子树的树称为二叉树;
完全二叉树
满二叉树
哈夫曼树:带权路径最短的二叉树称为哈夫曼树或最优二叉树;
树的深度:
定义一棵树的根结点层次为1,其他节点的层次是其父结点层次加1。一棵树中所有结点的层次的最大值称为这棵树的深度。
二叉树、满二叉树、完全二叉树
二叉树是一种特殊的树:它或者为空,在二叉树中每个节点最多有两个子节点,一般称为左子节点和右子节点(或左孩子和右孩子),并且二叉树的子树有左右之分,其次序不能任意颠倒。
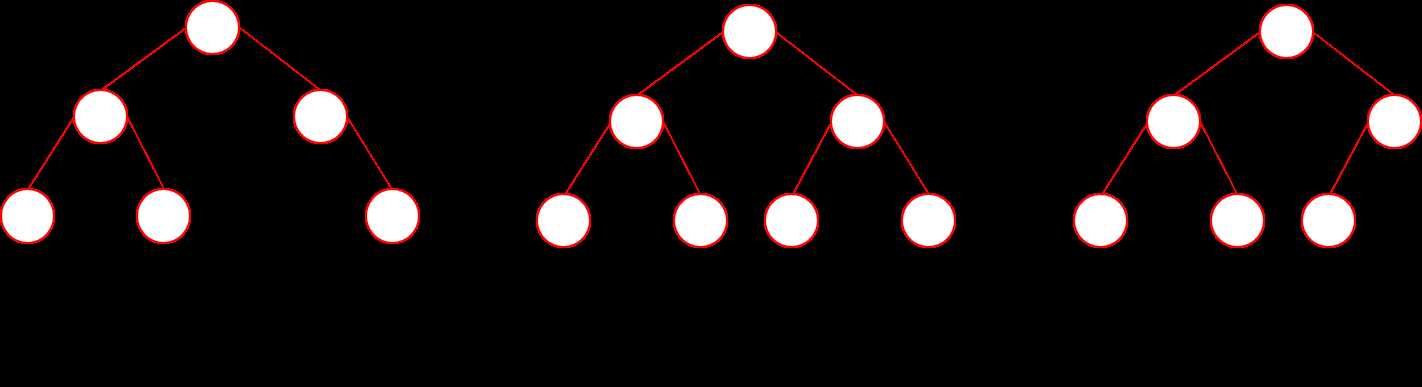
满二叉树: 在一棵二叉树中,如果所有分支结点都有左孩子和右孩子结点,并且叶子结点都集中在二叉树的最下层,这样的树叫做满二叉树
完全二叉树: 若二叉树中最多只有最下面两层的结点的度数可以小于2,并且最下面一层的叶子结点都是依次排列在该层最左边的位置上,则称为完全二叉树
区别: 满二叉树是完全二叉树的特例,因为满二叉树已经满了,而完全并不代表满。所以形态你也应该想象出来了吧,满指的是出了叶子节点外每个节点都有两个孩子,而完全的含义则是最后一层没有满,并没有满。
二叉树
在计算机科学中,二叉树是每个结点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。二叉树常被用于实现二叉查找树和二叉堆。
二叉树是递归定义的,其结点有左右子树之分,逻辑上二叉树有五种基本形态:
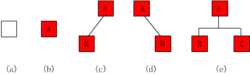
(1)空二叉树——如图(a);
(2)只有一个根结点的二叉树——如图(b);
(3)只有左子树——如图(1);
(4)只有右子树——如图(3);
(5)完全二叉树——如图(3)。
注意:尽管二叉树与树有许多相似之处,但二叉树不是树的特殊情形。 [1]
hash树
哈希树(或哈希特里)是一种持久性数据结构,可用于实现集合和映射,旨在替换纯函数式编程中的哈希表。 在其基本形式中,哈希树在trie中存储其键的哈希值(被视为位串),其中实际键和(可选)值存储在trie的“最终”节点中
什么是质数 : 即只能被 1 和 本身 整除的数。
为什么用质数:因为N个不同的质数可以 ”辨别“ 的连续整数的数量,与这些质数的乘积相同。
也就是说如果有21亿个数字的话,我们查找的哪怕是最底层的也仅仅需要计算10次就能找到对应的数字。
所以hash树是一棵为查找而生的树。
例如:
从2起的连续质数,连续10个质数就可以分辨大约M(10) =23571113171923*29= 6464693230 个数,已经超过计算机中常用整数(32bit)的表达范围。连续100个质数就可以分辨大约M(100) = 4.711930 乘以10的219次方。
而按照目前的CPU水平,100次取余的整数除法操作几乎不算什么难事。在实际应用中,整体的操作速度往往取决于节点将关键字装载内存的次数和时间。一般来说,装载的时间是由关键字的大小和硬件来决定的;在相同类型关键字和相同硬件条件下,实际的整体操作时间就主要取决于装载的次数。他们之间是一个成正比的关系。
B-tree/B+tree
Btree
Btree是一种多路自平衡搜索树,它类似普通的二叉树,但是Btree允许每个节点有更多的子节点。Btree示意图如下:
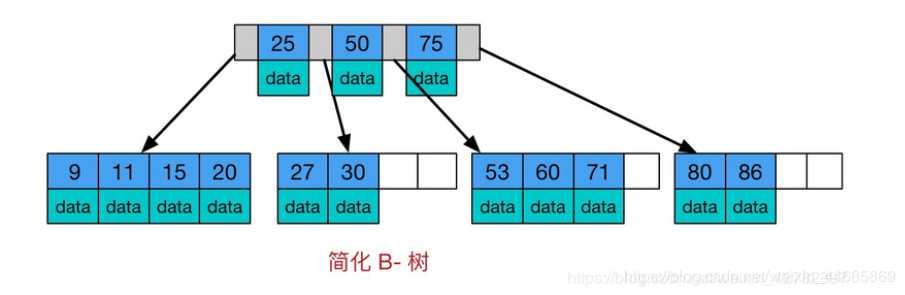
由上图可知 Btree 的一些特点:
所有键值分布在整个树中
任何关键字出现且只出现在一个节点中
搜索有可能在非叶子节点结束
在关键字全集内做一次查找,性能逼近二分查找算法
B+tree
B+树是B树的变体,也是一种多路平衡查找树,B+树的示意图为:
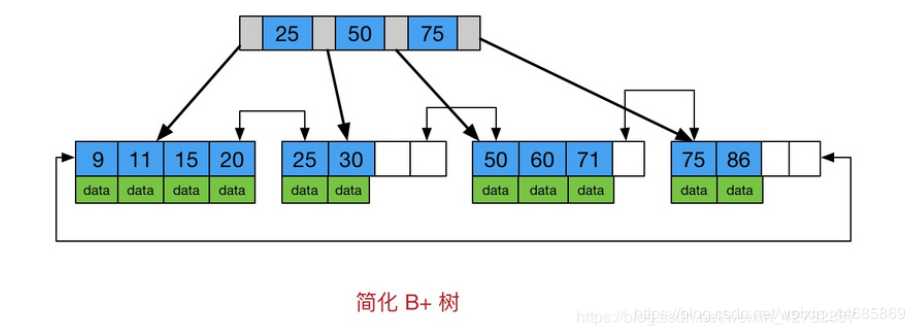
由图可看出B+tree的特点 同时也是 Btree 和 B+tree的区别
所有关键字存储在叶子节点,非叶子节点不存储真正的data
为所有叶子节点增加了一个链指针 只有一个
总结:在数据存储的索引结构上 Btree 更偏向于 纵向深度的存储数据 而 B+tree 更青睐于 横向广度的存储数据。
***********转摘:https://www.cnblogs.com/yangmaosen/p/12307837.html