标签:ati 连接 rda code alt 语义 数据 特点 处理
BERT(Bidirectional Encoder Representations from Transformers)自从谷歌提出就一直大热。首先,它在自然语言处理(NLP)的11个任务中均有较大程度性能提升;其次,BERT在无监督场景下结合预训练能够最大化地利用文本数据,同时对不同场景的下游任务均有提升和帮助。个人觉得BERT的设计进一步利用了语言的特性,其在NLP领域的影响绝对算是个里程碑了。
BERT的网络结构使用了双向Transformer的堆叠(Transformer详解见文末参考资料),Encoder和Decoder分别12层(但也要看是base还是large版)。其思想出于ELMo和GPT(Generative Pre-trained Transformer,出自OpenAI)但同时又高于二者。ELMo采用了双向LSTM来训练词Embedding,虽然使用了双向LSTM,但其实是使用2个单向LSTM对学到的句子语义信息做拼接,和BERT完全双向不同,对句子间不同词的语义依赖关系也不如BERT捕捉的充分。 GPT只有单向,其假设句子间语义依赖关系只有从左到右,而没有从右到左,该假设在实际中并不完全满足。上述三种模型架构图如下图,BERT、GPT、ELMo分别从左到右:
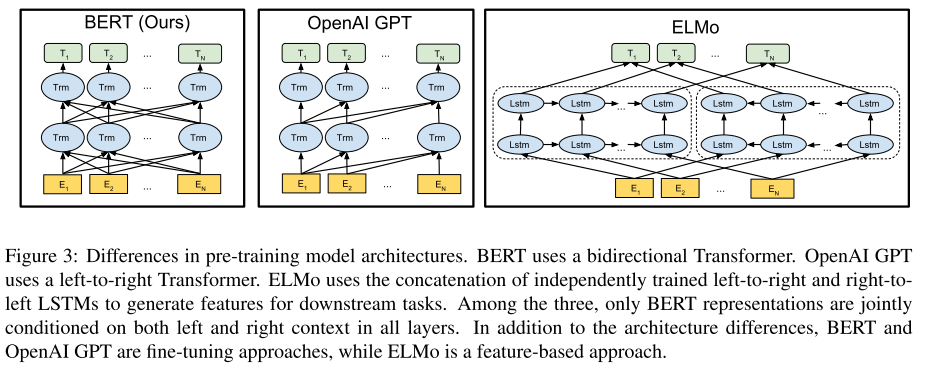
BERT加入了Masked Language Model(MLM) 和 Next Sentences Prediction(NSP),使得模型能够在无监督的场景下学习到句子间特征和语义特征。个人理解LM(语言模型)能学习到一个句子的语义特征,而使用MLM更能有效促使模型学到句子更好的语义表示。 在无监督学习场景训练,能最大化的使用训练语料。而Pre-train和Fine-tune能够方便地将已训练好的BERT模型迁移到不同的应用场景,在工业界大有益处。
(1) Masked LM
原文表示,在模型预训练阶段使用Masked LM来训练BERT会有更好的效果。具体做法是对文中所有WordPiece token(不包括特殊标记字符)随机抽样15%并进行mask遮掩,并对被Masked的词依概率进行如下操作:
80% 表示为 mask
10% 替换为任意其他词
10% 不做替换
文中也没有说为什么以这样的概率做上述操作,只是提到不能对所有词进行mask,否则在fine-tune时,会有部分词从来没见过而影响效果,为了缓解这一情况,采用了对被masked词进行上述概率来做不同处理。
使用了Mask操作后,用基于mask的语言模型的loss来训练。
(2)Next Sentences Prediction
在智能问答(QA)和自然预研推理(NLI)任务中,句子间的关系显得尤为重要。在Transformer或GPT中,没有对句子间的关系进行学习,BERT中提出的NSP来涵盖这一空白,具体做法是:将句子A与B合并为一句来进行训练,使用50%的概率来选择A句后紧接着的句子,其余50%用随机一个句子,在此构建针对该2句是否是连接关系的二分类模型。
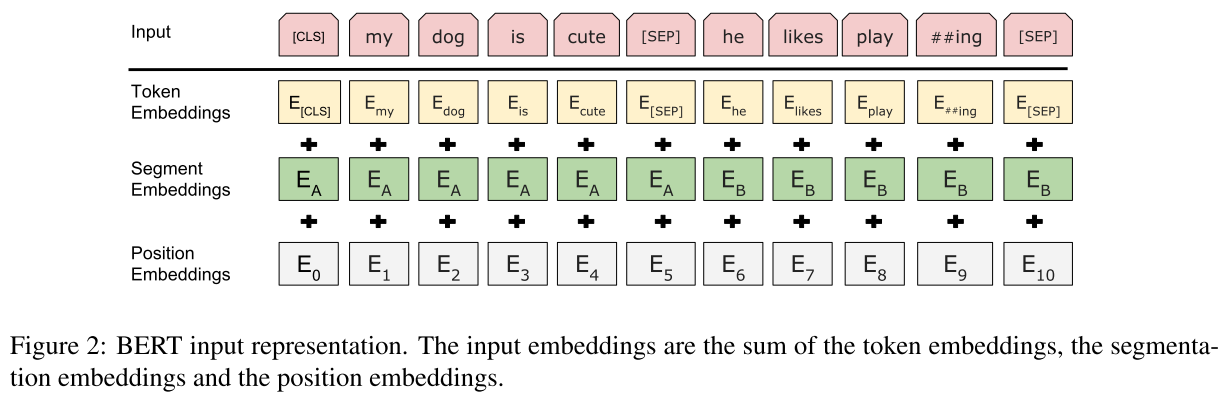
对于待训练句子,使用词embedding、segment embedding、position embedding相加来训练,如下图所示:
(3)不同下游任务的fine-tune
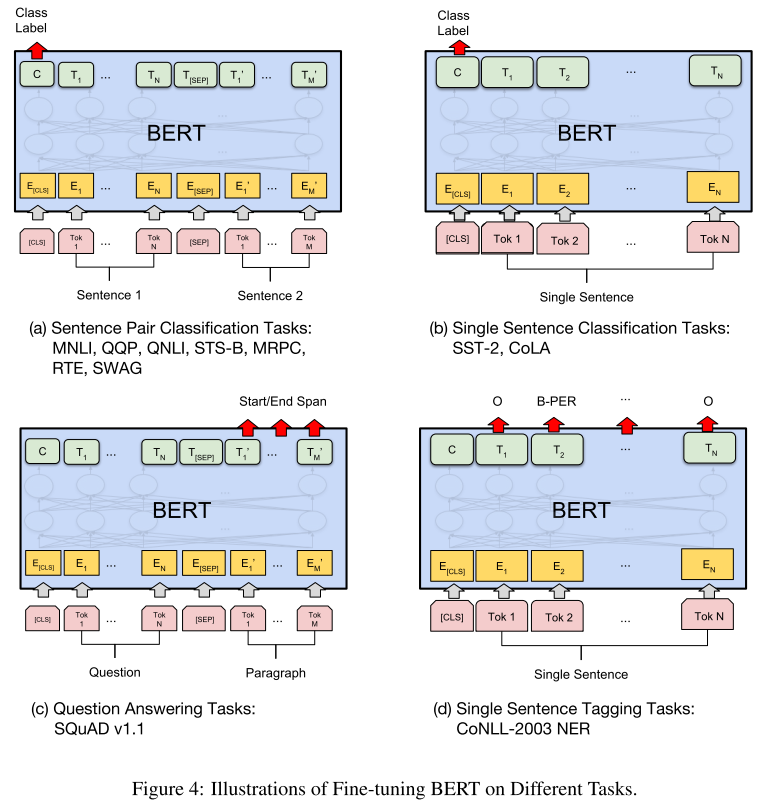
BERT还有一个优势就是可以在不同的下游任务中进行微调,利于工业界的快速落地。不论是在pre-train还是fine-tune的训练阶段,都会开启MLM训练,而在验证测试阶段关闭MLM。但基于不同的下游任务在fine-tune时有些许不同,具体如下图所示:
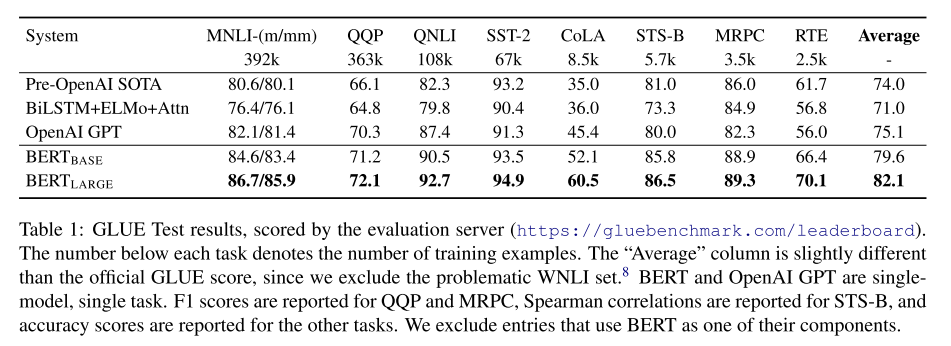
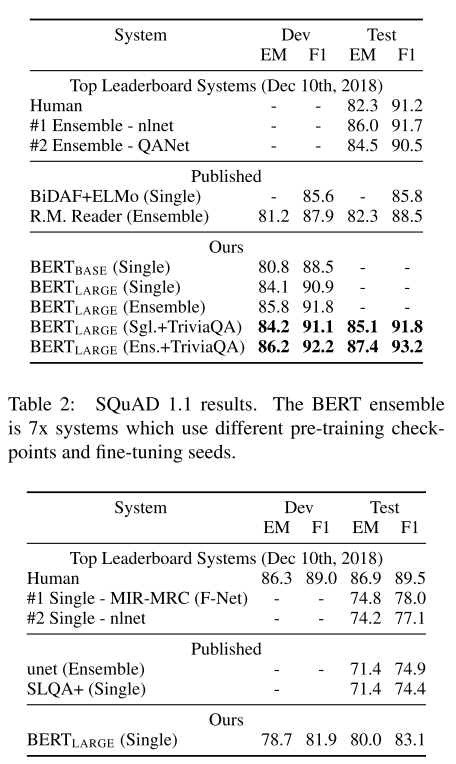
各种实验结果表示BERT的强力,这里贴出部分结果
对 【BERT- Pre-training of Deep Bidirectional Transformers for Language Understanding】 的理解
标签:ati 连接 rda code alt 语义 数据 特点 处理
原文地址:https://www.cnblogs.com/andre-ma/p/13473077.html