标签:dns 实现 mamicode art 必须 span mac mobile bit
最近在从头重写 MobileIMSDK 的TCP版,自已组织TCP数据帧时就遇到了字节序大小端问题。所以,借这个机会单独整理了这篇文章,希望能加深大家对字节序问题的理解,加强对IM这种基于网络通信的程序在数据传输这一层的知识掌控情况。
程序员在写应用层程序时,一般不需要考虑字节序问题,因为字节序跟操作系统和硬件环境有关,而我们编写的程序要么不需要跨平台(比如只运行在windows),要么需要跨平台时会由Java这种跨平台语言在虚拟机层屏蔽掉了。
但典型情况,当你编写网络通信程序,比如IM聊天应用时,就必须要考虑字节序问题,因为你的数据在这样的场景下要跨机器、跨网络通信,必须解决不同系统、不同平台的字节序问题。
* 阅读对象:本文属于计算机基础知识,特别适合从事网络编程方面工作(比如IM这类通信系统)的程序员阅读。面视时,面视官一般都会聊到这个知识点。
本文已同步发布于“即时通讯技术圈”公众号,欢迎关注:

▲ 本文在公众号上的链接是:点此进入 ,原文链接是:http://www.52im.net/thread-3101-1-1.html
字节序,是指数据在内存中的存放顺序,当字节数大于1时需要考虑(只有一个字节的情况下,比如char类型,也就不存在顺序问题啦)。
从下图中,可以直观的感受到什么是字节序问题:

(上图片改编自《C语言打印数据的二进制格式-原理解析与编程实现》)
字节序常被分为两类:
举个具体的例子,0x1234567 的大端字节序和小端字节序写法如下:
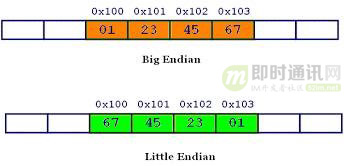
如上图所示:大端小端字节序最小单位1字节,即8bit;大端字节序就是和我们平时写法的顺序一样,从低地址到高地址写入0x01234567;而小端字节序就是和我们平时的写法反过来,因为字节序最小单位为1字节,所以从低地址到高地址写入0x67452301。
一个比较合理的解释是说:计算机中电路优先处理低位字节,效率比较高,因为计算机都是从低位开始的,所以计算机内部处理都是小端字节序。
而人类人类读写数值的方法,习惯用大端字节序,所以除了计算机的内部处,其他的场理合都是大端字节序,比如:网络传输和文件储存时都是用的大端字节序(关于网络字节序,会在后面继续展开说明)。
大小端字节序问题,最有可能是跟技术算硬件或软件的创造者们,在技术创立之初的一些技术条件或个人习惯有关。
所以大小端问题,体现在实际的计算机工业应用来上,不同的操作系统和不同的芯片类型可能都会有不同。
具体来说:DEC和Intel的机器(X86平台)一般采用小端,IBM、Motorola(Power PC)、Sun的机器一般采用大端。
当然,这不代表所有情况。有的CPU即能工作于小端, 又能工作于大端,比如:Arm、Alpha、摩托罗拉的PowerPC。
而且,具体这类CPU是大端还是小端,和具体设置也有关。如:Power PC支持小端字节序,但在默认配置时是大端字节序。
一般来说:大部分用户的操作系统(如:Windows、FreeBsd、Linux)是小端字节序。少部分,如:Mac OS 是大端字节序。
怎么判断我的计算机里使用的是大端还是小端字节序呢?
下面的这段代码可以用来判断计算机是大端的还是小端。判断的思路是:确定一个多字节的值(下面使用的是4字节的整数),将其写入内存(即赋值给一个变量),然后用指针取其首地址所对应的字节(即低地址的一个字节),判断该字节存放的是高位还是低位,高位说明是Big endian,低位说明是Little endian。
#include <stdio.h>
int main ()
{
unsigned int x = 0x12345678;
char*c = (char*)&x;
if(*c == 0x78) {
printf("Little endian");
} else{
printf("Big endian");
}
return 0;
}
根据网上的资料,据说名字的由来跟乔纳森·斯威夫特的著名讽刺小说《格列佛游记》有关。

书中的故事是这样的:一般来说,大家都认为吃鸡蛋前,原始的方法是打破鸡蛋较大的一端。可是当今皇帝的祖父小时候吃鸡蛋,一次按古法打鸡蛋时碰巧将一个手指弄破了,因此他的父亲,当时的皇帝,就下了一道敕令,命令全体臣民吃鸡蛋时打破鸡蛋较小的一端,违令者重罚。
小人国内部分裂成Big-endian和Little-endian两派,区别在于一派要求从鸡蛋的大头把鸡蛋打破,另一派要求从鸡蛋的小头把鸡蛋打破。
小人国国王改变了打开鸡蛋的方位与理由,并由此招致了修改法律、引发战争和宗教改革等一序列事件的发生。
《格列佛游记》中的这则故事,原本是借以讽刺英国的政党之争。而在计算机工业中,也借用了这个故事来代指大家在数据储存字节顺序中的分歧,并把“大端”(Big-endian)、“小端”(Little-endian)的名字,沿用到了计算机中。
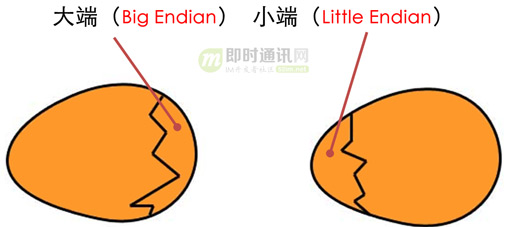
(上图片改编自《“字节序”是个什么鬼?》)
或许,借用这个故事来命名大小端字节序问题,无非就是想告诉大家,所谓的“大端”、“小端”实际上可能无关计算机性能,更多的只是创造者们在创立计算机之初,代入了个人的一些约定俗成的习惯而已。
对于搞网络通信应用(比如IM、消息推送、实时音视频)开发的程序员来说,自已写通信底层的话是一定会遇到大小端问题的,对于网络字节序这个知识点是一定要必知必会。(当然,你要是很没追求的认为,反正我公司就让租租第3方,能用就行,具体通底层怎么写我才不想掉头发去考虑那么多。。。。 那哥也救不了你。。)
上面所说的大小端字节序都是在说计算机自己,也被称作主机字节序。同型号计算机上写的程序,在相同的系统上面运行总归是没有问题。
但计算机网络的出现让大小端问题变的复杂化了,因为每个计算机都有自己的主机字节序。不同计算机之间通过网络通信时:我“说”的你听不懂,你“说”我也听不懂,这可怎么办?
好消息是,TCP/IP协议很好的解决了这个问题,TCP/IP协议规定使用“大端”字节序作为网络字节序。

这样,即使不使用大端的计算机也没有关系,因为发送数据的时候可以将自己的主机字节序转换为网络字节序(即“大端”字节序),对接收到的数据转换为自己的主机字节序。这样一来,也就达到了与CPU、操作系统无关,实现了网络通信的标准化。
具体的原理就是:
也就是说,该数值在内存中的起始地址处对应的那个字节就是要发送的第一个高位字节(即:高位字节存放在低地址处)。由此可见,多字节数值在发送之前,在内存中就是以大端法存放的。
所以说,网络字节序就是大端字节序。
那么,为了程序的兼容,程序员们每次发送和接受数据都要进行转换,这样做的目的是保证代码在任何计算机上执行时都能达到预期的效果。
通信时的这种常用的操作,Socket API这一层,一般都提供了封装好的转换函数,方便程序员使用。比如从主机字节序到网络字节序的转换函数:htons、htonl(C语言中常用),从网络字节序到主机字节序的转换函数:ntohs、ntohl(C语言中常用)。当然,也可以编写自己的转换函数。
在我编写MobileIMSDK的TCP版时(MobileIMSDK是我开源的IM通信层库),同样遇到了大小端字节序问题。
以MobileIMSDK的iOS端拼装网络数据收发的代码为例:
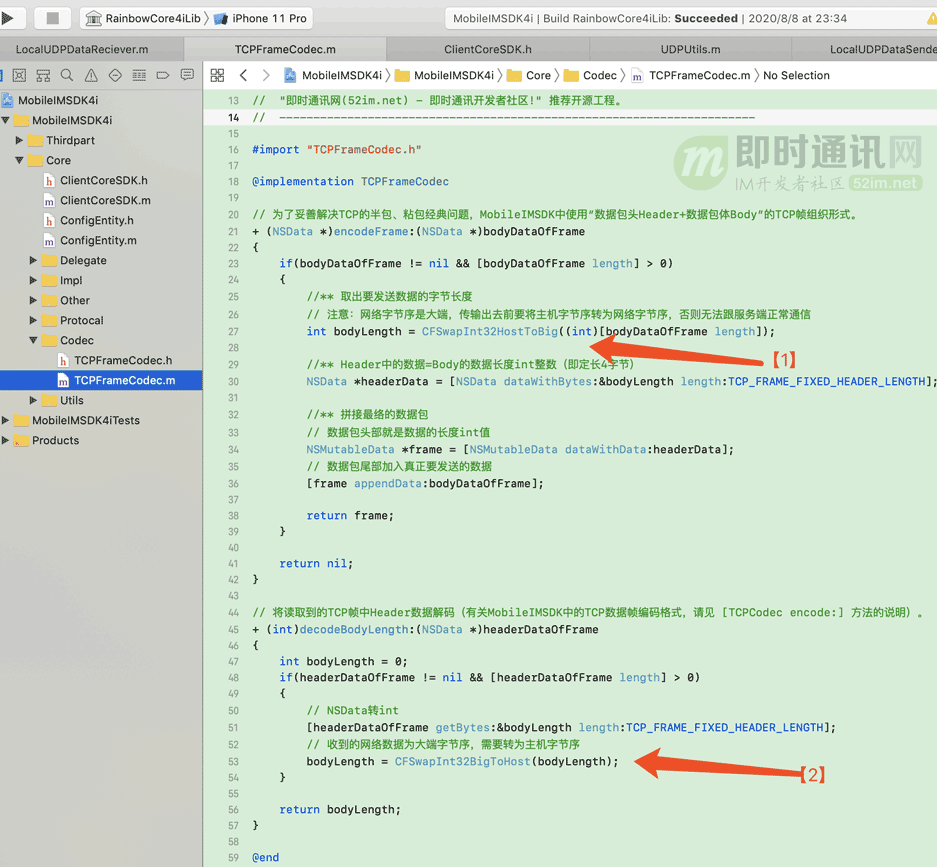
如上图代码所示,注意以下两个大小端转换函数的使用:
如果对网络大小端转换这方面的实践感兴趣,可以自已去下载MobileIMSDK源码试一试:https://github.com/JackJiang2011/MobileIMSDK。
[1] “字节序”是个什么鬼?
[2] 大小端及网络字节序
本文是系列文章中的第9篇,本系列大纲如下:
《脑残式网络编程入门(一):跟着动画来学TCP三次握手和四次挥手》
《脑残式网络编程入门(二):我们在读写Socket时,究竟在读写什么?》
《脑残式网络编程入门(三):HTTP协议必知必会的一些知识》
《脑残式网络编程入门(四):快速理解HTTP/2的服务器推送(Server Push)》
《脑残式网络编程入门(五):每天都在用的Ping命令,它到底是什么?》
《脑残式网络编程入门(六):什么是公网IP和内网IP?NAT转换又是什么鬼?》
《脑残式网络编程入门(七):面视必备,史上最通俗计算机网络分层详解》
(本文同步发布于:http://www.52im.net/thread-3101-1-1.html)
脑残式网络编程入门(九):面试必考,史上最通俗大小端字节序详解
标签:dns 实现 mamicode art 必须 span mac mobile bit
原文地址:https://www.cnblogs.com/imteck4713/p/13496433.html