标签:文件大小 数据库 案例 handler service nullable lin 作业 getc
背景最近有个学弟找到我,跟我描述了以下场景:
他们公司内部管理系统上有很多报表,报表数据都有分页显示,浏览的时候速度还可以。但是每个报表在导出时间窗口稍微大一点的数据时,就异常缓慢,有时候多人一起导出时还会出现堆溢出。
他知道是因为数据全部加载到jvm内存导致的堆溢出。所以只能对时间窗口做了限制。以避免因导出过数据过大而引起的堆溢出。最终拍脑袋定下个限制为:导出的数据时间窗口不能超过1个月。
虽然问题解决了,但是运营小姐姐不开心了,跑过来和学弟说,我要导出一年的数据,难道要我导出12次再手工合并起来吗。学弟心想,这也是。系统是为人服务的,不能为了解决问题而改变其本质。
所以他想问我的问题是:有没有什么办法可以从根本上解决这个问题。
所谓从根本上解决这个问题,他提出要达成2个条件
我听完他的问题后,我想,他的这个问题估计很多其他童鞋在做web页导出数据的时候也肯定碰到过。很多人为了保持系统的稳定性,一般在导出数据时都对导出条数或者时间窗口作了限制。但需求方肯定更希望一次性导出任意条件的数据集。
鱼和熊掌能否兼得?
答案是可以的。
我坚定的和学弟说,大概7年前我做过一个下载中心的方案,20w数据的导出大概4秒吧。。。支持多人同时在线导出。。。
学弟听完表情有些兴奋,但是眉头又一皱,说,能有这么快,20w数据4秒?
为了给他做例子,我翻出了7年前的代码。。。花了一个晚上把核心代码抽出来,剥离干净,做成了一个下载中心的例子
先不谈技术,先看效果,(完整案例代码文末提供)
数据库为mysql(理论上此套方案支持任何结构化数据库),准备一张测试表t_person。表结构如下:
CREATE TABLE `t_person` (
`id` bigint(20) NOT NULL auto_increment,
`name` varchar(20) default NULL,
`age` int(11) default NULL,
`address` varchar(50) default NULL,
`mobile` varchar(20) default NULL,
`email` varchar(50) default NULL,
`company` varchar(50) default NULL,
`title` varchar(50) default NULL,
`create_time` datetime default NULL,
PRIMARY KEY (`id`)
);一共9个字段。我们先创建测试数据。
案例代码提供了一个简单的页面,点以下按钮一次性可以创建5w条测试数据:
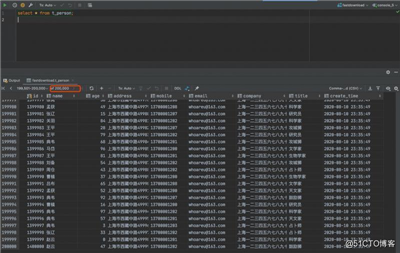
这里我连续点了4下,很快就生成了20w条数据,这里为了展示下数据的大致样子,我直接跳转到了最后一页
然后点开下载大容量文件,点击执行执行按钮,开始下载t_person这张表里的全部数据
点击执行按钮之后,点下方刷新按钮,可以看到一条异步下载记录,状态是P,表示pending状态,不停刷新刷新按钮,大概几秒后,这一条记录就变成S状态了,表示Success
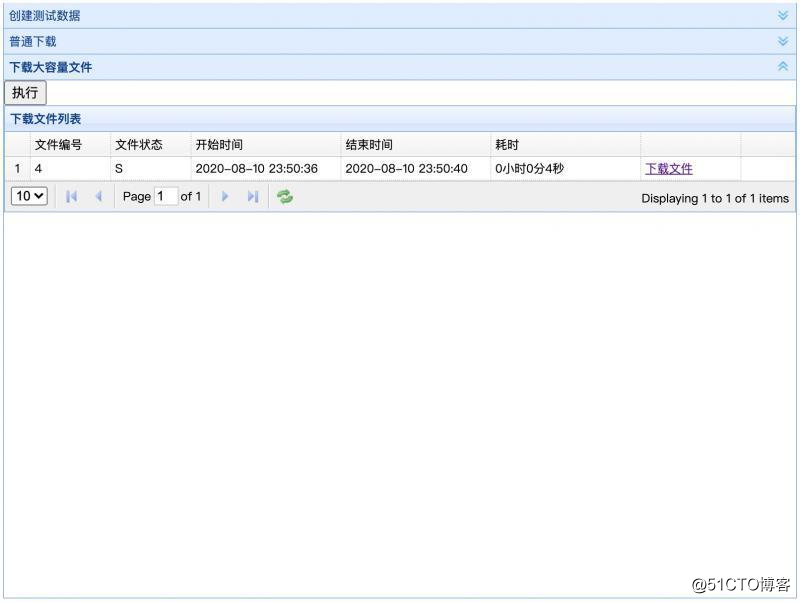
然后你就可以下载到本地,文件大小大概31M左右

看到这里,很多童鞋要疑惑了,这下载下来是csv?csv其实是文本文件,用excel打开会丢失格式和精度。这解决不了问题啊,我们要excel格式啊!!
其实稍微会一点excel技巧的童鞋,可以利用excel导入数据这个功能,数据->导入数据,根据提示一步步,当中只要选择逗号分隔就可以了,关键列可以定义格式,10秒就能完成数据的导入
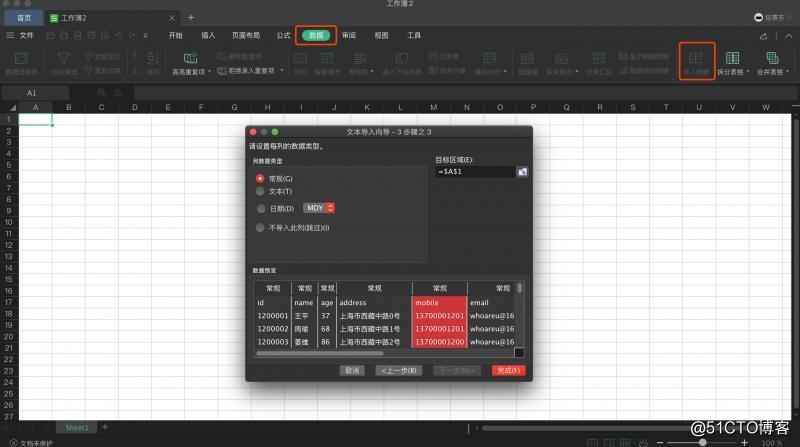
你只要告诉运营小姐姐,根据这个步骤来完成excel的导入就可以了。而且下载过的文件,还可以反复下。
是不是从本质上解决了下载大容量数据集的问题?
学弟听到这里,很兴奋的说,这套方案能解决我这里的痛点。快和我说说原理。
其实这套方案核心很简单,只源于一个知识点,活用JdbcTemplate的这个接口:
@Override
public void query(String sql, @Nullable Object[] args, RowCallbackHandler rch) throws DataAccessException {
query(sql, newArgPreparedStatementSetter(args), rch);
}sql就是select * from t_person,RowCallbackHandler这个回调接口是指每一条数据遍历后要执行的回调函数。现在贴出我自己的RowCallbackHandler的实现
private class CsvRowCallbackHandler implements RowCallbackHandler{
private PrintWriter pw;
public CsvRowCallbackHandler(PrintWriter pw){
this.pw = pw;
}
public void proce***ow(ResultSet rs) throws SQLException {
if (rs.isFirst()){
rs.setFetchSize(500);
for (int i = 0; i < rs.getMetaData().getColumnCount(); i++){
if (i == rs.getMetaData().getColumnCount() - 1){
this.writeToFile(pw, rs.getMetaData().getColumnName(i+1), true);
}else{
this.writeToFile(pw, rs.getMetaData().getColumnName(i+1), false);
}
}
}else{
for (int i = 0; i < rs.getMetaData().getColumnCount(); i++){
if (i == rs.getMetaData().getColumnCount() - 1){
this.writeToFile(pw, rs.getObject(i+1), true);
}else{
this.writeToFile(pw, rs.getObject(i+1), false);
}
}
}
pw.println();
}
private void writeToFile(PrintWriter pw, Object valueObj, boolean isLineEnd){
...
}
}这个CsvRowCallbackHandler做的事就是每次从数据库取出500条,然后写入服务器上的本地文件中,这样,无论你这条sql查出来是20w条还是100w条,内存理论上只占用500条数据的存储空间。等文件写完了,我们要做的,只是从服务器把这个生成好的文件download到本地就可以了。
因为内存中不断刷新的只有500条数据的容量,所以,即便多线程下载的环境下。内存也不会因此而溢出。这样,完美解决了多人下载的场景。
当然,太多并行下载虽然不会对内存造成溢出,但是会大量占用IO资源。为此,我们还是要控制下多线程并行的数量,可以用线程池来提交作业
ExecutorService threadPool = Executors.newFixedThreadPool(5);
threadPool.submit(new Thread(){
@Override
public void run() {
下载大数据集代码
}
}最后测试了下50w这样子的person数据的下载,大概耗时9秒,100w的person数据,耗时19秒。这样子的下载效率,应该可以满足大部分公司的报表导出需求吧。
学弟拿到我的示例代码后,经过一个礼拜的修改后,上线了页面导出的新版本,所有的报表提交异步作业,大家统一到下载中心去进行查看和下载文件。完美的解决了之前的2个痛点。
但最后学弟还有个疑问,为什么不可以直接生成excel呢。也就是说在在RowCallbackHandler中持续往excel里写入数据呢?
我的回答是:
1.文本文件流写入比较快
2.excel文件格式好像不支持流持续写入,反正我是没有试成功过。
我把剥离出来的案例整理了下,无偿提供给大家,希望帮助到碰到类似场景的童鞋们。
从系统报表页面导出20w条数据到本地只用了4秒,我是如何做到的
标签:文件大小 数据库 案例 handler service nullable lin 作业 getc
原文地址:https://blog.51cto.com/14230003/2521319