标签:有一个 针对 完数 精确 标识 难点 中转 日期 一个
一张表中的数据每日既有可能新增,也有可能修改,但是频率并不高,属于缓慢变化的维度,因此可以使用拉链表存储维度数据。
那么什么是拉链表呢?
拉链表:记录每条信息的生命周期,所以拉链表中都会有一个起始时间、一个结束时间、以及一个业务主键。当插入一条记录的时候,会将起始时间设置为插入时间、或者采集时间等等,把结束时间设置为NULL或者一个极大值
(9999-09-09)。一旦来了一条新的记录,业务主键和上一条记录相同,那么就意味着上一条记录的生命周期结束了,所以会将设置上一条记录的结束时间。然后把这条新记录插入到表中,然后起始时间设置为插入时间或者采集时间,结束时间设置为NULL或者极大值。
光看文字不好理解的话,我们举几个栗子。
1. 以公司分配任务为例:

首先每个任务都有一个唯一的id,用于定位具体的任务,然后任务有三种状态:已接收、进展50%、办结。
(历史数据)。然后将这条新的数据插入进去,设置起始时间,然后结束时间为极大值,但是不要忘记设置已经变成拉链的历史数据的结束时间。这里我们将历史数据的结束时间设置成了新记录的起始时间的前一天,但是具体怎么设置可以由业务决定。可以看到这便是拉链表,它记录了一个事物的整个生命周期,一旦它的结束时间不是极大值或者NULL,那么这条记录就变成了拉链。
2. 以人员表为例:

我们看到图中的也是一张拉链表,记录员工使用的手机信息,员工在某一个阶段使用的什么手机都进行了记录。
总结一下:拉链表就是记录历史,一个事物从创建到结束的整个生命周期,在不同的时间处于不同的状态,都会进行记录。一旦有了新的状态,那么过去的状态就变成了历史,将每一个过程都记录下来就是拉链表。
拉链表适合于:数据会发生变化,但是大部分是不变的(缓慢变化)。
如果数据不变,那么采用增量事实表,因为事实表的数据一旦导入就不会发生变化了。
那么我们如何使用拉链表呢?
通过 起始时间 <= 指定日期 < 结束时间,那么能够得到某个时间点的数据的全量切片。比如:我们想查看2018-05-05的时候员工使用的手机品牌,直接就可以进行定位,当然我们这里数据比较少。
关于粒度,可以从细到粗、但无法从粗到细。比如当前粒度是"星期",可以通过汇总的方式将粒度从"星期"变成"月",但是显然我们无法将"星期"分解成"天"。
拉链表的形成过程
以我所在的公司为例,从接口获取过来的数据有的是全量数据,就是所有数据全部在里面。所以我们可以在此基础之上增加两个字段:起始时间、结束时间,而且对方都会有一个时间字段,我们称之为业务时间,而起到标识的字段我们称之为业务主键(不是数据库的主键, 而是业务主键, 比如: 工号、任务id等等)。然后我们按天来采集对方的数据,假设从2019-01-01开始采集,导入到数据库;然后在采集2019-01-02的数据时,会和库中已有的2019-01-01的数据按照业务主键进行对比。如果业务主键相同,那么2019-01-01的数据就成为了拉链,然后将新数据导入进去。然后一直持续这个过程,直到将对方的数据获取完毕。
所以拉链表一定要有一个起始时间和结束时间,记录一个事物在不同阶段所处的状态。
我们举个栗子:

当我们采集完2019-02-02的数据时,准备导入到库中,这个时候要和2019-01-01的数据进行对比,然后将业务主键相同的数据变成拉链。显然这里的业务主键就是工号,因为工号可以精确定位到某个具体的员工。
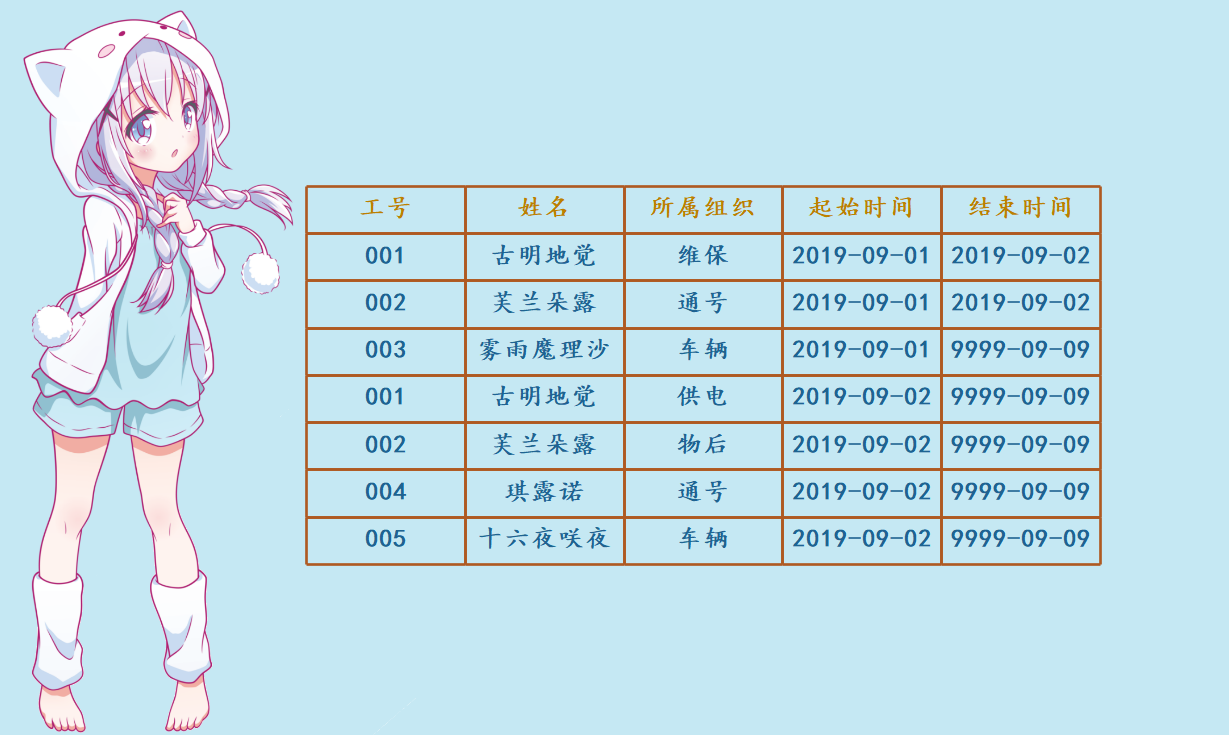
对比完的结果就是这个样子。
对比完的结果就是这个样子。不过我所在公司从对方接口获取完数据之后,并不是直接就进行对比。针对不同的业务,我们都会有两张表,一张di表和一张df表,df表是拉链表,di表是拉链临时表。会通过任务调度工具airflow自动执行Python脚本从接口获取的数据,然后会先将数据原封不动的导入到di表,然后再通过di表和df表进行对比、设置拉链,后续都会基于df表进行操作,所以相当于说多了一步中转站(di)。所以整个流程如下:
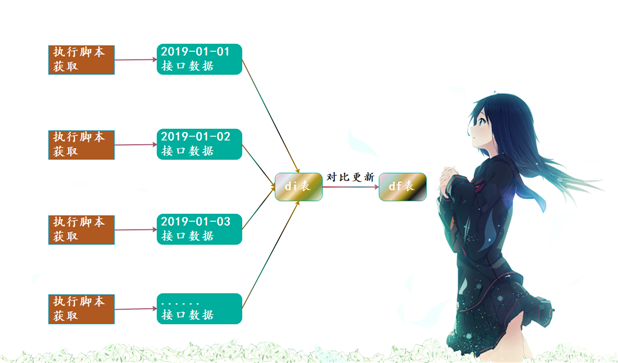
所以拉链表其实很简单,一句话总结就是"记录历史",重点也是难点在于和业务的结合。本人所在公司的拉链表远比当前图中说的复杂,而且是两层拉链表。从ODS层到DWD层还要走一次拉链表,因为还要考虑员工是否离职等很多因素。因此在写完拉链表的代码之后,我感觉自己快要升天了。
除了拉链表之外,在我们公司内部还有一个流水表,流水表比较简单,直接按天导入即可,没有所谓的对比更新逻辑。
标签:有一个 针对 完数 精确 标识 难点 中转 日期 一个
原文地址:https://www.cnblogs.com/traditional/p/13551572.html