标签:des style blog http io ar os sp for
本文描述一下:C运行时的数据结构,相关的段,压栈等
unix默认的编译器会将编译生成的文件默认命名为a.out
目标文件和可执行文件可以有几种不同的格式,所有这些不同格式具有一个共同的概念,那就是段。
这里的段表示一个二进制文件相关的内容块。
用size + 可执行文件名 可以显示这个文件的三个段(文本段,数据段和BSS段)的大小
文本段是用于保存编译后的指令的。
数据段是用于保存初始化的全局和静态变量。
BBS(Block Started by Symbol)由符号开始的块,用于保存没有值的变量,貌似并不需要保存这些变量的映像,BBS段不占据目标文件的任何空间。
如图是相应代码和对应编译后目标文件的段:

#include<stdio.h>
main()
{
printf("hello world!\n");
}
下面来size一下这段代码编译后的文件:

text表示文本段,data表示数据段,bss表示 BSS段,
dec表示十进制三个段总和,hex是表示十六进制总和。
接下来在上述代码中加入一个全局的int[1000]的数组声明:
#include<stdio.h>
int a[1000];
main()
{
printf("hello world!\n");
}

说明声明了一个全局变量数组只增加了bss段,增加了4028。
现在将它初始化
#include<stdio.h>
int a[1000] = {1};
main()
{
printf("hello world!\n");
}

发现bss段变回原来的4,数据段增加了4024,这里为什么不是和bss一样增加了4028呢?
int[1000]应该只占用了4000字节,其他的可能是有存一下指针或者段的分割标志之类的吧,具体不是很清楚呀,希望知道的朋友告诉我一下。
在函数内声明一个巨大的数组
#include<stdio.h>
int a[1000] = {1};
main()
{
printf("hello world!\n");
int b[1000000];
}

发现并未变化,现在将其初始化:
#include<stdio.h>
int a[1000] = {1};
main()
{
printf("hello world!\n");
int b[1000000] = {1};
}

发现初始化的局部数组b使得文本段增加了。
数据段是保存在目标文件中的。
BBS段不保存在目标文件中的。
文本段是最容易受优化措施影响的段。
a.out文件的大小受调试状态下编译的影响,但段不受影响。
下面来看开进程的地址空间图:
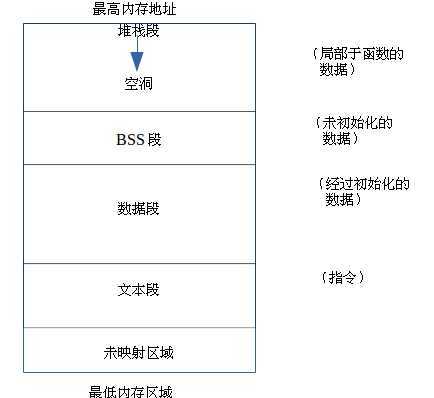
堆栈段主要有三个用途,其中两个跟函数有关,另一个跟表达式计算有关。
1.堆栈为函数内部声明的局部变量提供储存空间。
2.进行函数调用时,堆栈储存与此有关的一些维护性的信息。
3.堆栈也可以被用作暂时存储区。
堆栈的建立顺序大致为:
参数入栈
返回地址入栈
代码跳转到被调用函数处执行
EBP指针入栈
为局部变量分配地址
通用寄存器入栈
参考:http://www.cnblogs.com/Binhua-Liu/archive/2010/08/24/1803095.html
他这里是vs下编译的,linux下可能有一些不同,具体的还没研究,希望到时再研究一下~
标签:des style blog http io ar os sp for
原文地址:http://www.cnblogs.com/george-cw/p/4089806.html