标签:idt group -- ide 节点 color 详细 col 数据存储
这里以es多节点集群部署来做说明。单节点与之类似。基于es 7.1版本。
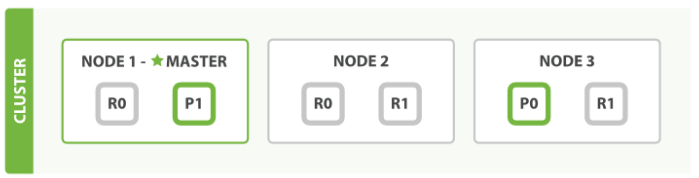
集群模式下,对于document的检索称为 Distribute document search。在简单的三节点集群中,假设一个index有两个primary shard,每个shard有2个replicate。如下图:其中,P0,P1为两个primary shard,NODE1和NODE2上的R0为P0的两个replicate,NODE2和NODE3上的R1为P1的两个replicate。P0+R0+R0为一个replicate group,P1+R1+R1为一个replicate group。按照es的存储原则,一个节点上至多存储同一个replicate group中的一个shard。
我们知道,es的底层是lucene,而lucene是一个全文搜索引擎,显而易见的,es很重要的功能就是全文检索,附带数据存储功能。当集群接收到来自客户端的文档检索请求,es除了要返回符合条件的内容,还要对返回的内容进行打分,按照搜索引擎的工作形式,将打分从高(也既从es看来最符合用户要求的数据)到低的顺序返回给客户端。es将这两项工作分成了两步来完成:query+fetch。
首先,集群中的某个节点,接收到来自客户端的request,request可能包含了某个条件,并且包含了分页参数from和size,假设是这样的:
GET ac_blog/_search?preference=123456789 { "query": { "bool": { "must": [ {"match": { "title": "entry" }} ] } }, "from":100, "size":10 }
要从ac_blog这个index获取title(text类型)包含entry的文档,获取排序100--109的document。这里留意一下,es里,from的下标是从0开始的。
要完成这个request,在query的步骤里,es将请求分发到各个replicate group中的一个shard里,至于是哪个shard,es是采用round-robin的方式选择shard的(在7.1版本,还会额外考虑allocation awareness 和adaptive replica selection),确保各个shard的负载均衡。shard在自己内部根据条件检索到对应的文档,并按照_score由高到低排序,获取从0到109共110个文档的_id以及_score返回给node3。为哈是110个而不是10个,这个后面解释。如下图所示:
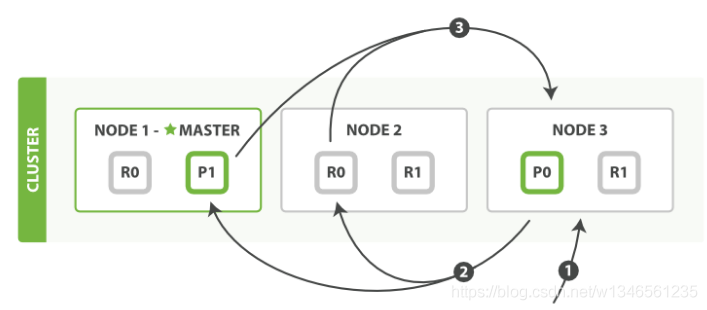
1,request到达node3,此时node3作为coordinator;
2,node3分发请求到node1的P1分片和NODE2的R0分片;
3,P1和R0在分片内部检索数据,并返回id与score给node3.
此时,NODE3拿到了220个文档,然后从这220个文档里,按照score从高到低排序,取100-109排序的文档,其余丢弃。然后根据文档id构造_mget请求,到对应的分片获取document的完整内容,并返回给客户端。这是fetch阶段。如下图所示:
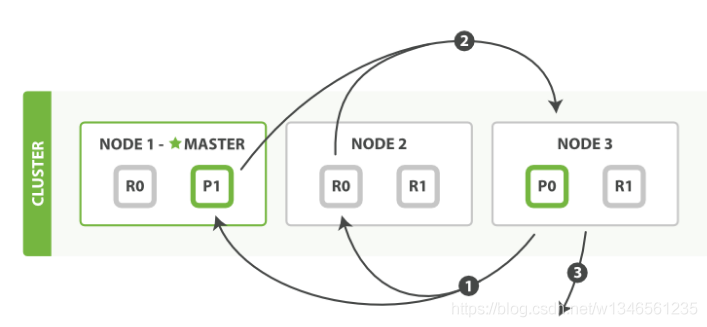
1,node3将选中的文档id发回对应分片;
2,分片返回完整document内容;
3,node3将文档内容返回给客户端.
到此,整个检索过程就结束了。但是其中有一些细节需要详细描述。
首先,query阶段,分片为何返回110个文档,而不是10个文档给coordinator?这是因为分片是在各自的内部进行排序的,这只是局部的顺序,并不是整个index的全局排序,因此需要将前110个文档返回给coordinator,由coordinator进行全局排序,确定最终的结果。这也是整个检索过程中较为耗时的地方。假如请求的是from=100000,size=10呢?假如有10个replicate group呢?资源耗费巨大。
标签:idt group -- ide 节点 color 详细 col 数据存储
原文地址:https://www.cnblogs.com/chong-zuo3322/p/13553909.html