标签:running 因此 最大 yam 默认 效果 相同 本地 本机
前言在一切虚拟化解决方案中,数据的持久化都是需要我们非常关心的问题,docker如此,K8s也不例外。在k8s中,有一个数据卷的概念。
*k8s数据卷主要解决了以下两方面问题:*
* 数据持久性:通常情况下,容器运行起来后,写入到其文件系统的文件时暂时性的。当容器崩溃后,kebelet
将这个容器kill掉,然后生成一个新的容器,此时,新运行的容器将没有原来容器内的文件,因为容器是重新从镜像创建的。
* 数据共享:同一个pod中运行的容器之间,经常会存在共享文件/文件夹的需求。在k8s中,Volume(数据卷)存在明确的生命周期(与包含该数据卷的容器组(pod)相同)。因此Volume的生命周期比同一容器组(pod)中任意容器的生命周期要更长,不管容器重启了多少次,数据都被保留下来。当然,如果pod不存在了,数据卷自然退出了。此时,根据pod所使用的数据卷类型不同,数据可能随着数据卷的退出而删除,也可能被真正持久化,并在下次容器组重启时仍然可以使用。
从根本上来说,一个数据卷仅仅是一个可以被pod访问的目录或文件。这个目录是怎么来的,取决于该数据卷的类型(不同类型的数据卷使用不同的存储介质)。同一个pod中的两个容器可以将一个数据卷挂载到不同的目录下。
k8s目前支持28种数据卷类型(其中大多数特定于云环境),这里将写下在k8s中常用的几种数据卷类型如下:
1、emptyDir
emptyDir类型的数据卷在创建pod时分配给该pod,并且直到pod被移除,该数据卷才被释放。该数据卷初始分配时,始终是一个空目录。同一个pod中的不同容器都可以对该目录执行读写操作,并且共享其中的数据(尽管不同容器可能将该数据卷挂载到容器中的不同路径)。当pod被删除后,emptyDir数据卷中的数据将被永久删除。(PS:容器奔溃时,kubelet并不会删除pod,而仅仅是将容器重启,因此emptyDir中的数据在容器崩溃并重启后,仍然是存在的)。
emptyDir的使用场景如下:
* 空白的初始空间,例如合并/排序算法中,临时将数据保存在磁盘上。
* 长时间计算中存储检查点(中间结果),以便容器崩溃时,可以从上一次存储的检查点(中间结果)继续进行,而不是从头开始。
* 作为两个容器的共享存储,使得第一个内容管理的容器可以将生成的数据存入其中,同时由一个webserver容器对外提供这些页面。
* 默认情况下,emptyDir数据卷存储在node节点的存储介质(机械硬盘、SSD或网络存储)上。emptyDir的使用示例
[root@master yaml]# vim emptyDir.yaml
apiVersion: v1
kind: Pod
metadata:
name: producer-consumer //定义Pod的名称
spec:
containers:
- image: busybox
name: producer //定义容器的名称
volumeMounts:
- mountPath: /producer_dir //指定容器内的路径
name: shared-volume //表示把shared-volume挂载到容器中
args: //当容器运行完成后,执行以下的写操作
- /bin/sh
- -c
- echo "hello k8s" > /producer_dir/hello; sleep 30000
- image: busybox
name: consumer //定义容器的名称
volumeMounts:
- mountPath: /consumer_dir
name: shared-volume //与上一个容器一样
args:
- /bin/sh
- -c
- cat /consumer_dir/hello; sleep 30000
volumes:
- name: shared-volume //定义数据卷的名称,必须与以上挂载的数据卷名称一致
emptyDir: {} //定义一个类型为emptyDir的数据卷,名称为shared-volume
[root@master yaml]# kubectl apply -f emptyDir.yam //生成所需的Pod资源
[root@master yaml]# kubectl exec -it producer-consumer -c producer /bin/sh
//进入第一个容器进行验证
/ # cat /producer_dir/hello
hello k8s
[root@master yaml]# kubectl exec -it producer-consumer -c consumer /bin/sh
//进行第二个容器进行验证
/ # cat /consumer_dir/hello
hello k8s注:到此可以看出这个pod中的两个容器指定的目录内容都是一样的,具体是本地的那个目录还需进一步进行验证。
[root@master yaml]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
producer-consumer 2/2 Running 0 7m58s 10.244.2.2 node01 <none> <none>
//可以看出这个pod是运行在node01上的node01:
[root@node01 ~]# docker ps | grep busybox //通过此命令查看容器的ID号
60806212f198 busybox "/bin/sh -c ‘cat /co…" 7 minutes ago Up 7 minutes k8s_consumer_producer-consumer_default_d4c5ba5c-d16e-4549-8456-94575c511b96_0
918e6ca1b218 busybox "/bin/sh -c ‘echo \"h…" 7 minutes ago Up 7 minutes k8s_producer_producer-consumer_default_d4c5ba5c-d16e-4549-8456-94575c511b96_0
[root@node01 ~]# docker inspect 60806212f198 //查看第一个容器的详细信息
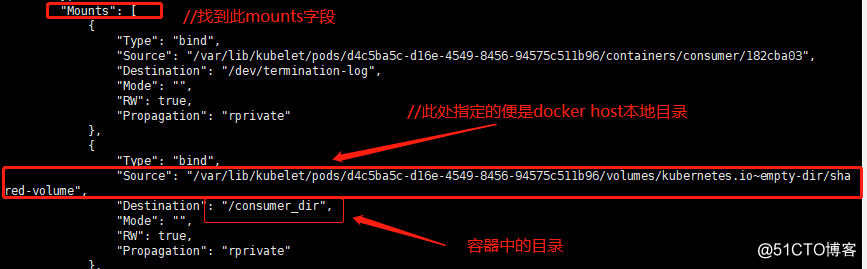
[root@node01 ~]# docker inspect 918e6ca1b218 //查看第二个容器的详细信息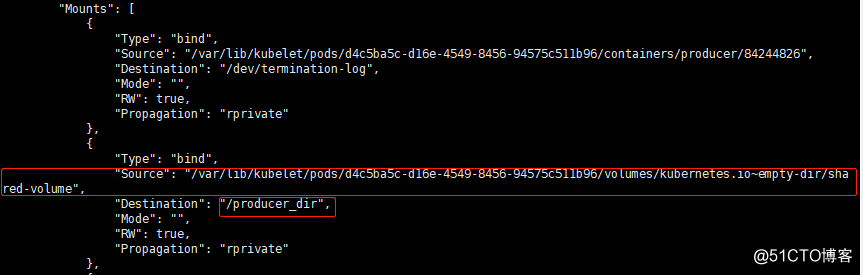
//从以上内容可以看出这两个容器的源目录是一样,挂载的是docker host本地的同一个目录
[root@node01 ~]# cd /var/lib/kubelet/pods/d4c5ba5c-d16e-4549-8456-94575c511b96/volumes/kubernetes.io~empty-dir/shared-volume
[root@node01 shared-volume]# ls
hello
[root@node01 shared-volume]# cat hello
hello k8s
//查看本地该目录下的内容,和pod中的一致至此,emptyDir的特性就已经验证了,只要这个pod中还有一个容器在运行,那么这个本地的数据就不会丢失,但如果这个pod被删除,那么本地的数据也将不复存在。
验证如下:
node01上删除一个pod并再次查看本地目录:
[root@node01 ~]# docker rm -f 60806212f198 //删除一个pod
60806212f198
[root@node01 ~]# cd /var/lib/kubelet/pods/d4c5ba5c-d16e-4549-8456-94575c511b96/volumes/kubernetes.io~empty-dir/shared-volume
[root@node01 shared-volume]# cat hello
hello k8s
//查看本地目录,发现文件还在master上将此pod删除,再次去node01节点上查看本地目录是否存在:
[root@master ~]# kubectl delete -f emtydir.yaml
//master上删除pod
//在node01上再次查看本地目录,会提示不存在这个目录
[root@node01 ~]# cat /var/lib/kubelet/pods/d4c5ba5c-d16e-4549-8456-94575c511b96/volumes/kubernetes.io~empty-dir/shared-volume
cat: /var/lib/kubelet/pods/d4c5ba5c-d16e-4549-8456-94575c511b96/volumes/kubernetes.io~empty-dir/shared-volume: 没有那个文件或目录emptyDir总结:
同个pod里面的不同容器,共享同一个持久化目录,当pod节点删除时,volume的内容也会被删除。但如果仅仅是容器被销毁,pod还在,则volume不会受到任何影响。说白了,emptyDir的数据持久化的生命周期和使用的pod一致。一般是作为临时存储使用。
2、HostPath数据卷类型
hostPath 类型的数据卷将 Pod(容器组)所在节点的文件系统上某一个文件或目录挂载进容器组(容器内部),类似于docker中的bind mount挂载方式。
这种数据持久化的方式,使用场景不多,因为它增加了pod与节点之间的耦合。
绝大多数容器组并不需要使用 hostPath 数据卷,但是少数情况下,hostPath 数据卷非常有用:
适用场景如下:
* 某容器需要访问 Docker,可使用 hostPath 挂载宿主节点的 /var/lib/docker
* 在容器中运行 cAdvisor,使用 hostPath 挂载宿主节点的 /sys
* 总言而之,一般对K8s集群本身的数据持久化和docker本身的数据持久化会使用这种方式。注:由于其使用场景比较少,这里就不举例了。
3、Persistent 数据卷类型
PersistentVolume(PV存储卷)是集群中的一块存储空间,由集群管理员管理或者由Storage class(存储类)自动管理,PV和pod、deployment、Service一样,都是一个资源对象。
既然有了PV这个概念,那么PVC(PersistentVolumeClaim)这个概念也不得不说一下,PVC代表用户使用存储的请求,应用申请PV持久化空间的一个申请、声明。K8s集群可能会有多个PV,你需要不停的为不同的应用创建多个PV。
比如说,pod是消耗node节点的计算资源,而PVC存储卷声明是消耗PV的存储资源。Pod可以请求的是特定数量的计算资源(CPU或内存等),而PVC请求的是特定大小或特定访问模式(只能被单节点读写/可被多节点只读/可被多节点读写)的存储资源。
PV(存储卷)和PVC(存储卷声明)的关系如下图所示: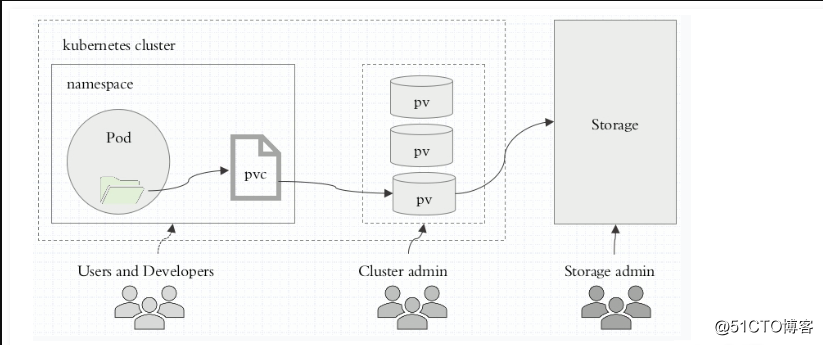
上图中的解释如下:
* PV是集群中的存储资源,通常由集群管理员创建和管理;
* StorageClass用于对PV进行分类,如果配置正确,Storage也可以根据PVC的请求动态创建PV;
* PVC是使用该资源的请求,通常由应用程序提出请求,并指定对应的StorageClass和需求的空间大小;
* PVC可以作为数据卷的一种,被挂载到pod中使用。
PV和PVC的管理过程描述如下:
1、在主机上划分出一个单独的目录用于PV使用,并且定义其可用大小
2、创建PVC这个资源对象,以便请求PV的存储空间
3、pod中添加数据卷,数据卷关联到PVC;
4、Pod中包含容器,容器挂载数据卷其实上面解释那么多,可能还是云里雾里的,下面是一个使用案例,仅供参考。
案例大概过程如下:
底层存储采用nfs存储,然后在nfs的目录下划分1G的容量供PV调度。然后通过创建PVC来申请PV的存储资源空间,最后创建pod测试,使用PVC声明的存储资源来实现数据的持久化。
1)搭建nfs存储
为了方便操作,我直接在master上搭建nfs存储。
[root@master ~]# yum -y install nfs-utils rpcbind
[root@master ~]# vim /etc/exports
/nfsdata *(rw,sync,no_root_squash)
[root@master ~]# systemctl start nfs-server
[root@master ~]# systemctl start rpcbind
[root@master ~]# showmount -e
Export list for master:
/nfsdata *2)创建PV资源对象
[root@master ~]# vim test-pv.yaml //编辑PV的yaml文件
apiVersion: v1
kind: PersistentVolume
metadata:
name: test-pv
spec:
capacity:
storage: 1Gi //该PV可分配的容量为1G
accessModes:
- ReadWriteOnce //访问模式为只能以读写的方式挂载到单个节点
persistentVolumeReclaimPolicy: Recycle //回收策略为Recycle
storageClassName: nfs //定义存储类名字
nfs: //这里和上面定义的存储类名字需要一致
path: /nfsdata/test-pv //指定nfs的目录
server: 192.168.45.129 //nfs服务器的IP
#关于上述的具体解释
//capacity:指定PV的大小
//AccessModes:指定访问模式
//ReadWriteOnce:只能以读写的方式挂载到单个节点(单个节点意味着只能被单个PVC声明使用)
//ReadOnlyMany:能以只读的方式挂载到多个节点
//ReadWriteMany:能以读写的方式挂载到多个节点
//persistentVolumeReclaimPolicy:PV的回收策略
//Recycle:清除PV中的数据,然后自动回收。
//Retain:需要手动回收。
//Delete:删除云存储资源。(云存储专用)
//PS:注意这里的回收策略是指,在PV被删除后,在这个PV下所存储的源文件是否删除。
//storageClassName:PV和PVC关联的依据。
[root@master ~]# kubectl get pv test-pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
test-pv 1Gi RWO Recycle Available nfs 43s
//查看PV的状态必须为Available才可以正常使用3)创建PVC资源对象
[root@master ~]# vim test-pvc.yaml //编写yaml文件
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: test-pvc
spec:
accessModes: //定义访问模式,必须和PV定义的访问模式一致
- ReadWriteOnce
resources:
requests:
storage: 1Gi //直接请求使用最大的容量
storageClassName: nfs //这里的名字必须和PV定义的名字一致
[root@master ~]# kubectl apply -f test-pvc.yaml //执行yaml文件
[root@master ~]# kubectl get pv,pvc
//再次查看PV及PVC的状态(状态为bound,表示该PV正在被使用)
//下列表示pv和pvc已经关联上了
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/test-pv 1Gi RWO Recycle Bound default/test-pvc nfs 2m33s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/test-pvc Bound test-pv 1Gi RWO nfs 24s
注:上述yaml文件中,主要字段的解释:
1)accessModes(访问模式)
* ReadWriteOnce:以读写的方式挂载到单个节点;
* ReadWriteMany:以读写的方式挂载到多个节点 ;
* ReadOnlyMany:以只读的方式挂载到多个节点;2)persistentVolumeReclaimPolicy(PV的回收策略)
* Recycle:自动清除PV中的数据,自动回收;
* Retain:需要手动回收;
* Delete:删除云存储资源(云存储专用);4)创建一个Pod
这里创建的pod使用刚刚创建的PV来实现数据的持久化。
[root@master ~]# vim test-pod.yaml #编写pod的yaml文件
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
- name: test-pod
image: busybox
args:
- /bin/sh
- -c
- sleep 30000
volumeMounts:
- mountPath: /testdata
name: volumedata #这里自定义个名称
volumes:
- name: volumedata #这里的是上面定义的名称解释,这两个名称必须一致
persistentVolumeClaim:
claimName: test-pvc
[root@master ~]# kubectl apply -f test-pod.yaml #执行yaml文件
[root@master ~]# kubectl get pod
//查看pod的状态,发现其一直处于ContainerCreating状态,但是查看时间,这么长时间没有创建好,不太正常
NAME READY STATUS RESTARTS AGE
test-pod 0/1 ContainerCreating 0 23s排错方法如下:
* 当遇到pod状态不正常时,一般我们可以采用三种方式来排错
* 第一就是使用kubectl describe命令来查看pod的详细信息
* 第二就是使用kubectl logs命令来查看pod的日志
* 第三就是查看宿主机本机的message日志这里我采用第一种方法排错!!!
[root@master ~]# kubectl describe pod test-pod
//根据提示最后的一条的信息如下:
mount.nfs: mounting 192.168.45.129:/nfsdata/test-pv failed, reason given by server: No such file or directory
//原来是我们在挂载nfs存储目录时,指定的目录并不存在
//那就在nfs服务器上(这里是本机)进行创建相关目录咯
[root@master ~]# mkdir -p /nfsdata/test-pv //创建对应目录
[root@master ~]# kubectl get pod test-pod //然后再次查看pod的状态
NAME READY STATUS RESTARTS AGE
test-pod 1/1 Running 0 8m59s
//发现已成功启动了5)测试其数据持久化的效果
[root@master ~]# kubectl exec -it test-pod /bin/sh //进入pod
/ # echo "hello pv,pvc" >/testdata/test.txt //数据持久化的目录写入测试信息
//到nfs服务器,查看共享的目录下是否有容器中写入的信息
[root@master ~]# cat /nfsdata/test-pv/test.txt
hello pv,pvc
[root@master ~]# kubectl get pod test-pod -o wide
//查看容器运行在node02节点上了
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-pod 1/1 Running 0 14m 10.244.1.2 node02 <none> <none>
node02节点上:
[root@node02 ~]# docker ps //查看容器ID
[root@node02 ~]# docker rm -f 2af647789525 //删除刚刚创建的容器
master节点上:
[root@master ~]# cat /nfsdata/test-pv/test.txt
hello pv,pvc
//那么现在测试,将这个pod删除,nfs本地的数据是否还在?
[root@master ~]# kubectl delete -f test-pod.yaml
[root@master ~]# cat /nfsdata/test-pv/test.txt //发现数据还在
test pv pvc
//那现在要是将PVC删除呢?
[root@master ~]# kubectl delete -f test-pvc.yaml
[root@master ~]# cat /nfsdata/test-pv/test.txt //发现数据不存在了
cat: /nfsdata/test-pv/test.txt: 没有那个文件或目录
总结:由于我们在创建pv这个资源对象时,采用的回收策略是清除PV中的数据,然后自动回收,而PV这个资源对象是由PVC来申请使用的,所以不管是容器也好,pod也好,它们的销毁并不会影响用于实现数据持久化的nfs本地目录下的数据,但是,一旦这个PVC被删除,那么本地的数据就会随着PVC的销毁而不复存在,也就是说,采用PV这种数据卷来实现数据的持久化,它这个数据持久化的生命周期是和PVC的生命周期是一致的。
标签:running 因此 最大 yam 默认 效果 相同 本地 本机
原文地址:https://blog.51cto.com/14306186/2522109