标签:cond not 放大 评估 脚本 聚合 查看 忽略 开始
分析器顾名思义就是对测试结果数据进行分析的组件,它是LoadRunner三大组件之一,其重要性不言而喻。在Controller组件执行场景的过程中,LoadRunner会将数据收集起来并保存到数据库中。当场景执行完成后,可以进入Analysis组件对这些数据进行分析。分析器中保存着大量用来分析性能测试结果的数据视图,但并不一定要对每个视图进行分析,可以根据实际情况选择相关的数据视图进行分析,分析结果可以生成一些不同格式的测试报告。
主要讲述以下几部分内容:
Analysis简介
摘要报告
Analysis常见图分析
Analysis报告
介绍Analysis分析器如何收集数据,在分析器中对视图进行分析中常用到的设置选项;介绍分析视图中的摘要报告的内容;分析器中常用的分析视图,最后介绍通过分析器如何生成测试报告。
要分析系统瓶颈,就必须借助LoadRunner分析器中的数据来帮助分析。在场景执行过程中,LoadRunner会收集执行过程中的数据,并将数据存储到结果文件中,其扩展名为.lrr。在Analysis分析器,打开保存的结果文件,Analysis会对收集到的信息进行处理,并生成图和报告。
Analysis会话至少包含一组方案结果(lrr文件)。Analysis会将活动图的显示信息和布局设置存储在扩展名为.lrr的文件中。
关于数据分析,不仅仅局限于只在Analysis分析器中对数据进行分析,可以采用多种方式进行分析:
Vuser日志文件:Vuser日志文件包括每个Vuser运行方案的完整跟踪。这些文件位于方案结果目录中。
Controller输出窗口:在Controller输出窗口会显示出整个方案运行过程中的错误或警告信息,当然其中最关注的信息还是输出的错误信息,通过查看这些错误信息有利于帮助性能调试工作。
Analysis图:通过使用一些分析技术对数据图表进行合并、关联等操作,更好地帮助分析事务、Vuser等其他的一些信息。
“图数据”视图和“原始数据”视图以电子表格形式显示用于生成图的实际数据。当然也可以将这些数据复制到外部电子表格应用程序中进行处理。
报告形式:LoadRunner自动带了多种格式的报告供分析。那么Analysis中的数据是怎么得到的呢?其实在场景运行的时候,默认情况下,所有的Vuser信息都保存在该Vuser的负载机上。只有当场景运行结束之后,这些数据才会自动进行整理或合并,这时负载机上所有的Vuser的信息和数据都将被传输到结果目录中。默认情况下,在Controller控制器中,Results→AutoCollateResults是被选中的,如图所示。也就是说默认情况下,当场景运行结束后,这些数据会被自动整理或合并。当然如果不希望自动整理或合并这些数据,可以不选中这一项。但不选中这一项,并不代表不会对这些数据进行整理或合并,在Analysis分析器对这些数据进行分析之前,Analysis会对这些数据进行整理。或者可以在Controller控制器中选择Results→CollateResults进行手动整理。 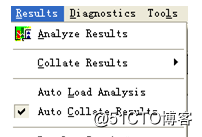
同时关于场景运行过程中结果如何保存也需要设置,在Controller控制器中选择Results→ResultsSettings,弹出如图所示的对话框。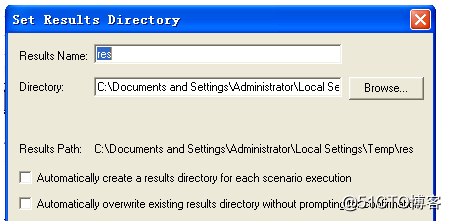
ResultsName:设置结果保存的名称;
Directory:是指结果保存的路径,一般情况结果路径不应该包括中文字符,这样有可能会导致弹出来的错误信息对话框中的信息无法正确的查询。
而保存结果的情况又分为以下两种情况:
Automaticallycreatearesultsdirectoryeachscenarioexecution:每执行一次场景都生成一份结果文件,结果文件的命名方式为res后接一个序号(如res0),每执行一次序号依次加一。
Automaticallyoverwriteexistingresultsdirectorywithoutpromptingforconfirmation:每执行一次场景,将执行后的结果覆盖以前的结果。
在场景策略中应该设置好结果保存的方式,为了防止丢失一些不必要的结果,一般会选择第一种结果保存方式。
在进行数据视图分析之前,有必要将分析图中涉及到的一些设置项设置完成。那么为什么在分析图之前要进行设置呢?原因很简单,当场景运行结束后,分析器收集到的所有数据都是原始的数据,未经过任何条件筛选的数据,这样就有很多“杂质”并不方便对数据进行分析。下面介绍一些常用的设置选项的设置。
1.ResultCollection设置
在LoadRunner处理这些数据时,可以查看这些数据的摘要。具体怎样查看摘要数据,需要在ResultCollection选项中进行设置。
选择Tools→Options→ResultCollection,如图所示。
Datasource:
Generatesummarydataonly:表示仅查看摘要数据。如果选择该选项,那么Analysis不会处理数据以用于筛选和分组等高级用途。注意,当选择该项时,DataAggregation项是不可以设置的。
Generatecompletedataonly:表示仅查看经过处理的完整数据,但是不显示摘要数据。
Displaysummarywhilegeneratingcompletedata:表示在处理完整数据时,查看摘要数据。
DataAggregation:
Automaticallyaggregatedatatooptimizeperformance:表示使用内置数据聚合公式聚合数据,以优化性能。
AutomaticallyaggregateWebdataonly:表示使用内置数据聚合公式仅仅聚合与Web有关的数据。 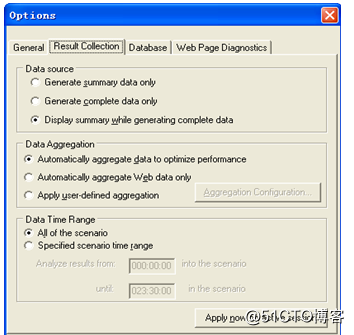
Applyuser-definedaggregation:表示用户自定义来设置聚合数据。点击按钮,会弹出聚合配置的对话框,如图所示。这里有以下几个设置项:
AggregateData(availableonlyforcompletedata):用于设置聚合数据的类型,这里只适用于完整数据。可以选择需要聚合数据的图的类型,这样可以减小数据库的容量。可供选择数据图的类型有Transactions、Web、Monitors、DataPoints和ScriptErrors几种。
Selectthegraphpropertiestoaggregate:指定要聚合的图属性,可选择的属性有VuserID、GroupName、ScriptName和DonotaggregatefailedVusers。
Webdataaggregationonly:表示仅聚合Web的数据,在这里可以设置聚合的粒度。 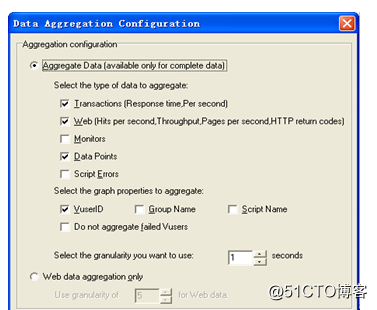
2.ConfigureMeasurements设置
在分析图时,有时会发现分析图的Y轴幅值过小,这时就可以通过设置ConfigureMeasurements,对Y轴进行适当的放大或缩小操作。
选择菜单View→ConfigureMeasurements选项,弹出ConfigureMeasurements设置对话框,如图所示。 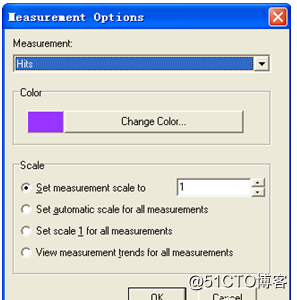
在这里Y轴的比例设置有四种选择:
Setmeasurementscaleto:手动设置一个比例值。
Setautomaticscaleforallmeasurements:使用优化的自动比例来显示图中每个度量。
Setscale1forallmeasurements:将图中所有度量比例都设置为1。
Viewmeasurementtrendsforallmeasurements:查看所有度量的趋势。值为1,即按原始比例进行显示,有时波形显示的幅值太小,那么就需要适当的调整放大的比例,如10倍、100倍等。
3.设置筛选条件
在结果分析的过程中,怎么提取最关键的数据,对分析结果是一个很重要的问题,在分析过程中可以对分析图中的数据进行筛选以提取最关键的数据。在Analysis分析器中,关于筛选有二种:如果只要设置单个图的筛选条件时,使用SetFilter/Graphby对话框,点击按钮;如果要设置方案中所有图的筛选条件时,使用SetGlobalFilter对话框,点击按钮;这二种筛选设置都大同小异,本质是一样的,没什么大的区别,下面主要讲述
SetFilter/Graphby对话框设置,如图所示。
筛选条件:在这里要为每个筛选条件选择条件和值。
条件:可以选择“=”(等号)或“<>”(不等号)。
值:从Values栏列表中选择一个值。筛选条件的值有三种类型,包括离散、连续和基于时间。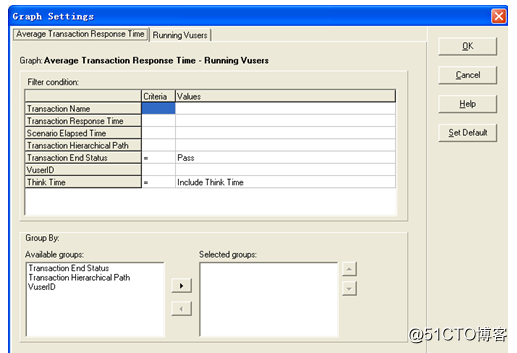
离散值是一个明确的整数值,如TransactionName下拉列表中会显示出所有的事务名。
注:在这里可以使用
TransactionHierarchicalPath事务树路径条件来筛选子事务。选择“事务名”以筛选父级的子事务,选择“无”以筛选父事务,或者选择“未知”以筛选其父级未知(通常由会话期间的嵌套错误引起)的子事务。
连续值是一个变量维度,可以在最小值和最大值范围限制内取任何值,如TransactionResponseTime。
基于时间的值是基于方案开始时间的值。
分组方式:使用这些设置来对图显示按组排序。有可用组和选定组两个复选框。
需要注意ThinkTime维度的设置,在录制测试脚本过程中,如果执行脚本时没有忽略ThinkTime时间,那么Analysis分析器在统计分析结果时会把ThinkTime包含进去。这样当ThinkTime存在于用户事务的开始与结束之间时,相关事务统计情况会受到影响。因此,很多时候需要过滤用户的思考时间。默认情况下ThinkTime的值设置为IncludeThinkTime,将下拉复选框中该选项去掉即可,分析结果中就会自动滤掉思考时间。
Analysis分析器中提供了丰富的分析图,常见的有8类:Vusers图、错误图、事务图、Web资源图、网页细分图、系统资源图、Web服务器资源图和数据库服务器资源图。选择Graph→AddGraph,如图所示。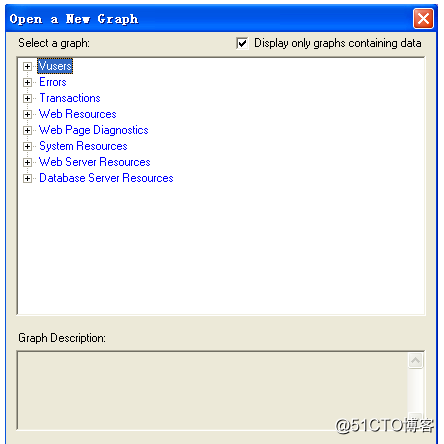
但是如果将图中
Displayonlygraphscontainingdata复选框的勾选去掉,会发现多出了很多其他类型的分析图,如图所示。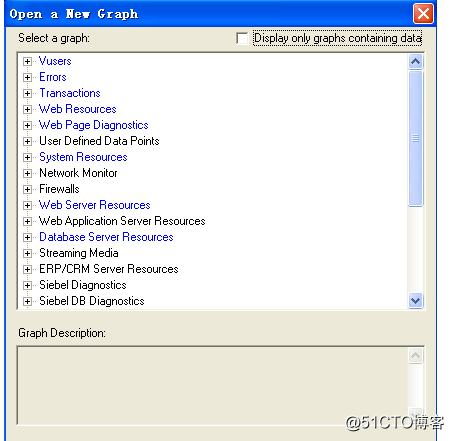
在实际分析的过程中,只有常见的几种分析图会使用到,其他的都很少使用到。
1.Vusers图
在方案执行过程中,Vuser在执行事务时生成数据。使用Vusers图可以确定方案执行期间Vuser的整体行为。它显示Vuser状态和完成脚本的Vuser的数量。主要包括正在运行的Vuser图和Vuser摘要图两种。
2.Errors图
在方案执行期间,并不是每个Vuser都一定会执行成功,可能有执行失败、停止或因错误而终止的情况。Errors图主要是统计方案执行时的错误信息。主要包括:ErrorStatistics(byDescription)、ErrorperSecond(byDescription)、ErrorStatistics和ErrorperSecond四种图。
3.事务图
事务图描述了整个脚本执行过程中的事务性能和状态。主要包括:平均事务响应时间图、每秒事务数图、每秒事务总数、事务摘要图、事务性能摘要图、事务响应时间(负载下)图、事务响应时间(百分比)图和事务响应时间(分布)图。
4.Web资源图
Web资源图主要提供有关Web服务器性能的一些信息。使用Web资源图可以分析方案运行期间每秒点击次数、服务器的吞吐量、从服务器返回的HTTP状态代码、每秒HTTP响应数、每秒页面下载数、每秒服务器重试次数、服务器重试摘要、连接数和每秒连接数。
5.网页细分图
网页细分图主要是提供一些信息来评估页面内容是否影响事务响应时间。如果出现影响事务响应时间的情况,可以通过细分图进一步分析是什么原因影响网页事务响应时间的。包括网页细分、页面组件细分、页面组件细分(随时间变化)、页面下载时间细分、页面下载时间细分(随时间变化)和已下载组件图几种。
6.系统资源图
系统资源图主要监控场景运行期间系统资源使用率的情况。可以监控Windows资源、UNIX资源、SNMP资源、AntaraFlameThrower资源和SiteScope资源。
7.Web服务器资源图
Web服务器资源图主要用来捕捉场景运行时Web服务器的信息。主要用来分析MicrosoftIIS服务器、Apache服务器、iPlanet/Netscape服务器和iPlanet(SNMP)服务器。
8.数据库服务器资源图
数据库服务器资源图主要显示数据库服务器的统计信息。目前支持DB2、Oracle、SQLServer和Sybase数据库。
LoadRunner性能测试系统学习教程:Analysis分析器(1)
标签:cond not 放大 评估 脚本 聚合 查看 忽略 开始
原文地址:https://blog.51cto.com/14645850/2521691