标签:基于 计算 分布 出现 反向 数据结构 单词 document 过程
上一篇文章 ElasticSearch 术语中提到了倒排索引,那么这篇文章就来讲解下什么是倒排索引,倒排索引的数据结构以及 ElasticSearch 中的倒排索引。倒排索引(Inverted Index) 也常被称为反向索引,是搜索引擎中非常重要的数据结构,为什么说它重要呢,我们首先拿一本书《重构 改善既有代码的设计》举个例子:
如果一本书没有目录的话,理论上也是可以读的,只是合上书下次再次阅读的时候,就有些耗费时间了。
通过给一本书加目录页,可以快速了解这本书的大致内容分布以及每个章节的页码数,这样在查询内容的时候效率就会非常高了,所以书的目录就是书本内容的简单索引。

目录页
想象一下你要搜索 case语句 这个关键词在这本书的页码,你应该怎么办呢?有些技术类的书籍会在最后提供索引页,这本书的索引页如下:

索引页
只需要从索引页中查找 case语句,就可以查找到关键词在书本中的页码位置了。
看完这个例子,让我们来把图书和搜索引擎做个简单的类比:
图书当中的目录页就相当正向索引(Forward Index),索引页就相当于倒排索引的简单实现,在搜索引擎中,正向索引指的是文档 ID 到文档内容和单词的关联,倒排索引就是单词到文档 ID 的关系。
下面来看一个很简单的例子:

如上有三篇文档,每篇文档的内容都是关于 ElasticSearch 的三本书,那我们思考下怎么样变为一个倒排索引呢?
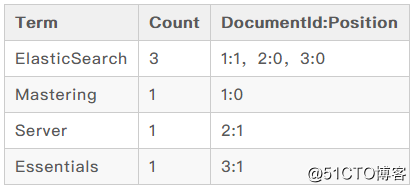
把书中内容出现所以的词都分成不同的关键词(Term),排列在第一栏,分别是 ElasticSearch,Mastering,Server 和 Essentials;第二栏是统计了关键词在所有内容中出现的次数,比如 ElasticSearch 在内容中出现了三次,就记为 3;第三栏标注的是文档 ID 和文档出现的位置,比如 ElasticSearch 在第 1,2,3 文档中都出现了,在第一个文档所处的位置是第二个,所以标注的为 1。
以上就是简单的正排索引和倒排索引的结构,下面让我们来看下倒排索引的数据结构:
倒排索引的核心分为两部分,第一部分为单词词典(Term Dictionary),记录所有文档的单词以及单词到倒排列表的关联关系。在前面的例子中,单词的量并不是很多,但是在实际生产中,单词量会非常大,所以实际会采用 B+ 树和哈希拉链法去存储单词的词典,以满足高性能的插入与查询。
第二部分是倒排列表(Posting List),它记录了单词对应文档的结合,倒排列表是由倒排索引项(Posting) 组成,倒排索引项包含:
下面我们来用一张图来整体看下倒排索引:
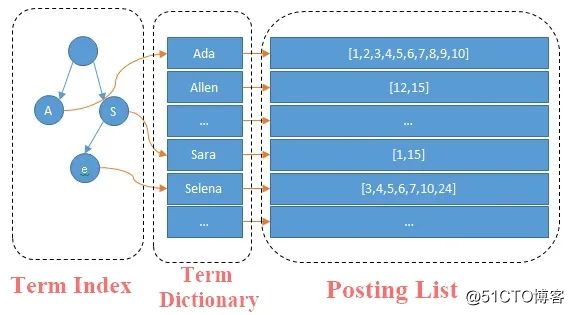
一个倒排索引是由单词词典(Term Dictionary)和倒排列表(Posting List)组成的,单词词典会记录倒排列表中每个单词的偏移位置。比如当搜索 Allen 的时候,首先会通过单词词典快速定位到 Allen,然后从 Allen 这里拿到在倒排列表中的偏移,快速定位到在倒排列表中的位置,从而真正拿到倒排索引项 [12,15](这里只是列了下 Document ID,其实是像上面讲的包含 4 项信息的项),拿到这个项可以去索引上拿到原始信息,可以去计算打分排序返回给用户。
再了解了倒排索引的数据结构后,让我们来看下 ES 中的倒排索引吧!
那么在 ElasticSearch 中的文档是基于 Json 格式的,其中一个文档包含多个字段,每个字段都会有自己的倒排索引。在 Mapping 中可以去设置对某些字段不做索引,这样做可以节省存储空间,但同时也会导致这个字段无法搜索了。
比如一个文档,其中包含两个字段 username 和 job:
{
"username":"wupx",
"job":"programmer"
}在构建索引的时候是根据字段构建的,那么 ES 中 username 会有一个倒排索引,job 也会有一个倒排索引。

这篇文章主要介绍了什么是倒排索引以及它的数据结构,下一篇文章将会学习如何在 ES 中分词来形成倒排索引。
参考文献
Elasticsearch核心技术与实战
https://dwz.cn/ELv7FvuX
完
●一篇文章带你搞定 ElasticSearch 术语
●深入源码分析SpringMVC执行过程
●你真的了解 volatile 关键字吗?

武培轩
有帮助?在看,转发走一波
喜欢作者
标签:基于 计算 分布 出现 反向 数据结构 单词 document 过程
原文地址:https://blog.51cto.com/14901336/2522708