标签:ica paper ext 概率 font 没有 标准 参数 image
AutoEncoder
这是一种非监督学习方式,主要用于数据的降维或者特征的抽取。
Autoencoder 实际上跟普通的神经网络没有什么本质的区别,分为输入层,隐藏层和输出层。
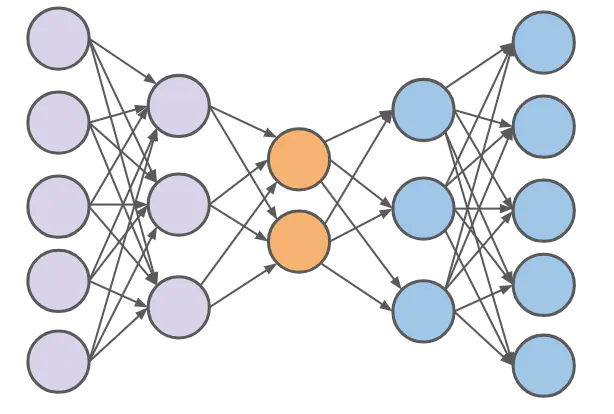
autoencoder的意义在于学习的(通常是节点数更少的)中间coder层(最中间的那一层),这一层是输入向量的良好表示。这个过程起到了“降维”的作用。
当autoencoder只有一个隐含层的时候,其原理相当于主成分分析(PCA)
当autoencoder有多个隐含层的时候,每两层之间可以用RBM来pre-training,最后由BP来调整最终权值
denoising autoencoder是autoencoder的一个变种,与autoencoder不同的是,denoising autoencoder在输入的过程中加入了噪声信息,从而让autoencoder能够学习这种噪声。
denoising autoencoder与RBM非常像:
(1)参数一样:隐含层偏置、显示层偏置、网络权重
(2)作用一样:压缩输入
(3)过程类似:都有reconstruct,并且都是reconstruct与input的差别,越小越好
denoising autoencoder与RBM的区别:
背后原理就不说了哈(RBM是能量函数),区别在于训练准则。RBM是隐含层“产生”显示层的概率(通常用log表示),denoising autoencoder是输入分布与reconstruct分布的KL距离。所用的训练方法,前者是CD-k,后者是梯度下降。
再补充一下,RBM固定只有两层;autoencoder,可以有多层,并且这些多层网络可以由标准的bp算法来更新网络权重和偏置,与标准神经网络不同的是,autoencoder的输入层和最终的输出层是“同一层”,不仅仅是节点数目、输出相同,而是完完全全的“同一层”,这也会影响到这一层相关的权值更新方式。总之,输入与输出是同一层,在此基础上,再由输入与输出的差别构造准则函数,再求各个参数的偏导数,再用bp方式更新各个权重......
Vincent在2008年的论文中提出了AutoEncoder的改良版——dA。推荐首先去看这篇paper。
论文的标题叫 "Extracting and Composing Robust Features",译成中文就是"提取、编码出具有鲁棒性的特征"
怎么才能使特征很鲁棒呢?就是以一定概率分布(通常使用二项分布)去擦除原始input矩阵,即每个值都随机置0, 这样看起来部分数据的部分特征是丢失了。
以这丢失的数据x‘去计算y,计算z,并将z与原始x做误差迭代,这样,网络就学习了这个破损(原文叫Corruputed)的数据。
这个破损的数据是很有用的,原因有二:
其之一,降噪
原因不难理解,因为擦除的时候不小心把输入噪声给×掉了。
其之二,破损数据一定程度上增加泛化性能。由于数据的部分被擦掉了,因而这破损数据
一定程度上比较接近测试数据。(训练、测试肯定有同有异,当然我们要求同舍异)。
标签:ica paper ext 概率 font 没有 标准 参数 image
原文地址:https://www.cnblogs.com/songsj/p/13551358.html