标签:lstat ppi layer 梳理 写入 tostring which rop miss
本文主要介绍ceph中paxos处理的不同阶段,以及关于paxos的问题在ceph中的贯穿角色。本文以paxos相关问题展开,本文重点为Paxos决议流程。本章节属于ceph中较为复杂的章节,需要不断的探索、分析。[toc]
//src/mon/mon_types.h
#define PAXOS_PGMAP 0 // before osd, for pg kick to behave
#define PAXOS_MDSMAP 1
#define PAXOS_OSDMAP 2
#define PAXOS_LOG 3
#define PAXOS_MONMAP 4
#define PAXOS_AUTH 5
#define PAXOS_MGR 6
#define PAXOS_MGRSTAT 7
#define PAXOS_HEALTH 8
#define PAXOS_NUM 9
inline const char *get_paxos_name(int p) {
switch (p) {
case PAXOS_MDSMAP: return "mdsmap";
case PAXOS_MONMAP: return "monmap";
case PAXOS_OSDMAP: return "osdmap";
case PAXOS_PGMAP: return "pgmap";
case PAXOS_LOG: return "logm";
case PAXOS_AUTH: return "auth";
case PAXOS_MGR: return "mgr";
case PAXOS_MGRSTAT: return "mgrstat";
case PAXOS_HEALTH: return "health";
default: ceph_abort(); return 0;
}
}初始化流程:
Monitor::Monitor(CephContext* cct_, string nm, MonitorDBStore *s,
Messenger *m, Messenger *mgr_m, MonMap *map)
paxos_service(PAXOS_NUM),
{
...
paxos = new Paxos(this, "paxos");
paxos_service[PAXOS_MDSMAP] = new MDSMonitor(this, paxos, "mdsmap");
paxos_service[PAXOS_MONMAP] = new MonmapMonitor(this, paxos, "monmap");
paxos_service[PAXOS_OSDMAP] = new OSDMonitor(cct, this, paxos, "osdmap");
paxos_service[PAXOS_PGMAP] = new PGMonitor(this, paxos, "pgmap");
paxos_service[PAXOS_LOG] = new LogMonitor(this, paxos, "logm");
paxos_service[PAXOS_AUTH] = new AuthMonitor(this, paxos, "auth");
paxos_service[PAXOS_MGR] = new MgrMonitor(this, paxos, "mgr");
paxos_service[PAXOS_MGRSTAT] = new MgrStatMonitor(this, paxos, "mgrstat");
paxos_service[PAXOS_HEALTH] = new HealthMonitor(this, paxos, "health");
...
}
//ceph_mon.cc
int main(int argc, const char **argv)
{
...
// start monitor
mon = new Monitor(g_ceph_context, g_conf->name.get_id(), store,
msgr, mgr_msgr, &monmap);
err = mon->preinit();
mon->init();
...
}
//Moinitor.cc
int Monitor::preinit()
{
...
init_paxos();
...
}
// src/ceph_mon.cc:main -> Monitor::preinit -> Monitor::init_paxos
void Monitor::init_paxos()
{
dout(10) << __func__ << dendl;
paxos->init();
// init services
for (int i = 0; i < PAXOS_NUM; ++i) {
paxos_service[i]->init();
}
refresh_from_paxos(NULL);
}
void Paxos::init()
{
// 加载paxos算法相关变量
last_pn = get_store()->get(get_name(), "last_pn"); // 最后一次提议编号
accepted_pn = get_store()->get(get_name(), "accepted_pn"); // 最后一次接受的提议编号
last_committed = get_store()->get(get_name(), "last_committed"); // 最后一次commit的版本
first_committed = get_store()->get(get_name(), "first_committed"); // 第一次commit的版本
}
void Monitor::dispatch_op(MonOpRequestRef op)
{
...
switch (op->get_req()->get_type()) {
// OSDs
case CEPH_MSG_MON_GET_OSDMAP:
case CEPH_MSG_POOLOP:
case MSG_OSD_BEACON:
case MSG_OSD_MARK_ME_DOWN:
case MSG_OSD_FULL:
case MSG_OSD_FAILURE:
case MSG_OSD_BOOT:
case MSG_OSD_ALIVE:
case MSG_OSD_PGTEMP:
case MSG_OSD_PG_CREATED:
case MSG_REMOVE_SNAPS:
paxos_service[PAXOS_OSDMAP]->dispatch(op);
break;
// MDSs
case MSG_MDS_BEACON:
case MSG_MDS_OFFLOAD_TARGETS:
paxos_service[PAXOS_MDSMAP]->dispatch(op);
break;
// Mgrs
case MSG_MGR_BEACON:
paxos_service[PAXOS_MGR]->dispatch(op);
break;
// MgrStat
case CEPH_MSG_STATFS:
// this is an ugly hack, sorry! force the version to 1 so that we do
// not run afoul of the is_readable() paxos check. the client is going
// by the pgmonitor version and the MgrStatMonitor version will lag behind
// that until we complete the upgrade. The paxos ordering crap really
// doesn‘t matter for statfs results, so just kludge around it here.
if (osdmon()->osdmap.require_osd_release < CEPH_RELEASE_LUMINOUS) {
((MStatfs*)op->get_req())->version = 1;
}
case MSG_MON_MGR_REPORT:
case MSG_GETPOOLSTATS:
paxos_service[PAXOS_MGRSTAT]->dispatch(op);
break;
// pg
case MSG_PGSTATS:
paxos_service[PAXOS_PGMAP]->dispatch(op);
break;
// log
case MSG_LOG:
paxos_service[PAXOS_LOG]->dispatch(op);
break;
// handle_command() does its own caps checking
case MSG_MON_COMMAND:
op->set_type_command();
handle_command(op);
break;
default:
dealt_with = false;
break;
}
...
}
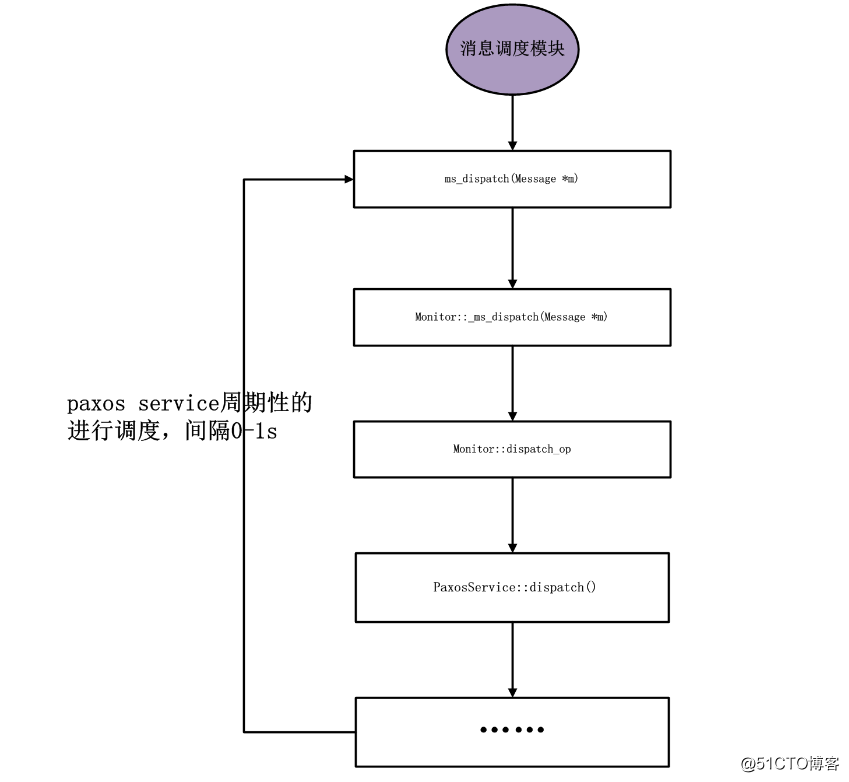
可以根据初始化流程看出上述所有dispatch函数都是基类的PaxosService::dispatch。
决议间隔时间由配置项paxos_propose_interval确定,默认值是1s,paxos_min_wait是最小间隔时间,默认0.05s。
两个配置项的用途:
bool PaxosService::should_propose(double& delay)
{
// simple default policy: quick startup, then some damping.
if (get_last_committed() <= 1) {
delay = 0.0;
} else {
utime_t now = ceph_clock_now();
if ((now - paxos->last_commit_time) > g_conf->paxos_propose_interval)//paxos_propose_interval=1s
delay = (double)g_conf->paxos_min_wait;//paxos_min_wait=0.05s 长时间没有决议,则强制delay paxos_min_wait
else
delay = (double)(g_conf->paxos_propose_interval + paxos->last_commit_time
- now);//delay时间会从paxos_propose_interval去掉已经耗费的时间,也就是上次决议时间也算在paxos_propose_interval间隔内,并不是固定1s
}
return true;
}之所以有这2个间隔,主要是为了防止决议过程阻塞dispatch线程,尤其是paxos_min_wait这个只有0.05s,实际上这么短时间的定时器是没有意义的,主要是为了切换到timer线程。
在决议间隔时间段内,所有的待决议提案都是保存在内存中的,等待delay时间到了才进行决议:
bool PaxosService::dispatch(MonOpRequestRef op)
{
...
double delay = 0.0;
if (!should_propose(delay)) {
dout(10) << " not proposing" << dendl;
return true;
}
if (delay == 0.0) {
propose_pending();
return true;
}
// delay a bit
if (!proposal_timer) {
/**
* Callback class used to propose the pending value once the proposal_timer
* fires up.
*/
auto do_propose = new C_MonContext(mon, [this](int r) {
proposal_timer = 0;
if (r >= 0) {
propose_pending();//go---
} else if (r == -ECANCELED || r == -EAGAIN) {
return;
} else {
assert(0 == "bad return value for proposal_timer");
}
});
dout(10) << " setting proposal_timer " << do_propose
<< " with delay of " << delay << dendl;
proposal_timer = mon->timer.add_event_after(delay, do_propose);
} else {
dout(10) << " proposal_timer already set" << dendl;
}
return true;
}
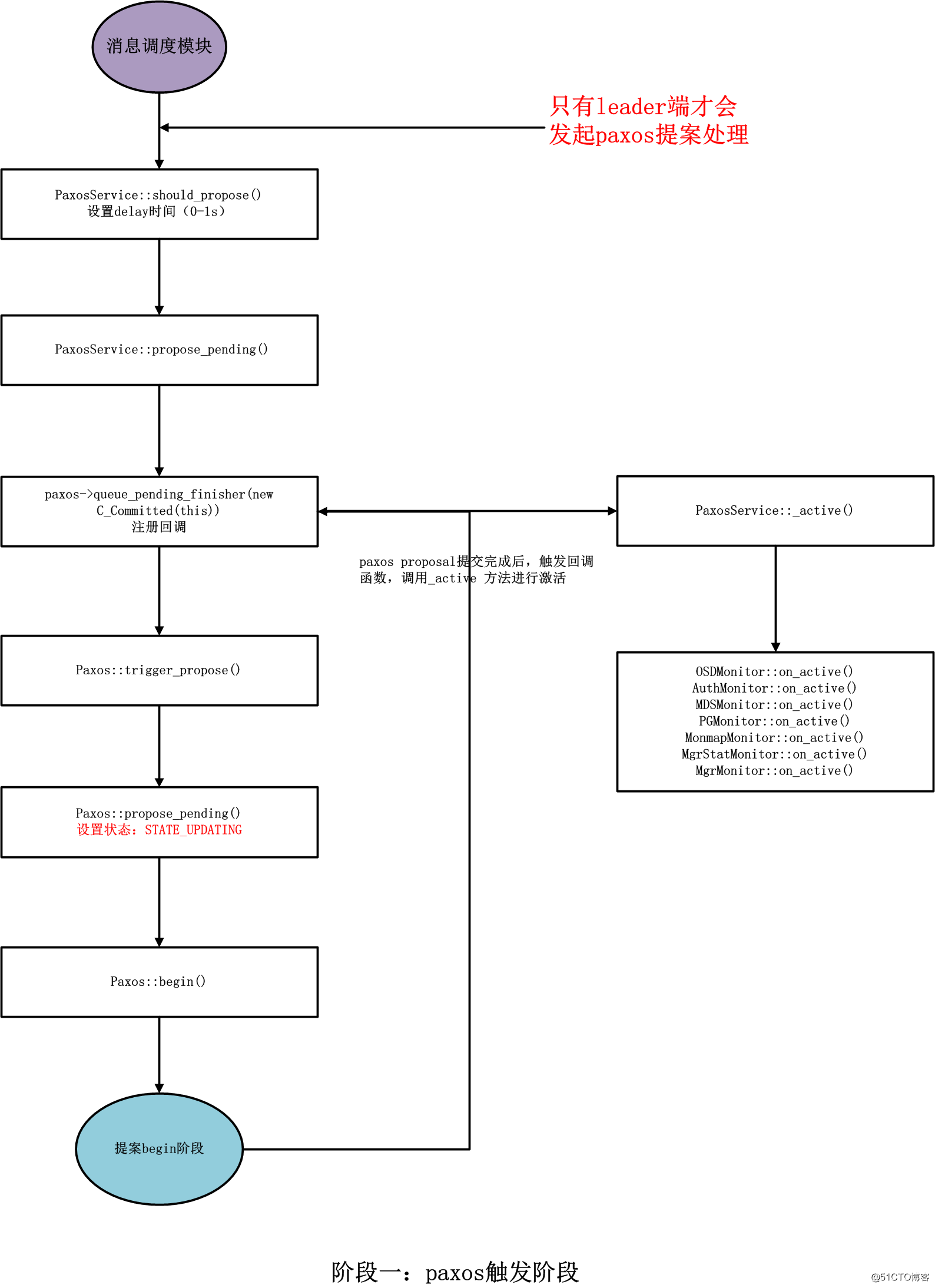
void PaxosService::propose_pending()
{
dout(10) << __func__ << dendl;
assert(have_pending);
assert(!proposing);
assert(mon->is_leader());
assert(is_active());
if (proposal_timer) {
dout(10) << " canceling proposal_timer " << proposal_timer << dendl;
mon->timer.cancel_event(proposal_timer);
proposal_timer = NULL;
}
MonitorDBStore::TransactionRef t = paxos->get_pending_transaction();
encode_pending(t);// 把pending_inc中的更新信息编码到bufferlist中,便于在多个monitor之间传递
have_pending = false;
class C_Committed : public Context {
PaxosService *ps;
public:
explicit C_Committed(PaxosService *p) : ps(p) { }
void finish(int r) override {
ps->proposing = false;
if (r >= 0)
ps->_active();
else if (r == -ECANCELED || r == -EAGAIN)
return;
else
assert(0 == "bad return value for C_Committed");
}
};
paxos->queue_pending_finisher(new C_Committed(this));// 注册commit完成的回调
paxos->trigger_propose();// 开始第一阶段:提交提案
}
bool Paxos::trigger_propose()
{
if (plugged) {
dout(10) << __func__ << " plugged, not proposing now" << dendl;
return false;
} else if (is_active()) {
dout(10) << __func__ << " active, proposing now" << dendl;
propose_pending();//开始触发决议
return true;
} else {
dout(10) << __func__ << " not active, will propose later" << dendl;
return false;
}
}
void Paxos::propose_pending()
{
assert(is_active());
assert(pending_proposal);
cancel_events();
bufferlist bl;
pending_proposal->encode(bl);
dout(10) << __func__ << " " << (last_committed + 1)
<< " " << bl.length() << " bytes" << dendl;
dout(30) << __func__ << " transaction dump:\n";
JSONFormatter f(true);
pending_proposal->dump(&f);
f.flush(*_dout);
*_dout << dendl;
pending_proposal.reset();
committing_finishers.swap(pending_finishers);
state = STATE_UPDATING;// 这里修改mon状态为STATE_UPDATING
begin(bl);// 开始决议
}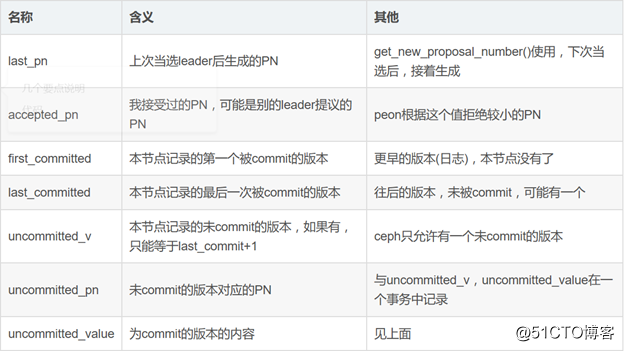
Leader当选后,会首先执行一次recoverying 过程,以确定PN。 在其为leader期间, 所有的提案proposal提交操作都共用一个PN。所以省略了大量的操作(选择较大PN),这也是 paxos能够减小网络开销的原因。(ceph中的paxos简化了paxos算法,因为ceph中leader是明确的,不需要每次paxos提案提交都要选举)
1. last_pn
//Last Proposal Number
version_t last_pn;
2.last_committed
/*
* Last committed value‘s version.
*
* On both the Leader and the Peons, this is the last value‘s version that
* was accepted by a given quorum and thus committed, that this instance
* knows about.
*/
version_t last_committed;
3.accepted_pn
/**
* The last Proposal Number we have accepted.
*
* On the Leader, it will be the Proposal Number picked by the Leader
* itself. On the Peon, however, it will be the proposal sent by the Leader
* and it will only be updated if its value is higher than the one
* already known by the Peon.
*/
已接受的pn值,该值是leader选出来的,并发送到peon端,对于peon端,只有接收到更大的pn才会更新,否则忽略。
version_t accepted_pn;
4. accepted_pn_from
/**
* The last_committed epoch of the leader at the time we accepted the last pn.
*
* This has NO SEMANTIC MEANING, and is there only for the debug output.
*/
version_t accepted_pn_from;
5.have_pending
/**
* If the implementation class has anything pending to be proposed to Paxos,
* then have_pending should be true; otherwise, false.
*/
bool have_pending;
6.proposing
/**
* If we are or have queued anything for proposal, this variable will be true
* until our proposal has been finished.
*/
bool proposing; 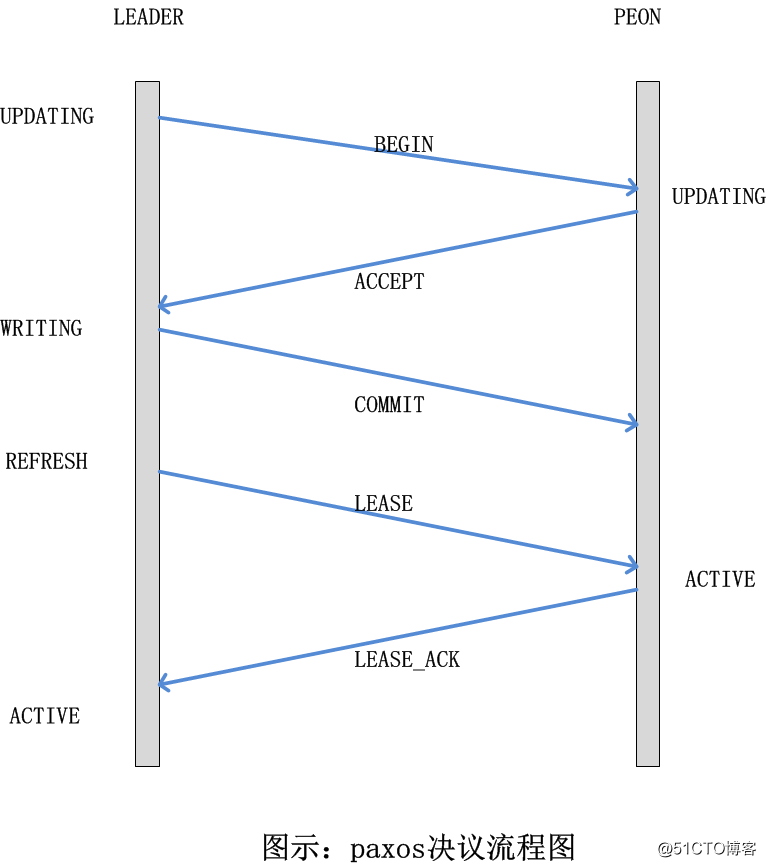
以下是详细的流程梳理:
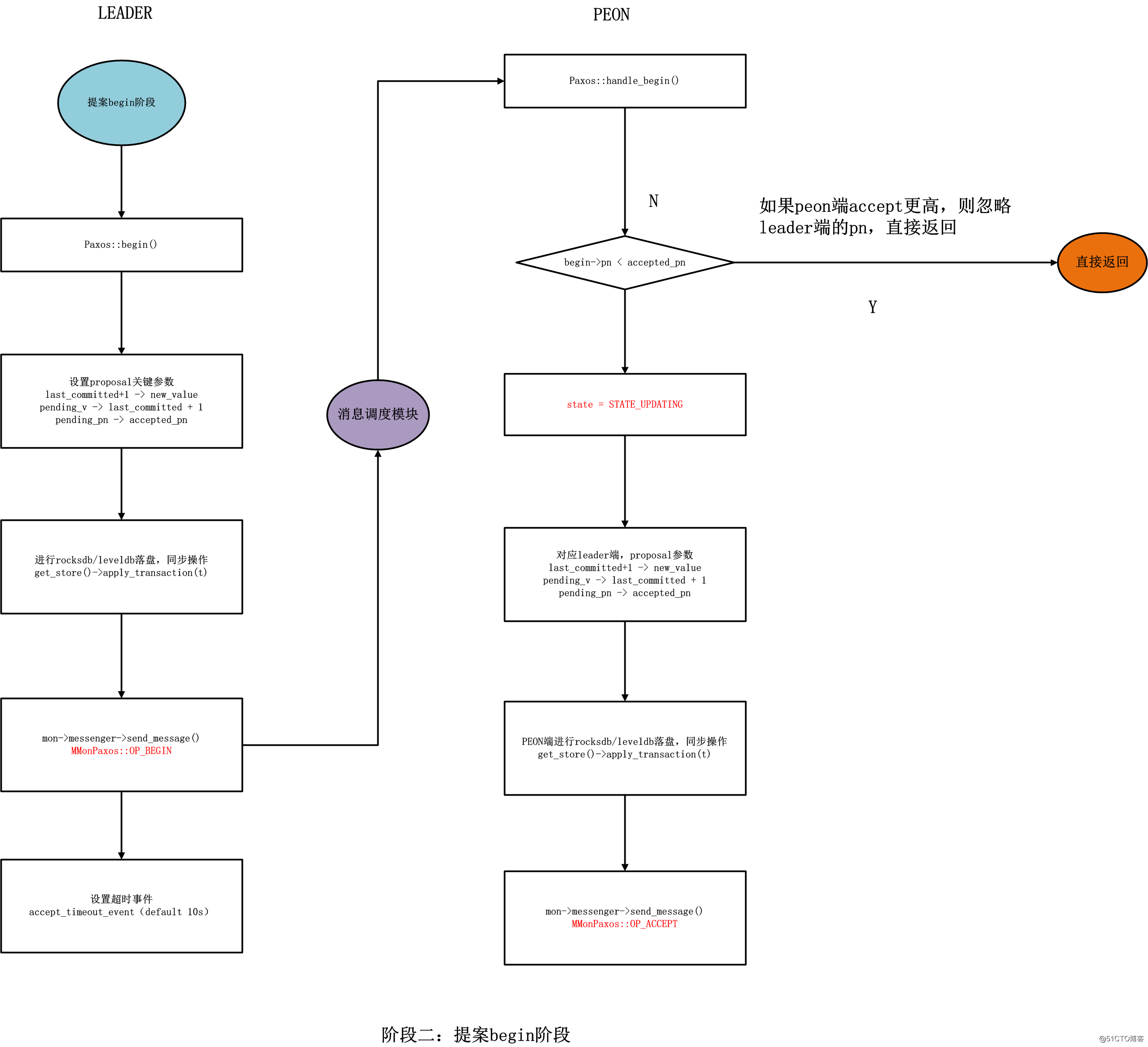
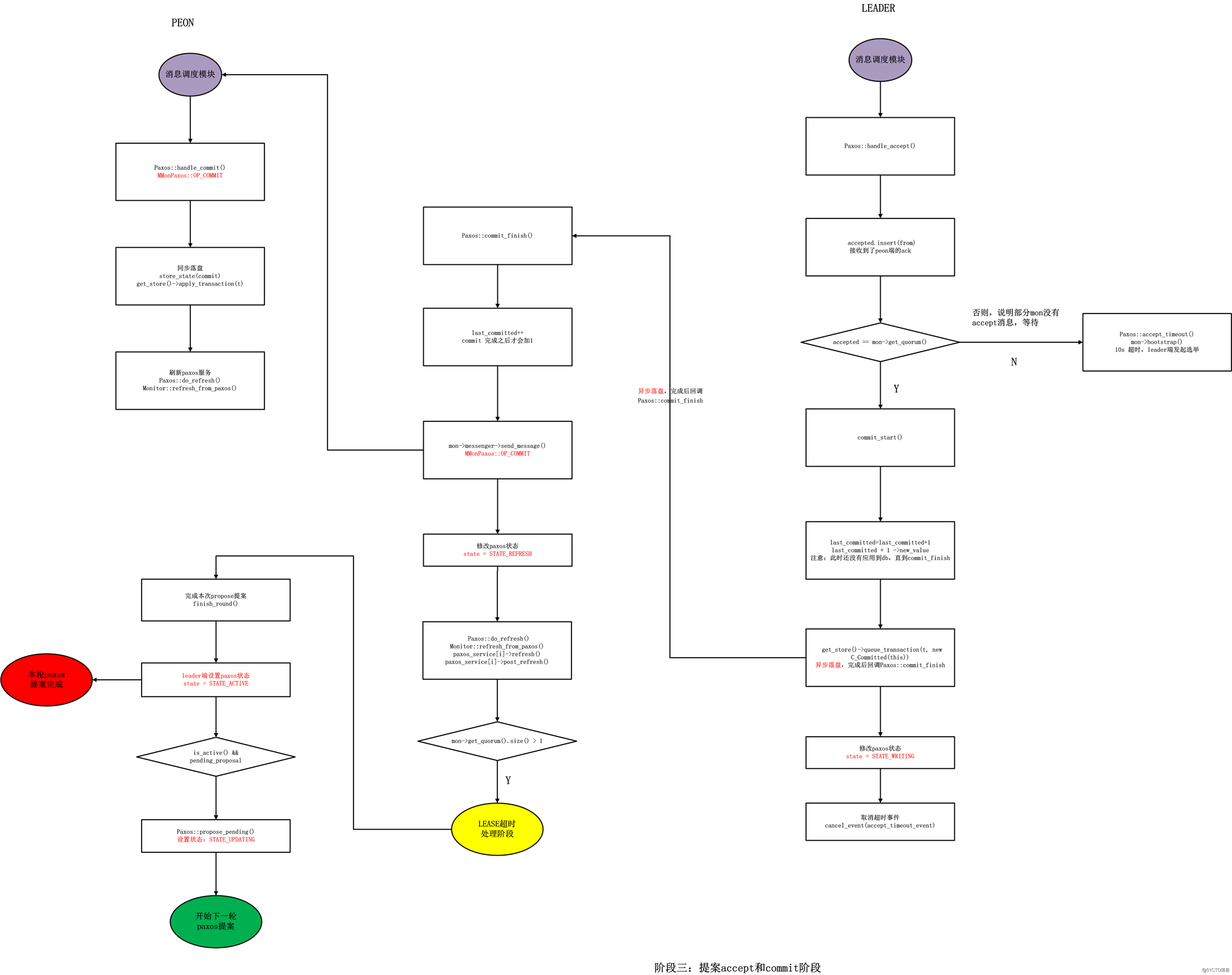
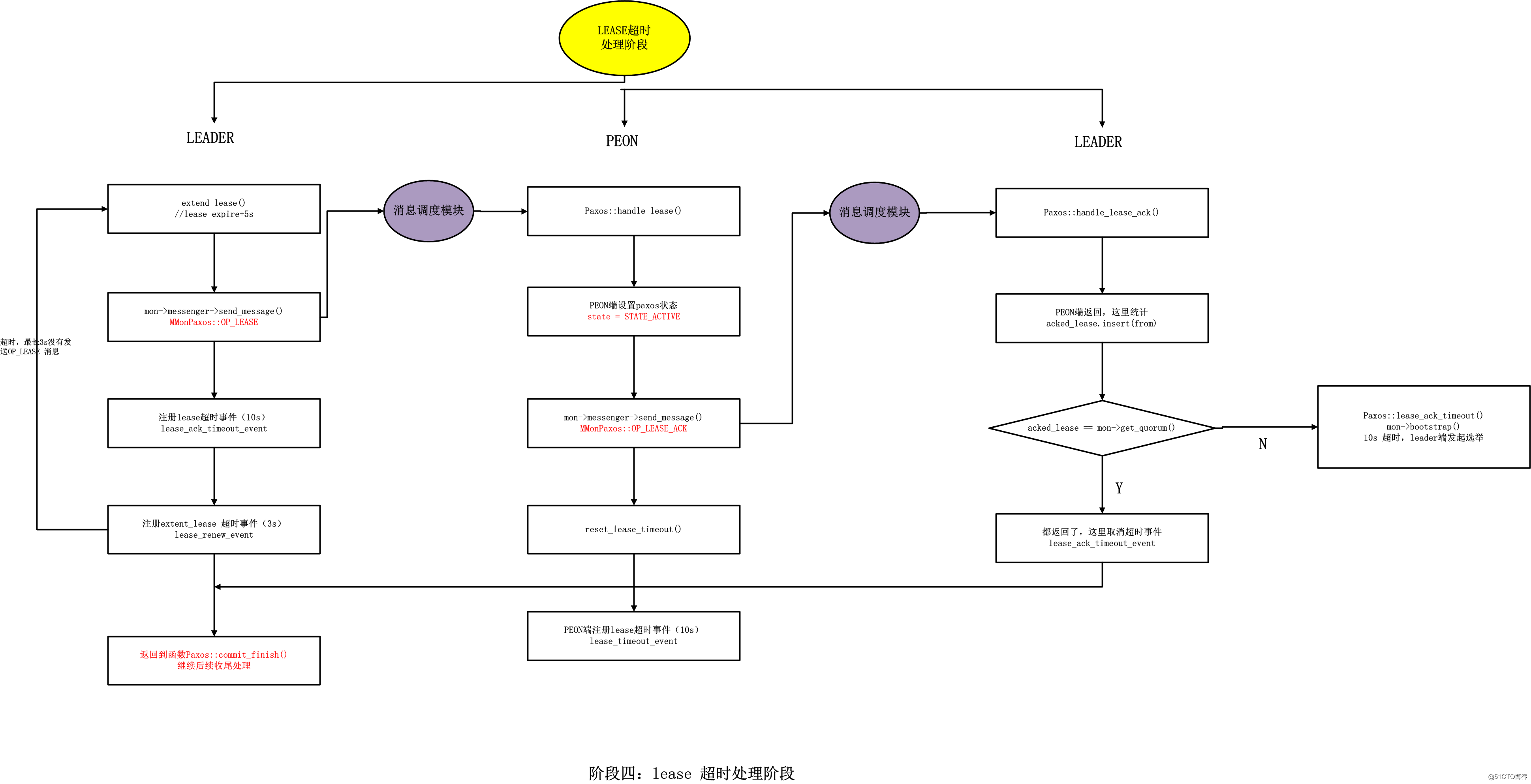
步骤1代码:
// leader
// PaxosService::propose_pending -> Paxos::trigger_propose -> Paxos::propose_pending(设置state = STATE_UPDATING) -> Paxos::begin
void Paxos::begin(bufferlist& v)
{
dout(10) << "begin for " << last_committed+1 << " "
<< v.length() << " bytes"
<< dendl;
assert(mon->is_leader());
assert(is_updating() || is_updating_previous());
// we must already have a majority for this to work.
assert(mon->get_quorum().size() == 1 ||
num_last > (unsigned)mon->monmap->size()/2);
// and no value, yet.
assert(new_value.length() == 0);
// accept it ourselves
accepted.clear();
accepted.insert(mon->rank);
new_value = v;
if (last_committed == 0) {
auto t(std::make_shared<MonitorDBStore::Transaction>());
// initial base case; set first_committed too
t->put(get_name(), "first_committed", 1);
decode_append_transaction(t, new_value);
bufferlist tx_bl;
t->encode(tx_bl);
new_value = tx_bl;
}
// store the proposed value in the store. IF it is accepted, we will then
// have to decode it into a transaction and apply it.
auto t(std::make_shared<MonitorDBStore::Transaction>());
t->put(get_name(), last_committed+1, new_value);//将要提交提案版本->对应的内容
// note which pn this pending value is for.
t->put(get_name(), "pending_v", last_committed + 1);// pending_v -> 将要提交提案版本
t->put(get_name(), "pending_pn", accepted_pn);// pending_pn -> 当前的pn(已接受的pn值,该值是leader选出来的,并发送到peon端,对于peon端,只有接收到更大的pn才会更新,否则忽略。)
dout(30) << __func__ << " transaction dump:\n";
JSONFormatter f(true);
t->dump(&f);
f.flush(*_dout);
auto debug_tx(std::make_shared<MonitorDBStore::Transaction>());
bufferlist::iterator new_value_it = new_value.begin();
debug_tx->decode(new_value_it);
debug_tx->dump(&f);
*_dout << "\nbl dump:\n";
f.flush(*_dout);
*_dout << dendl;
logger->inc(l_paxos_begin);
logger->inc(l_paxos_begin_keys, t->get_keys());
logger->inc(l_paxos_begin_bytes, t->get_bytes());
utime_t start = ceph_clock_now();
get_store()->apply_transaction(t);//这里会把last_committed+1、new_value、pending_v、pending_pn 进行rocksdb/leveldb落盘,同步操作
utime_t end = ceph_clock_now();
logger->tinc(l_paxos_begin_latency, end - start);
assert(g_conf->paxos_kill_at != 3);
//如果只有一个monitor节点(Quorum=1),则跳过begin、accept阶段直接commit
if (mon->get_quorum().size() == 1) {
// we‘re alone, take it easy
commit_start();
return;
}
// ask others to accept it too!
for (set<int>::const_iterator p = mon->get_quorum().begin();
p != mon->get_quorum().end();
++p) {
if (*p == mon->rank) continue;
dout(10) << " sending begin to mon." << *p << dendl;
MMonPaxos *begin = new MMonPaxos(mon->get_epoch(), MMonPaxos::OP_BEGIN,
ceph_clock_now());
begin->values[last_committed+1] = new_value;
begin->last_committed = last_committed;
begin->pn = accepted_pn;
mon->messenger->send_message(begin, mon->monmap->get_inst(*p));
}
// set timeout event
accept_timeout_event = mon->timer.add_event_after(
g_conf->mon_accept_timeout_factor * g_conf->mon_lease,//2*5=10s
new C_MonContext(mon, [this](int r) {
if (r == -ECANCELED)
return;
accept_timeout();
}));
}
打开paxos日志级别到30,可以在leader mon节点日志中查看到如下信息:
2020-08-18 17:15:34.137385 7f8c9d90f700 10 mon.ceph2@0(leader).paxos(paxos updating c 730411..731078) begin for 731079 1930 bytes
2020-08-18 17:15:34.137401 7f8c9d90f700 30 mon.ceph2@0(leader).paxos(paxos updating c 730411..731078) begin transaction dump:
{
"ops": [
{
"op_num": 0,
"type": "PUT",
"prefix": "paxos",
"key": "731079",
"length": 1930
},
{
"op_num": 1,
"type": "PUT",
"prefix": "paxos",
"key": "pending_v",
"length": 8
},
{
"op_num": 2,
"type": "PUT",
"prefix": "paxos",
"key": "pending_pn",
"length": 8
}
],
"num_keys": 3,
"num_bytes": 1986
}
bl dump:
{
"ops": [
{
"op_num": 0,
"type": "PUT",
"prefix": "mgrstat",
"key": "598838",
"length": 1770
},
{
"op_num": 1,
"type": "PUT",
"prefix": "mgrstat",
"key": "last_committed",
"length": 8
},
{
"op_num": 2,
"type": "PUT",
"prefix": "health",
"key": "mgrstat",
"length": 10
}
],
"num_keys": 3,
"num_bytes": 1835
}
步骤2代码:
// peon
void Paxos::handle_begin(MonOpRequestRef op)
{
op->mark_paxos_event("handle_begin");
MMonPaxos *begin = static_cast<MMonPaxos*>(op->get_req());
dout(10) << "handle_begin " << *begin << dendl;
// can we accept this?
if (begin->pn < accepted_pn) {//如果peon端accept更高,则忽略leader端的pn,直接返回
dout(10) << " we accepted a higher pn " << accepted_pn << ", ignoring" << dendl;
op->mark_paxos_event("have higher pn, ignore");
return;
}
assert(begin->pn == accepted_pn);
assert(begin->last_committed == last_committed);
assert(g_conf->paxos_kill_at != 4);
logger->inc(l_paxos_begin);
// set state.
state = STATE_UPDATING;// peon端设置mon状态为STATE_UPDATING
lease_expire = utime_t(); // cancel lease
// yes.
version_t v = last_committed+1;
dout(10) << "accepting value for " << v << " pn " << accepted_pn << dendl;
// store the accepted value onto our store. We will have to decode it and
// apply its transaction once we receive permission to commit.
auto t(std::make_shared<MonitorDBStore::Transaction>());
t->put(get_name(), v, begin->values[v]);// last_committed+1 -> begin->values[v]
// note which pn this pending value is for.
t->put(get_name(), "pending_v", v);
t->put(get_name(), "pending_pn", accepted_pn);
dout(30) << __func__ << " transaction dump:\n";
JSONFormatter f(true);
t->dump(&f);
f.flush(*_dout);
*_dout << dendl;
logger->inc(l_paxos_begin_bytes, t->get_bytes());
utime_t start = ceph_clock_now();
get_store()->apply_transaction(t); // 对应leader端,把last_committed+1、new_value、pending_v、pending_pn,写入rocksdb/leveldb
utime_t end = ceph_clock_now();
logger->tinc(l_paxos_begin_latency, end - start);
assert(g_conf->paxos_kill_at != 5);
// reply
MMonPaxos *accept = new MMonPaxos(mon->get_epoch(), MMonPaxos::OP_ACCEPT,
ceph_clock_now());
accept->pn = accepted_pn;
accept->last_committed = last_committed;
begin->get_connection()->send_message(accept);
}步骤3代码(不考虑超时情况,超时则走完主流程)
// leader
void Paxos::handle_accept(MonOpRequestRef op)
{
op->mark_paxos_event("handle_accept");
MMonPaxos *accept = static_cast<MMonPaxos*>(op->get_req());
dout(10) << "handle_accept " << *accept << dendl;
int from = accept->get_source().num();
if (accept->pn != accepted_pn) {
// we accepted a higher pn, from some other leader
dout(10) << " we accepted a higher pn " << accepted_pn << ", ignoring" << dendl;
op->mark_paxos_event("have higher pn, ignore");
return;
}
if (last_committed > 0 &&
accept->last_committed < last_committed-1) {
dout(10) << " this is from an old round, ignoring" << dendl;
op->mark_paxos_event("old round, ignore");
return;
}
assert(accept->last_committed == last_committed || // not committed
accept->last_committed == last_committed-1); // committed
assert(is_updating() || is_updating_previous());
assert(accepted.count(from) == 0);
accepted.insert(from);// 接收到了peon端的ack
dout(10) << " now " << accepted << " have accepted" << dendl;
assert(g_conf->paxos_kill_at != 6);
// only commit (and expose committed state) when we get *all* quorum
// members to accept. otherwise, they may still be sharing the now
// stale state.
// FIXME: we can improve this with an additional lease revocation message
// that doesn‘t block for the persist.
if (accepted == mon->get_quorum()) {
// yay, commit!
dout(10) << " got majority, committing, done with update" << dendl;
op->mark_paxos_event("commit_start");
commit_start();
}
}void Paxos::commit_start()
{
dout(10) << __func__ << " " << (last_committed+1) << dendl;
assert(g_conf->paxos_kill_at != 7);
auto t(std::make_shared<MonitorDBStore::Transaction>());
// commit locally
t->put(get_name(), "last_committed", last_committed + 1);//更新本地的last_committed=last_committed+1,注意此时还没有应用到db。直到commit_finish之后,本端last_committed才正式+1
// decode the value and apply its transaction to the store.
// this value can now be read from last_committed.
decode_append_transaction(t, new_value);// 此时更新last_committed + 1 ->new_value
dout(30) << __func__ << " transaction dump:\n";
JSONFormatter f(true);
t->dump(&f);
f.flush(*_dout);
*_dout << dendl;
logger->inc(l_paxos_commit);
logger->inc(l_paxos_commit_keys, t->get_keys());
logger->inc(l_paxos_commit_bytes, t->get_bytes());
commit_start_stamp = ceph_clock_now();
get_store()->queue_transaction(t, new C_Committed(this));// 异步落盘,异步操作,完成后回调Paxos::commit_finish
if (is_updating_previous())
state = STATE_WRITING_PREVIOUS;
else if (is_updating())
state = STATE_WRITING;// 更新paxos状态
else
ceph_abort();
++commits_started;
if (mon->get_quorum().size() > 1) {
// cancel timeout event
mon->timer.cancel_event(accept_timeout_event);
accept_timeout_event = 0;
}
}void Paxos::commit_finish()
{
dout(20) << __func__ << " " << (last_committed+1) << dendl;
utime_t end = ceph_clock_now();
logger->tinc(l_paxos_commit_latency, end - commit_start_stamp);
assert(g_conf->paxos_kill_at != 8);
// cancel lease - it was for the old value.
// (this would only happen if message layer lost the ‘begin‘, but
// leader still got a majority and committed with out us.)
lease_expire = utime_t(); // cancel lease
last_committed++;// commit 完成之后才会加1
last_commit_time = ceph_clock_now();
// refresh first_committed; this txn may have trimmed.
first_committed = get_store()->get(get_name(), "first_committed");
_sanity_check_store();
// tell everyone
for (set<int>::const_iterator p = mon->get_quorum().begin();
p != mon->get_quorum().end();
++p) {
if (*p == mon->rank) continue;
dout(10) << " sending commit to mon." << *p << dendl;
MMonPaxos *commit = new MMonPaxos(mon->get_epoch(), MMonPaxos::OP_COMMIT,
ceph_clock_now());
commit->values[last_committed] = new_value;
commit->pn = accepted_pn;
commit->last_committed = last_committed;
mon->messenger->send_message(commit, mon->monmap->get_inst(*p));
}
assert(g_conf->paxos_kill_at != 9);
// get ready for a new round.
new_value.clear();
// WRITING -> REFRESH
// among other things, this lets do_refresh() -> mon->bootstrap() know
// it doesn‘t need to flush the store queue
assert(is_writing() || is_writing_previous());
state = STATE_REFRESH;
assert(commits_started > 0);
--commits_started;
if (do_refresh()) {
commit_proposal();
if (mon->get_quorum().size() > 1) {
extend_lease();// 开始lease验证
}
finish_contexts(g_ceph_context, waiting_for_commit);
assert(g_conf->paxos_kill_at != 10);
finish_round();
}
}
步骤4代码:
//peon
void Paxos::handle_commit(MonOpRequestRef op)
{
op->mark_paxos_event("handle_commit");
MMonPaxos *commit = static_cast<MMonPaxos*>(op->get_req());
dout(10) << "handle_commit on " << commit->last_committed << dendl;
logger->inc(l_paxos_commit);
if (!mon->is_peon()) {
dout(10) << "not a peon, dropping" << dendl;
ceph_abort();
return;
}
op->mark_paxos_event("store_state");
store_state(commit);// 落盘,同步操作
if (do_refresh()) {
finish_contexts(g_ceph_context, waiting_for_commit);
}
}步骤5代码:
bool Paxos::store_state(MMonPaxos *m)
{
auto t(std::make_shared<MonitorDBStore::Transaction>());
map<version_t,bufferlist>::iterator start = m->values.begin();
bool changed = false;
// build map of values to store
// we want to write the range [last_committed, m->last_committed] only.
if (start != m->values.end() &&
start->first > last_committed + 1) {
// ignore everything if values start in the future.
dout(10) << "store_state ignoring all values, they start at " << start->first
<< " > last_committed+1" << dendl;
return false;
}
// push forward the start position on the message‘s values iterator, up until
// we run out of positions or we find a position matching ‘last_committed‘.
while (start != m->values.end() && start->first <= last_committed) {
++start;
}
// make sure we get the right interval of values to apply by pushing forward
// the ‘end‘ iterator until it matches the message‘s ‘last_committed‘.
map<version_t,bufferlist>::iterator end = start;
while (end != m->values.end() && end->first <= m->last_committed) {
last_committed = end->first;
++end;
}
if (start == end) {
dout(10) << "store_state nothing to commit" << dendl;
} else {
dout(10) << "store_state [" << start->first << ".."
<< last_committed << "]" << dendl;
t->put(get_name(), "last_committed", last_committed);
// we should apply the state here -- decode every single bufferlist in the
// map and append the transactions to ‘t‘.
map<version_t,bufferlist>::iterator it;
for (it = start; it != end; ++it) {
// write the bufferlist as the version‘s value
t->put(get_name(), it->first, it->second);
// decode the bufferlist and append it to the transaction we will shortly
// apply.
decode_append_transaction(t, it->second);
}
// discard obsolete uncommitted value?
if (uncommitted_v && uncommitted_v <= last_committed) {
dout(10) << " forgetting obsolete uncommitted value " << uncommitted_v
<< " pn " << uncommitted_pn << dendl;
uncommitted_v = 0;
uncommitted_pn = 0;
uncommitted_value.clear();
}
}
if (!t->empty()) {
dout(30) << __func__ << " transaction dump:\n";
JSONFormatter f(true);
t->dump(&f);
f.flush(*_dout);
*_dout << dendl;
logger->inc(l_paxos_store_state);
logger->inc(l_paxos_store_state_bytes, t->get_bytes());
logger->inc(l_paxos_store_state_keys, t->get_keys());
utime_t start = ceph_clock_now();
get_store()->apply_transaction(t);// 同步落盘
utime_t end = ceph_clock_now();
logger->tinc(l_paxos_store_state_latency, end - start);
// refresh first_committed; this txn may have trimmed.
first_committed = get_store()->get(get_name(), "first_committed");
_sanity_check_store();
changed = true;
}
return changed;
}步骤6代码:
Paxos::extend_lease()代码流程见:
https://blog.51cto.com/wendashuai/2517286
在Leader选举成功后,Leader和Peon都进入Recovery阶段。该阶段的目的是为了保证新Quorum的所有成员状态一致,这些状态包括:最后一个批准(Committed)的提案,最后一个没批准的提案,最后一个接受(Acceppted)的提案。每个节点的这些状态都持久化到磁盘。对旧Quorum的所有成员来说,最后一个通过的提案应该都是相同的,但对不属于旧Quorum的成员来说,它的最后一个通过的提案是落后的。
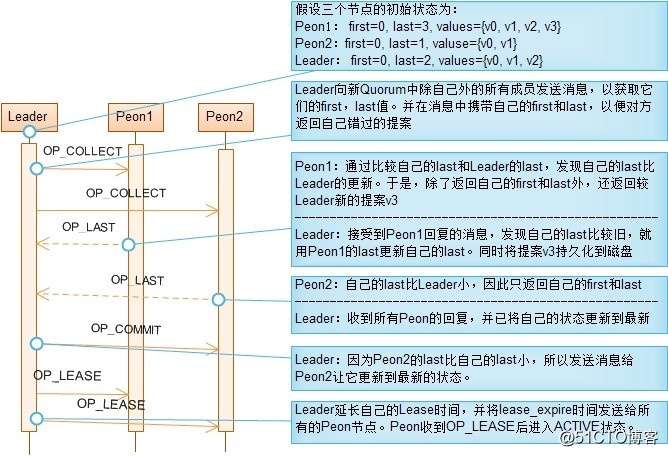
同步已批准提案的方法:
1.Leader先向新Quorum的所有Peon节点发送OP_COLLECT消息,并在消息中携带Leader自己的第1个和最后1个批准的提案的值的版本号。
2.Peon收到OP_COLLECT消息后,将自己的第1个和最后1个批准的提案的值的版本号返回给Leader,并且如果Peon的最后1个批准的版本号大于Leader最后一个批准的版本号时,将所有在大于Leader最后一个版本号的提案值发送给Leader。
3.Leader将根据这些信息填补自己错过的提案。这样,当Leader接收到所有Peon对OP_COLLECT消息的回应后,也就将自己更新到了最新的状态。这时Leader又反过来将最新状态同步到其它节点。
4.为获取新Quorum所有成员中的最大提案号,Leader在发送OP_COLLECT消息时,提出它知道的最大的提案号,并将该提案号附加在OP_COLLECT消息中。如果Peon已接受的最大提案号大于Leader提出的提案号,则拒绝接受Leader提出的提案号并将自己已接受的最大提案号通过OP_LAST消息发送给Leader。
5.Leader收到OP_LAST消息后,发现自己的提案号不是最大时,就在Peon接受的最大提案号的基础上提出更大的提案号,重新进入Recovery阶段。这样,最终可以获取到最大的提案号。
总而言之,Recovery阶段的目的是让新Quorum中所有节点处于一致状态。实现这一目的的方法分成两步:首先,在Leader节点收集所有节点的状态,通过比较得到最新状态;然后,Leader将最新状态同步给其它节点。有两个比较重要的状态,最后一次批准的提案和已接受的最大提案号。
注意 区分提案号(proposal number)、提案值(value)、提案值的版本号(value version)这三个概念。提案号由Leader提出,为避免不同Leader提出的提案号不冲突,同个Leader提出的提案号是不连续的。提案的值的版本号是连续的。
选举完成后,leader端和peon端都会进入STATE_RECOVERING阶段。
void Paxos::leader_init()
{
cancel_events();
new_value.clear();
// discard pending transaction
pending_proposal.reset();
finish_contexts(g_ceph_context, pending_finishers, -EAGAIN);
finish_contexts(g_ceph_context, committing_finishers, -EAGAIN);
logger->inc(l_paxos_start_leader);
if (mon->get_quorum().size() == 1) {
state = STATE_ACTIVE;
return;
}
state = STATE_RECOVERING;// 选举完成后,leader的paxos状态转换为STATE_RECOVERING。该阶段的目的是为了保证新Quorum的所有成员状态一致。
lease_expire = utime_t();
dout(10) << "leader_init -- starting paxos recovery" << dendl;
collect(0);
}
void Paxos::peon_init()
{
cancel_events();
new_value.clear();
state = STATE_RECOVERING;
lease_expire = utime_t();
dout(10) << "peon_init -- i am a peon" << dendl;
// start a timer, in case the leader never manages to issue a lease
reset_lease_timeout();
// discard pending transaction
pending_proposal.reset();
// no chance to write now!
finish_contexts(g_ceph_context, waiting_for_writeable, -EAGAIN);
finish_contexts(g_ceph_context, waiting_for_commit, -EAGAIN);
finish_contexts(g_ceph_context, pending_finishers, -EAGAIN);
finish_contexts(g_ceph_context, committing_finishers, -EAGAIN);
logger->inc(l_paxos_start_peon);
}// PHASE 1
// leader Paxos::leader_init() leader选举成功后调用
void Paxos::collect(version_t oldpn)
{
// we‘re recoverying, it seems!
state = STATE_RECOVERING;
assert(mon->is_leader());
// reset the number of lasts received
uncommitted_v = 0;
uncommitted_pn = 0;
uncommitted_value.clear();
peer_first_committed.clear();
peer_last_committed.clear();
// look for uncommitted value
if (get_store()->exists(get_name(), last_committed+1)) {
version_t v = get_store()->get(get_name(), "pending_v");
version_t pn = get_store()->get(get_name(), "pending_pn");
if (v && pn && v == last_committed + 1) {
uncommitted_pn = pn;
} else {
dout(10) << "WARNING: no pending_pn on disk, using previous accepted_pn " << accepted_pn
<< " and crossing our fingers" << dendl;
uncommitted_pn = accepted_pn;
}
uncommitted_v = last_committed+1;
get_store()->get(get_name(), last_committed+1, uncommitted_value);
assert(uncommitted_value.length());
dout(10) << "learned uncommitted " << (last_committed+1)
<< " pn " << uncommitted_pn
<< " (" << uncommitted_value.length() << " bytes) from myself"
<< dendl;
logger->inc(l_paxos_collect_uncommitted);
}
// pick new pn; mon选举成功recovering过程中,leader id为0时,pn每次+100
accepted_pn = get_new_proposal_number(MAX(accepted_pn, oldpn));
accepted_pn_from = last_committed;
num_last = 1;
dout(10) << "collect with pn " << accepted_pn << dendl;
// send collect
for (set<int>::const_iterator p = mon->get_quorum().begin();
p != mon->get_quorum().end();
++p) {
if (*p == mon->rank) continue;
MMonPaxos *collect = new MMonPaxos(mon->get_epoch(), MMonPaxos::OP_COLLECT,
ceph_clock_now());
collect->last_committed = last_committed;
collect->first_committed = first_committed;
collect->pn = accepted_pn;
mon->messenger->send_message(collect, mon->monmap->get_inst(*p));
}
// set timeout event
collect_timeout_event = mon->timer.add_event_after(
g_conf->mon_accept_timeout_factor *
g_conf->mon_lease,//2*5s=10s
new C_MonContext(mon, [this](int r) {
if (r == -ECANCELED)
return;
collect_timeout();
}));
}
// peon
void Paxos::handle_collect(MonOpRequestRef op)
{
op->mark_paxos_event("handle_collect");
MMonPaxos *collect = static_cast<MMonPaxos*>(op->get_req());
dout(10) << "handle_collect " << *collect << dendl;
assert(mon->is_peon()); // mon epoch filter should catch strays
// we‘re recoverying, it seems!
state = STATE_RECOVERING;
//update the peon recovery timeout
reset_lease_timeout();
if (collect->first_committed > last_committed+1) {
dout(2) << __func__
<< " leader‘s lowest version is too high for our last committed"
<< " (theirs: " << collect->first_committed
<< "; ours: " << last_committed << ") -- bootstrap!" << dendl;
op->mark_paxos_event("need to bootstrap");
mon->bootstrap();
return;
}
// reply
MMonPaxos *last = new MMonPaxos(mon->get_epoch(), MMonPaxos::OP_LAST,
ceph_clock_now());
last->last_committed = last_committed;
last->first_committed = first_committed;
version_t previous_pn = accepted_pn;
// can we accept this pn?
if (collect->pn > accepted_pn) {
// ok, accept it
accepted_pn = collect->pn;
accepted_pn_from = collect->pn_from;
dout(10) << "accepting pn " << accepted_pn << " from "
<< accepted_pn_from << dendl;
auto t(std::make_shared<MonitorDBStore::Transaction>());
t->put(get_name(), "accepted_pn", accepted_pn);
dout(30) << __func__ << " transaction dump:\n";
JSONFormatter f(true);
t->dump(&f);
f.flush(*_dout);
*_dout << dendl;
logger->inc(l_paxos_collect);
logger->inc(l_paxos_collect_keys, t->get_keys());
logger->inc(l_paxos_collect_bytes, t->get_bytes());
utime_t start = ceph_clock_now();
get_store()->apply_transaction(t);//本地落盘
utime_t end = ceph_clock_now();
logger->tinc(l_paxos_collect_latency, end - start);
} else {
// don‘t accept!
dout(10) << "NOT accepting pn " << collect->pn << " from " << collect->pn_from
<< ", we already accepted " << accepted_pn
<< " from " << accepted_pn_from << dendl;
}
last->pn = accepted_pn;
last->pn_from = accepted_pn_from;
// share whatever committed values we have
if (collect->last_committed < last_committed)
share_state(last, collect->first_committed, collect->last_committed);
// do we have an accepted but uncommitted value?
// (it‘ll be at last_committed+1)
bufferlist bl;
if (collect->last_committed <= last_committed &&
get_store()->exists(get_name(), last_committed+1)) {
get_store()->get(get_name(), last_committed+1, bl);
assert(bl.length() > 0);
dout(10) << " sharing our accepted but uncommitted value for "
<< last_committed+1 << " (" << bl.length() << " bytes)" << dendl;
last->values[last_committed+1] = bl;
version_t v = get_store()->get(get_name(), "pending_v");
version_t pn = get_store()->get(get_name(), "pending_pn");
if (v && pn && v == last_committed + 1) {
last->uncommitted_pn = pn;
} else {
// previously we didn‘t record which pn a value was accepted
// under! use the pn value we just had... :(
dout(10) << "WARNING: no pending_pn on disk, using previous accepted_pn " << previous_pn
<< " and crossing our fingers" << dendl;
last->uncommitted_pn = previous_pn;
}
logger->inc(l_paxos_collect_uncommitted);
}
// send reply
collect->get_connection()->send_message(last);
}// leader
void Paxos::handle_last(MonOpRequestRef op)
{
op->mark_paxos_event("handle_last");
MMonPaxos *last = static_cast<MMonPaxos*>(op->get_req());
bool need_refresh = false;
int from = last->get_source().num();
dout(10) << "handle_last " << *last << dendl;
if (!mon->is_leader()) {
dout(10) << "not leader, dropping" << dendl;
return;
}
// note peer‘s first_ and last_committed, in case we learn a new
// commit and need to push it to them.
peer_first_committed[from] = last->first_committed;
peer_last_committed[from] = last->last_committed;
if (last->first_committed > last_committed + 1) {
dout(5) << __func__
<< " mon." << from
<< " lowest version is too high for our last committed"
<< " (theirs: " << last->first_committed
<< "; ours: " << last_committed << ") -- bootstrap!" << dendl;
op->mark_paxos_event("need to bootstrap");
mon->bootstrap();
return;
}
assert(g_conf->paxos_kill_at != 1);
// store any committed values if any are specified in the message
need_refresh = store_state(last);
assert(g_conf->paxos_kill_at != 2);
// is everyone contiguous and up to date?
for (map<int,version_t>::iterator p = peer_last_committed.begin();
p != peer_last_committed.end();
++p) {
if (p->second + 1 < first_committed && first_committed > 1) {
dout(5) << __func__
<< " peon " << p->first
<< " last_committed (" << p->second
<< ") is too low for our first_committed (" << first_committed
<< ") -- bootstrap!" << dendl;
op->mark_paxos_event("need to bootstrap");
mon->bootstrap();
return;
}
if (p->second < last_committed) {
// share committed values
dout(10) << " sending commit to mon." << p->first << dendl;
MMonPaxos *commit = new MMonPaxos(mon->get_epoch(),
MMonPaxos::OP_COMMIT,
ceph_clock_now());
share_state(commit, peer_first_committed[p->first], p->second);
mon->messenger->send_message(commit, mon->monmap->get_inst(p->first));
}
}
// do they accept your pn?
if (last->pn > accepted_pn) {
// no, try again.
dout(10) << " they had a higher pn than us, picking a new one." << dendl;
// cancel timeout event
mon->timer.cancel_event(collect_timeout_event);
collect_timeout_event = 0;
collect(last->pn);//同步已批准提案
} else if (last->pn == accepted_pn) {
// yes, they accepted our pn. great.
num_last++;
dout(10) << " they accepted our pn, we now have "
<< num_last << " peons" << dendl;
// did this person send back an accepted but uncommitted value?
if (last->uncommitted_pn) {
if (last->uncommitted_pn >= uncommitted_pn &&
last->last_committed >= last_committed &&
last->last_committed + 1 >= uncommitted_v) {
uncommitted_v = last->last_committed+1;
uncommitted_pn = last->uncommitted_pn;
uncommitted_value = last->values[uncommitted_v];
dout(10) << "we learned an uncommitted value for " << uncommitted_v
<< " pn " << uncommitted_pn
<< " " << uncommitted_value.length() << " bytes"
<< dendl;
} else {
dout(10) << "ignoring uncommitted value for " << (last->last_committed+1)
<< " pn " << last->uncommitted_pn
<< " " << last->values[last->last_committed+1].length() << " bytes"
<< dendl;
}
}
// is that everyone?
if (num_last == mon->get_quorum().size()) {
// cancel timeout event
mon->timer.cancel_event(collect_timeout_event);
collect_timeout_event = 0;
peer_first_committed.clear();
peer_last_committed.clear();
// almost...
// did we learn an old value?
if (uncommitted_v == last_committed+1 &&
uncommitted_value.length()) {
dout(10) << "that‘s everyone. begin on old learned value" << dendl;
state = STATE_UPDATING_PREVIOUS;
begin(uncommitted_value);
} else {
// active!
dout(10) << "that‘s everyone. active!" << dendl;
extend_lease();
need_refresh = false;
if (do_refresh()) {
finish_round();
}
}
}
} else {
// no, this is an old message, discard
dout(10) << "old pn, ignoring" << dendl;
}
if (need_refresh)
(void)do_refresh();
}
//peon
void Paxos::handle_commit(MonOpRequestRef op)
{
op->mark_paxos_event("handle_commit");
MMonPaxos *commit = static_cast<MMonPaxos*>(op->get_req());
dout(10) << "handle_commit on " << commit->last_committed << dendl;
logger->inc(l_paxos_commit);
if (!mon->is_peon()) {
dout(10) << "not a peon, dropping" << dendl;
ceph_abort();
return;
}
op->mark_paxos_event("store_state");
store_state(commit);// 落盘,同步操作
if (do_refresh()) {
finish_contexts(g_ceph_context, waiting_for_commit);
}
}各自决议或者说各自提交提案,但是决议流程完全相同,对Paxos服务来说没有差别(只是提案携带的value等参数不同)。
这就表示他们相互之间是串行的(相对dispatch线程和rocksdb/leveldb落盘操作来说是串行,相对Paxos服务并不完全是,参考上面提到的timer线程和finisher线程),可能会互相影响。
根据上面的问题2代码分析,可以看出一次决议有4次落盘(从角色看leader、peon各两次,具体到决议过程是begin阶段leader、peon各一次,commit阶段leader、peon各一次),其中leader在收到peon的accept回复之后的commit阶段的落盘是异步的,其他都是同步。
但是不管同步还是异步落盘,对提案提交者来说,总是要等待决议通过之后才能收到回复,才能继续执行后续流程。
同步落盘:
int apply_transaction(MonitorDBStore::TransactionRef t) {
KeyValueDB::Transaction dbt = db->get_transaction();
if (do_dump) {
if (!g_conf->mon_debug_dump_json) {
bufferlist bl;
t->encode(bl);
bl.write_fd(dump_fd_binary);
} else {
t->dump(&dump_fmt, true);
dump_fmt.flush(dump_fd_json);
dump_fd_json.flush();
}
}
list<pair<string, pair<string,string> > > compact;
for (list<Op>::const_iterator it = t->ops.begin();
it != t->ops.end();
++it) {
const Op& op = *it;
switch (op.type) {
case Transaction::OP_PUT:
dbt->set(op.prefix, op.key, op.bl);
break;
case Transaction::OP_ERASE:
dbt->rmkey(op.prefix, op.key);
break;
case Transaction::OP_COMPACT:
compact.push_back(make_pair(op.prefix, make_pair(op.key, op.endkey)));
break;
default:
derr << __func__ << " unknown op type " << op.type << dendl;
ceph_abort();
break;
}
}
int r = db->submit_transaction_sync(dbt);//提交事务到store层
if (r >= 0) {
while (!compact.empty()) {
if (compact.front().second.first == string() &&
compact.front().second.second == string())
db->compact_prefix_async(compact.front().first);
else
db->compact_range_async(compact.front().first, compact.front().second.first, compact.front().second.second);
compact.pop_front();
}
} else {
assert(0 == "failed to write to db");
}
return r;
}int RocksDBStore::submit_transaction_sync(KeyValueDB::Transaction t)
{
utime_t start = ceph_clock_now();
// enable rocksdb breakdown
// considering performance overhead, default is disabled
if (g_conf->rocksdb_perf) {
rocksdb::SetPerfLevel(rocksdb::PerfLevel::kEnableTimeExceptForMutex);
rocksdb::perf_context.Reset();
}
RocksDBTransactionImpl * _t =
static_cast<RocksDBTransactionImpl *>(t.get());
rocksdb::WriteOptions woptions;
woptions.sync = true;
woptions.disableWAL = disableWAL;
lgeneric_subdout(cct, rocksdb, 30) << __func__;
RocksWBHandler bat_txc;
_t->bat.Iterate(&bat_txc);
*_dout << " Rocksdb transaction: " << bat_txc.seen << dendl;
rocksdb::Status s = db->Write(woptions, &_t->bat);//写入rocksdb数据库接口
if (!s.ok()) {
RocksWBHandler rocks_txc;
_t->bat.Iterate(&rocks_txc);
derr << __func__ << " error: " << s.ToString() << " code = " << s.code()
<< " Rocksdb transaction: " << rocks_txc.seen << dendl;
}
utime_t lat = ceph_clock_now() - start;
if (g_conf->rocksdb_perf) {
utime_t write_memtable_time;
utime_t write_delay_time;
utime_t write_wal_time;
utime_t write_pre_and_post_process_time;
write_wal_time.set_from_double(
static_cast<double>(rocksdb::perf_context.write_wal_time)/1000000000);
write_memtable_time.set_from_double(
static_cast<double>(rocksdb::perf_context.write_memtable_time)/1000000000);
write_delay_time.set_from_double(
static_cast<double>(rocksdb::perf_context.write_delay_time)/1000000000);
write_pre_and_post_process_time.set_from_double(
static_cast<double>(rocksdb::perf_context.write_pre_and_post_process_time)/1000000000);
logger->tinc(l_rocksdb_write_memtable_time, write_memtable_time);
logger->tinc(l_rocksdb_write_delay_time, write_delay_time);
logger->tinc(l_rocksdb_write_wal_time, write_wal_time);
logger->tinc(l_rocksdb_write_pre_and_post_process_time, write_pre_and_post_process_time);
}
logger->inc(l_rocksdb_txns_sync);
logger->tinc(l_rocksdb_submit_sync_latency, lat);
return s.ok() ? 0 : -1;
}异步落盘:
void queue_transaction(MonitorDBStore::TransactionRef t,
Context *oncommit) {
io_work.queue(new C_DoTransaction(this, t, oncommit));// 入队后由finisher线程处理
}
struct C_DoTransaction : public Context {
MonitorDBStore *store;
MonitorDBStore::TransactionRef t;
Context *oncommit;
C_DoTransaction(MonitorDBStore *s, MonitorDBStore::TransactionRef t,
Context *f)
: store(s), t(t), oncommit(f)
{}
void finish(int r) override {
/* The store serializes writes. Each transaction is handled
* sequentially by the io_work Finisher. If a transaction takes longer
* to apply its state to permanent storage, then no other transaction
* will be handled meanwhile.
*
* We will now randomly inject random delays. We can safely sleep prior
* to applying the transaction as it won‘t break the model.
*/
double delay_prob = g_conf->mon_inject_transaction_delay_probability;
if (delay_prob && (rand() % 10000 < delay_prob * 10000.0)) {
utime_t delay;
double delay_max = g_conf->mon_inject_transaction_delay_max;
delay.set_from_double(delay_max * (double)(rand() % 10000) / 10000.0);
lsubdout(g_ceph_context, mon, 1)
<< "apply_transaction will be delayed for " << delay
<< " seconds" << dendl;
delay.sleep();
}
int ret = store->apply_transaction(t);//同步落盘
oncommit->complete(ret);
}
}; pgmap、logm及少量的auth,其中pgmap是在osd在上报pg stats,即使pg stats没有变化,也要5-600s(osd_mon_report_interval_min、osd_mon_report_interval_max)上报一次:
OSD::tick -> OSD::do_mon_report -> OSD::send_pg_stats
问题6:rocksdb/leveldb定期清理怎么做?
// mon_tick_interval = 5s
void Monitor::tick()
{
for (vector<PaxosService*>::iterator p = paxos_service.begin(); p != paxos_service.end(); ++p) {
(*p)->tick();
(*p)->maybe_trim();
}
}之后的流程跟正常的决议流程一致,只是leveldb操作变为erase(正常都是put)。
[root@ceph3 ~]# ceph daemon mon.ceph3 perf dump参考link:
https://blog.csdn.net/skdkjzz/article/details/41979521
标签:lstat ppi layer 梳理 写入 tostring which rop miss
原文地址:https://blog.51cto.com/wendashuai/2523066