标签:分库分表 分表 boot 解决 选择 根据 为什么 读写 增加

session说到 session,我相信每个程序员都不陌生,或多或少在项目中使用过。session 这个词,其实是一个抽象的概念,它不像 Cookie 那样有着明确的定义。当大多数程序员谈论 session 的时候,可能指的是服务端存储数据的 session 对象,例如,用户登录成功之后把用户信息存储在 session 中,类似于这样的程序。
Session["UserName"] = new User();
public class User{
public int UserId {get ;set ;}
public string UserName {get ;set;}
} 而在计算机中,尤其是网络应用中,session 被定义为“会话”,可以把它看做客户端和服务端的一条通道连接,同一个用户的请求使用同一个 session 会话。在大多数应用中,主要用于用户的识别,通俗来讲,服务端可以通过 session 来记录每一个用户的状态信息。那我们就以最常用的服务端 session 对象来啰嗦几句
单机 session
session 是存储在服务端的,这是一个很重要的概念。这意味着它需要占用服务器的内存,并且它需要一种释放的机制来保证服务器内存不会被撑爆(例如 LRU)。
在项目初期,为了快速上线,服务器的部署很多情况下只有一台服务器,记录用户的登录状态普遍使用 session 机制。请不要说这样做不合理,至少在项目初期这种做法是最简单而且最快速的方案。随着项目的不断迭代升级,用户量的不断增加,你会发现单机系统成为了项目的最大性能瓶颈,这个时候多数架构师会选择水平扩展方案。
其实说到底,系统性能的提升都围绕着一个“分”字,无论是数据库的分库分表,还是现在兴起的微服务,始终在围绕着一个领域进行切分
当单机的 session 机制进行水平扩展就面临着必须要要解决的问题:session 的亲和性(粘性)要怎么样去解决?
一个单机系统扩展为一个分布式系统,就会面临着分布式 CAP 理论中 AP 和 CP 的选择
谈到分布式 session 的一致性问题,其实主要是要解决用户 session 的亲和性,同一个用户的请求怎么样才能保证到达正确存储 session 信息的服务器呢?
最初的方案是采用 session 复制方案,整体的流程非常简单:假设现在有三台服务器,当一个 session 在其中一台服务器上被创建,则同时把这个 session 复制到其他两台服务器上。这样当用户的请求无论到达哪台服务器,都会有相应的 session 数据。
这种方案的优势在于服务器可以任意水平扩展,每个服务器都保留着所有的 session 信息,当加入一台服务器只需要把所有的 session 信息复制过去即可。但是劣势更加明显
session 复制的方案现在已经很少有人使用了
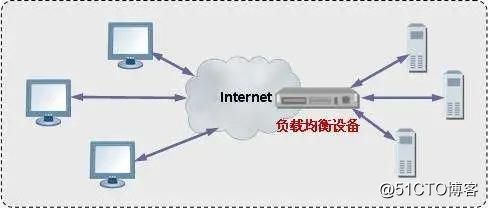
当一台服务器扩展为多台服务器,目前最常用的方案是在流量的入口添加负载均衡器,大体的部署图是这样的
image
如果负载均衡器能够利用某种手段来实现 session 的粘性就能实现分布式 session。目前主流的 nginx 可以根据“hash_ip”算法将同一个 IP 的请求固定到某台服务器,这样来自于同一个 ip 的 session 请求总是请求到同样的服务器。
这种方式比 session 同步方式要好很多,每台服务器只存储对应的 session 数据,这大大节省了内存资源,而且服务器之间没有数据同步过程。当有新服务器加入的时候,只需要修改负载均衡器的配置即可,这样很方便就支持了服务器水平扩展。但是,同时也面临着一些不足
服务器重启意味着对应的 session 信息丢失,这在一些重要的业务场景中是不允许的
服务器的水平扩展需要修改负载均衡器的配置,修改之后可能会导致之前的 session 重新分布,这样会导致一部分用户路由不到正确的 session
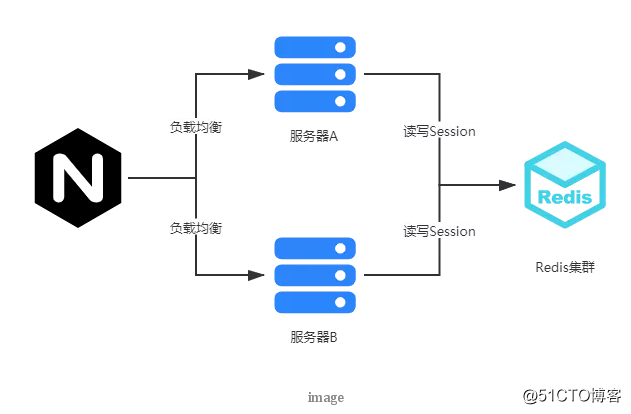
现在应用更广泛的分布式 session 技术是把 session 数据彻底从业务服务器中剥离,单独存储在其他外部设备中,而这些外部设备可以采用主备或者主从,甚至集群的模式来达到高可用。比如现在最常用的方案是把 session 数据存储在 redis 中,虽然从 redis 读写 session 数据需要花费一定的网络耗时,但是对于一般的应用来说在可以接受范围之内。
这种方案好处是整体架构更加清晰,也更加灵活,应用的服务器整体扩展能力再也不用考虑 session 的影响,而 session 的问题被转移到外部设备,通常可以利用内存性 NOSql 来解决性能问题,而这些外部设备一般都会有对应的分布式集群方案,例如 redis,可以利用主从或者哨兵模式甚至集群来提供更大规模的数据支撑能力。
Actor 模型解决这种用户粘性问题会更加优雅,它天生就自带了对象识别功能,简单来说,同一个 key 的请求,总能到达正确的 actor 实例,这不是我们想要的结果吗?而且 actor 模型下不用加锁就能处理并发问题,为什么没人用呢?而且采用 acotr 模型就可以利用进程内缓存的形式,比请求局域网 redis 的网络延迟要低很多。
本文转载自微信公众号「 架构师修行之路」,可以通过以下二维码关注。转载本文请联系 架构师修行之路公众号

【编辑推荐】
【责任编辑:武晓燕 TEL:(010)68476606】
标签:分库分表 分表 boot 解决 选择 根据 为什么 读写 增加
原文地址:https://blog.51cto.com/14887308/2524126