标签:linu 调用 控制 方便 debug cli logs static arc
谷歌在2010年4月发表了一篇论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》(http://1t.click/6EB),介绍了分布式追踪的概念。
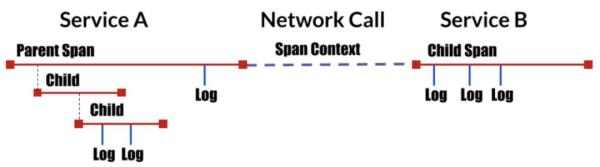
对于分布式追踪,主要有以下的几个概念:
随着搜索系统的扩大和微服务的流行,一次请求涉及的服务往往是很多次调用,这些模块,通常是由不同团队,甚至是不同语言编写的,所以,可能部署在数十台服务器、横款多个数据中心。因此,在排查问题时,就不能人工对调用链路通过日志分析问题,我们需要轻松的获取到调用链上的每次请求的情况,以便能快速定位和分析问题。
所以全链路监控的目标是

OpenTracing 是一个分布式追踪规范。OpenTracing 通过提供平台无关、厂商无关的 API,为分布式追踪提供统一的概念和数据标准,使得开发人员能够方便的添加(或更换)追踪系统的实现。OpenTracing 定义了如下几个术语:
OpenTracing 还有其他一些概念,这里不过多解释。我们看个传统的调用关系例子,如下所示:

在一个分布式系统中,追踪一个事务或者调用流一般如上图所示。虽然这种图对于看清各组件的组合关系是很有用的,但是,它不能很好显示组件的调用时间,以及是串行调用还是并行调用。如果展现更复杂的调用关系,会更加复杂,甚至无法画出这样的图。另外,这种图也无法显示调用间的时间间隔以及是否通过定时调用来启动调用。一种更有效的展现一个典型的 trace 过程,如下图所示:
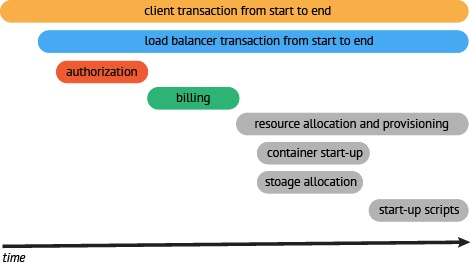
这种展现方式增加了执行时间的上下文,相关服务间的层次关系,进程或者任务的串行或并行调用关系。这样的视图有助于发现系统调用的关键路径。通过关注关键路径的执行过程,项目团队可能专注于优化路径中的关键位置,最大幅度地提升系统的性能。例如:可以通过追踪一个资源定位的调用情况,明确底层的调用情况,发现哪些操作有阻塞的情况。
OpenTracing 标准概念
基于谷歌提出的概念OpenTracing(http://1t.click/6tC)定义了一个开放的分布式追踪的标准。
Span是分布式追踪的基本组成单元,表示一个分布式系统中的单独的工作单元。每一个Span可以包含其它Span的引用。多个Span在一起构成了Trace。
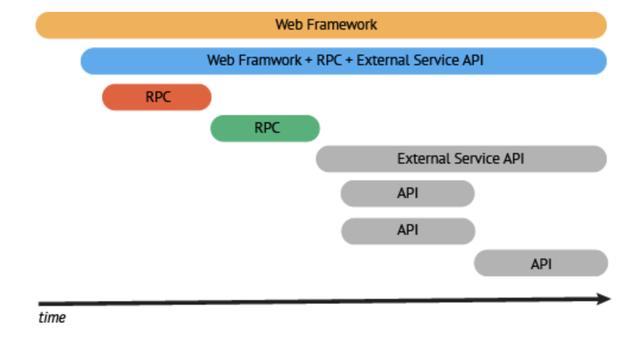
OpenTracing的规范定义每一个Span都包含了以下内容:
这里是一个Span的例子:
t=0 operation name: db_query t=x +-----------------------------------------------------+ | · · · · · · · · · · Span · · · · · · · · · · | +-----------------------------------------------------+ Tags: - db.instance:"jdbc:mysql://127.0.0.1:3306/customers - db.statement: "SELECT * FROM mytable WHERE foo=‘bar‘;" Logs: - message:"Can‘t connect to mysql server on ‘127.0.0.1‘(10061)" SpanContext: - trace_id:"abc123" - span_id:"xyz789" - Baggage Items: - special_id:"vsid1738"
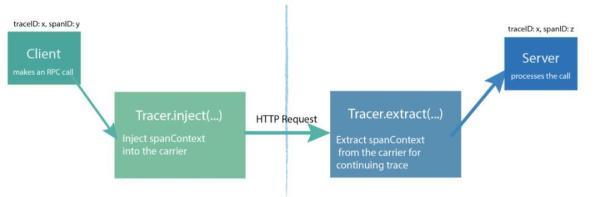
要实现分布式追踪,如何传递SpanContext是关键。OpenTracing定义了两个方法Inject和Extract用于SpanContext的注入和提取。
Inject 伪代码
span_context = ...
outbound_request = ...
# We‘ll use the (builtin) HTTP_HEADERS carrier format. We
# start by using an empty map as the carrier prior to the
# call to `tracer.inject`.
carrier = {}
tracer.inject(span_context, opentracing.Format.HTTP_HEADERS, carrier)
# `carrier` now contains (opaque) key:value pairs which we pass
# along over whatever wire protocol we already use.
for key, value in carrier:
outbound_request.headers[key] = escape(value)
这里的注入的过程就是把context的所有信息写入到一个叫Carrier的字典中,然后把字典中的所有名值对写入 HTTP Header。
Extract 伪代码
inbound_request = ...
# We‘ll again use the (builtin) HTTP_HEADERS carrier format. Per the
# HTTP_HEADERS documentation, we can use a map that has extraneous data
# in it and let the OpenTracing implementation look for the subset
# of key:value pairs it needs.
#
# As such, we directly use the key:value `inbound_request.headers`
# map as the carrier.
carrier = inbound_request.headers
span_context = tracer.extract(opentracing.Format.HTTP_HEADERS, carrier)
# Continue the trace given span_context. E.g.,
span = tracer.start_span("...", child_of=span_context)
# (If `carrier` held trace data, `span` will now be ready to use.)
抽取过程是注入的逆过程,从carrier,也就是HTTP Headers,构建SpanContext。
整个过程类似客户端和服务器传递数据的序列化和反序列化的过程。这里的Carrier字典支持Key为string类型,value为string或者Binary格式(Bytes)。
Jaeger 是 OpenTracing 的一个实现,是 Uber 开源的一个分布式追踪系统,其灵感来源于Dapper 和 OpenZipkin。从 2016 年开始,该系统已经在 Uber 内部得到了广泛的应用,它可以用于微服务架构应用的监控,特性包括分布式上下文传播(Distributed context propagation)、分布式事务监控、根原因分析、服务依赖分析以及性能优化。该项目已经被云原生计算基金会(Cloud Native Computing Foundation,CNCF)接纳为第 12 个项目。
我们使用 Docker 启动 Jaeger + Jaeger UI(Jaeger 可视化 web 控制台),运行如下命令:
$ docker run -d -p5775:5775/udp \ -p 6831:6831/udp \ -p 6832:6832/udp \ -p 5778:5778 \ -p 16686:16686 \ -p 14268:14268 \ jaegertracing/all-in-one:latest浏览器打开 localhost:16686,如下所示:

更多参考:
标签:linu 调用 控制 方便 debug cli logs static arc
原文地址:https://www.cnblogs.com/-wenli/p/13575571.html