标签:htm 搭建 测试 nod sbin shuff 注意 art 变化
一.环境介绍2.每个节点配置好hosts解析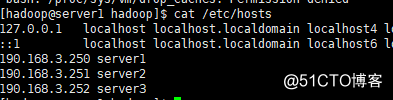
3.下载好软件
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
hadoop-3.2.1.tar.gz
jdk-8u261-linux-x64.tar
注意:这里使用的是java8,之前使用高版本的hdfs web界面目录会报错
4.每个节点安装java环境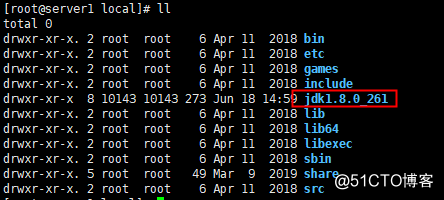
[root@server1 local]# vi /etc/profile
export JAVA_HOME=/usr/local/jdk1.8.0_261
export PATH=$JAVA_HOME/bin:$PATH
source /etc/profile
5.创建用户和工作目录
每个节点创建hadoop用户
useradd hadoop
echo hadoop | passwd --stdin hadoop
设置权限,可以将hadoop用户的权限设置的大一些,但是生产环境一定要注意普通用户的权限限制
vim /etc/sudoers
hadoop ALL=(root) NOPASSWD:ALL
创建程序目录mkdir /data/
6.所有主机做好免密
190.168.3.250
在hadoop用户下
ssh-keygen
ssh-copy-id 190.168.3.250
ssh-copy-id 190.168.3.251
ssh-copy-id 190.168.3.252
190.168.3.251
在hadoop用户下
ssh-keygen
ssh-copy-id 190.168.3.250
ssh-copy-id 190.168.3.251
ssh-copy-id 190.168.3.252
190.168.3.252
在hadoop用户下
ssh-keygen
ssh-copy-id 190.168.3.250
ssh-copy-id 190.168.3.251
ssh-copy-id 190.168.3.252
二.Hadoop3.2.1伪分布式搭建
伪分布式是所有组件都在一台机子上了,我们这里使用主节点190.168.3.250搭建,弄完了我们再搭三台机子的分布式
1.解压hadoop到/data目录下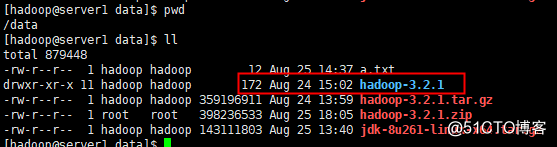
2.配置hadoop环境变量
在root下 vim /etc/profile追加,这样可以全局使用hdfs脚本
export HADOOP_HOME=/data/hadoop-3.2.1
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
3.给hadoop配置java环境变量
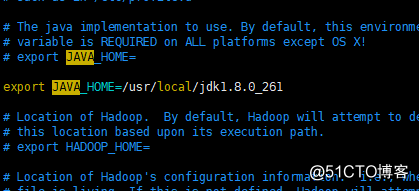
需要配置 hadoop-env.sh、mapred-env.sh、yarn-env.sh文件的JAVA_HOME参数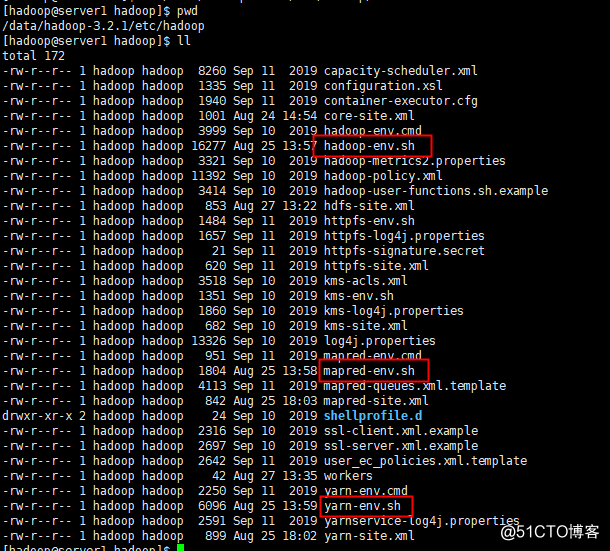
4.配置core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://190.168.3.250:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop-3.2.1/tmp</value>
</property>
</configuration>
指定NameNode的通信地址,可以写ip地址,也可以写主机名
指定hadoop运行时产生文件的存储目录,提前创建好tmp目录mkdir /data/hadoop-3.2.1/tmp
5.配置hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
伪分布式所以副本为1个,这个选项的意思是相同的数据在集群里有几份,一般小于节点数
6.配置workers
这块也有个坑,之前2版本的slaves,现在变成workers
由于现在是单节点,里面只要加上190.168.3.250即可
7.格式化HDFS hdfs namenode -format
[hadoop@server1 hadoop-3.2.1]$ hdfs namenode -format
出现这个字眼表示成功,可以看到存储地址和格式化成功的字样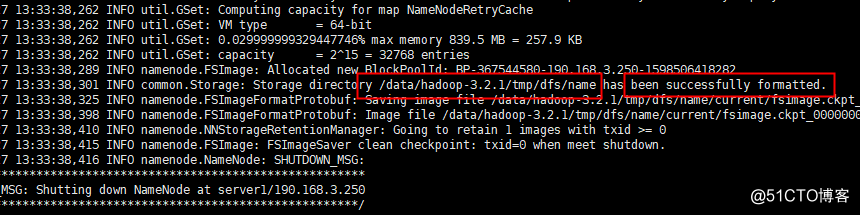
查看tmp下有数据也可以表示格式化成功,存储目录发生改变,要重新格式化,9000出口入口
8.启动hdfs start-dfs.sh
[hadoop@server1 hadoop-3.2.1]$ start-dfs.sh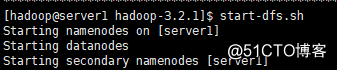
[hadoop@server1 hadoop-3.2.1]$ jps
13105 SecondaryNameNode
12898 DataNode
12740 NameNode
15321 Jps
表示成功,关闭stop-dfs.sh
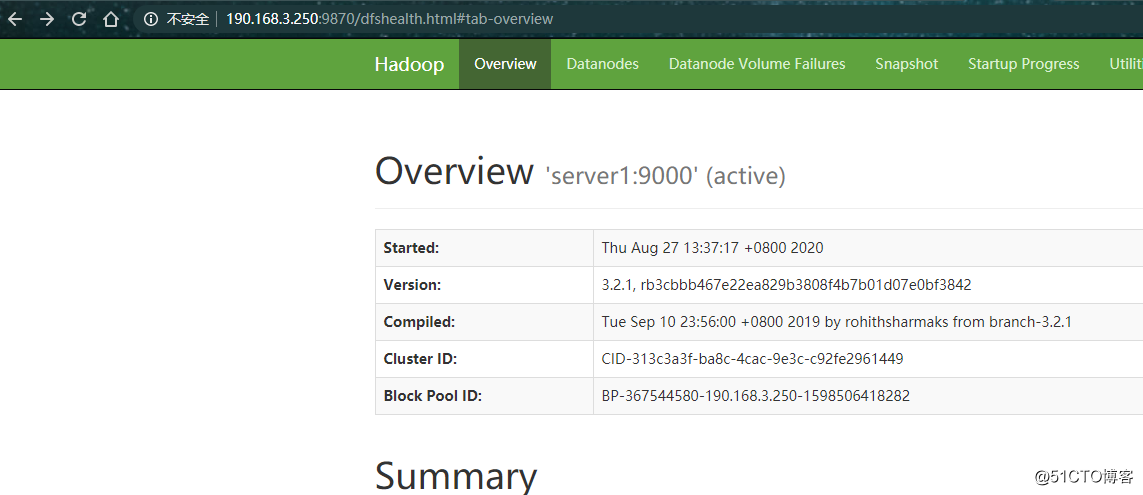
我们可以访问下hdfs的web界面
之前我这边之前搭过2.x,这回3版本的端口都变了
Hadoop3.x相较于之前的版本来说,在端口的设置上发生了一些变化,先就这些端口变化总结如下:
Namenode ports: 50470 --> 9871, 50070 --> 9870, 8020 --> 9820
Secondary NN ports: 50091 --> 9869, 50090 --> 9868
Datanode ports: 50020 --> 9867, 50010 --> 9866, 50475 --> 9865, 50075 --> 9864
9.配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
将mapReduce配置到yarn上运行
10.配置yarn-site.xml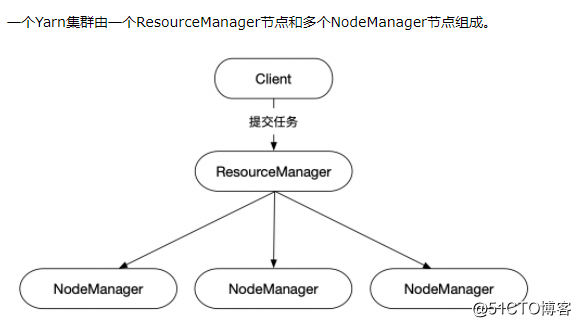
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>190.168.3.250</value>
</property>
</configuration>
配置Reduce取数据的方式是shuffle(随机)
设置ResourceManager的地址190.168.3.250
启动start-yarn.sh
[hadoop@server1 hadoop]$ jps
48661 DataNode
48504 NameNode
48856 SecondaryNameNode
51160 ResourceManager
51294 NodeManager
51647 Jps
关闭stop-yarn.sh
查看yarn的web页面http://190.168.3.250:8088/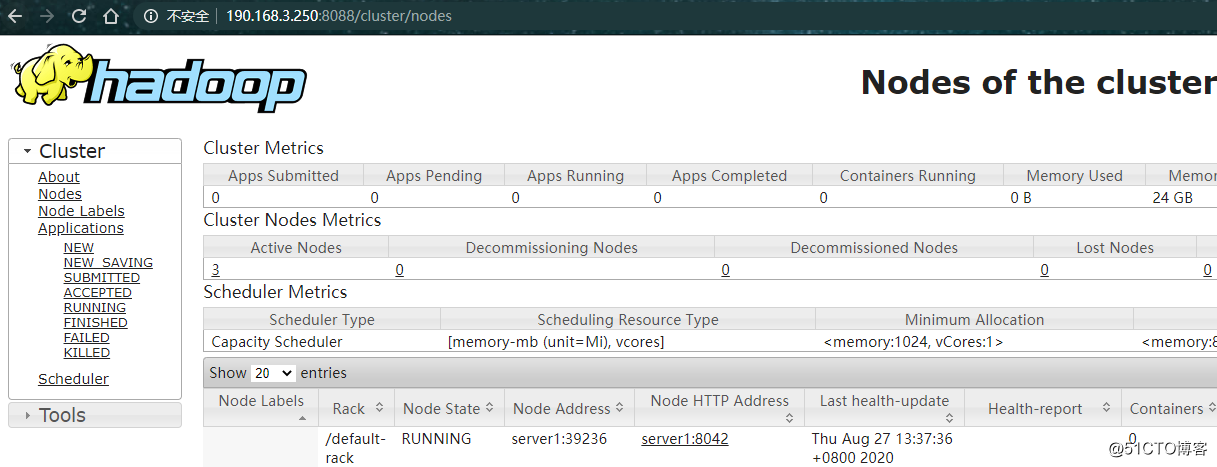
三.Hadoop3.2.1分布式搭建
1.停掉刚才的服务
stop-yarn.sh
stop-dfs.sh
[hadoop@server1 hadoop]$ jps
51647 Jps
2.修改hdfs-site.xml副本数,三个节点,我们这里改为2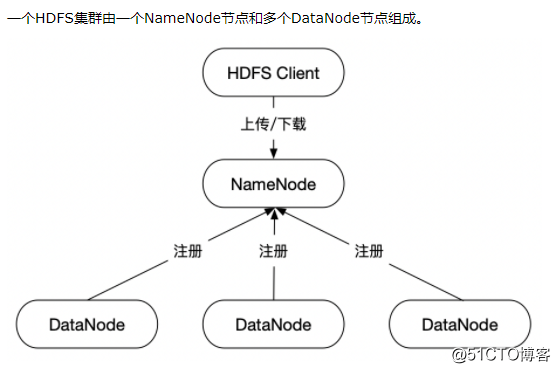
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
3.修改workers
190.168.3.250
190.168.3.251
190.168.3.252
剩下的core-site.xml mapred-site.xml 和 yarn-site.xml 不用改
4.分发主程序
scp /data/hadoop-3.2.1 root@190.168.3.251:/data
scp /data/hadoop-3.2.1 root@190.168.3.252:/data
分发过去注意看好权限和所属主,我们这里使用的是hadoop用户
5.启动服务
在190.168.3.250上,我们之前搭的有伪分布式的,所以为了不影响,我们删除/data/hadoop-3.2.1/tmp/下的数据,重新格式化
注意分布式只要在一个节点格式化就可以了
hdfs namenode -format
看到成功后分别启动
start-dfs.sh
start-yarn.sh
查看结果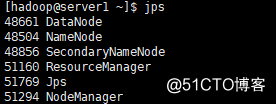
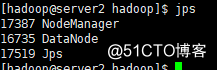
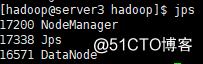
web界面http://190.168.3.250:9870/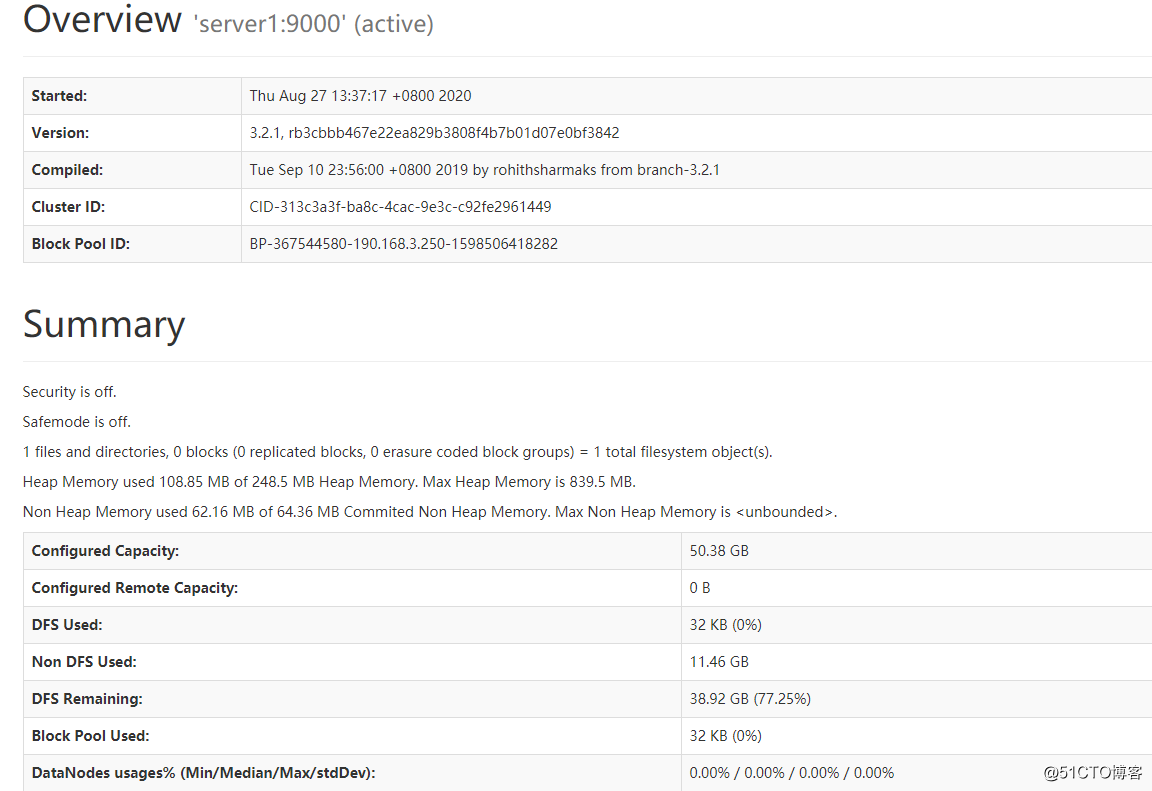
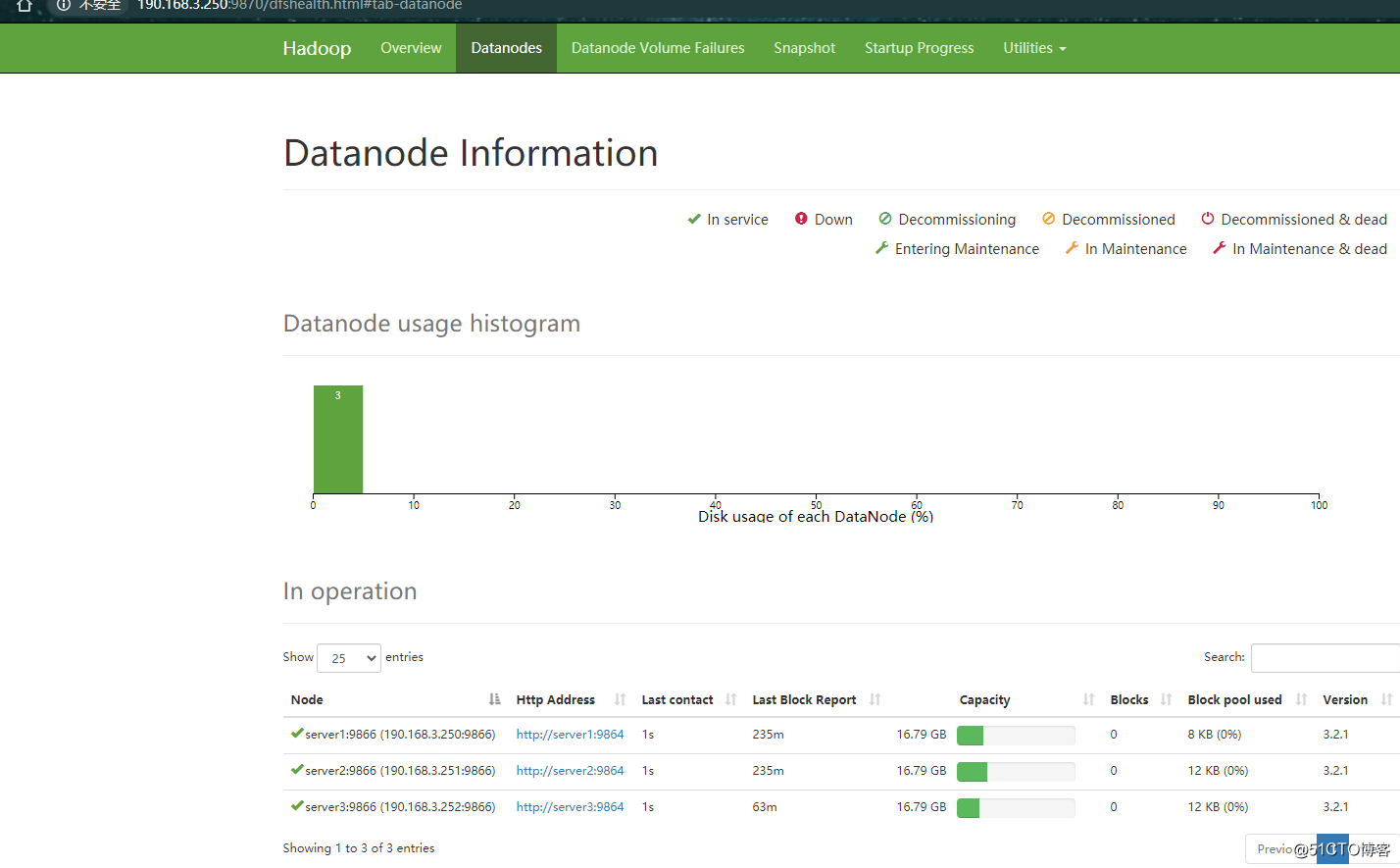
Yarn的可视化管理界面http://190.168.3.250:8088/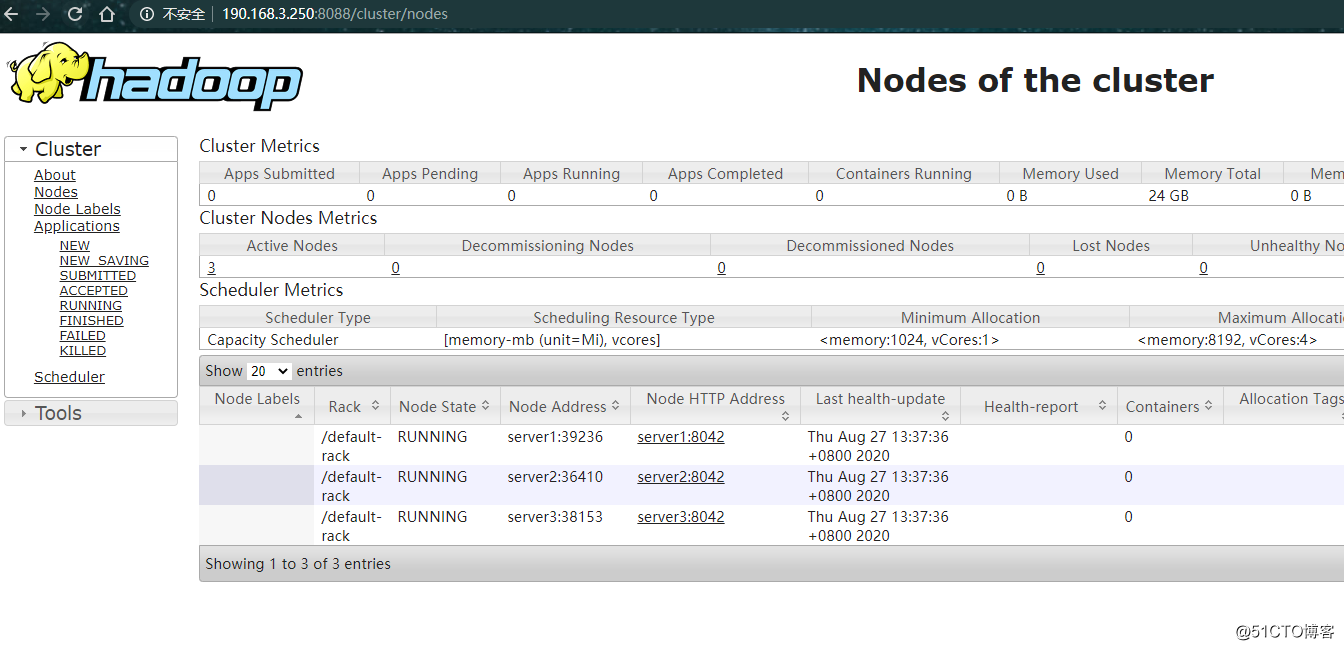
四.HDFS上测试创建目录、上传、下载文件
创建目录
[hadoop@server1 hadoop-3.2.1]$ hdfs dfs -mkdir /hello
上传
[hadoop@server1 data]$ hdfs dfs -put a.txt /hello
下载
[hadoop@server2 mnt]$ hdfs dfs -cat /hello/a.txt
web页面上看到了刚才上传的文件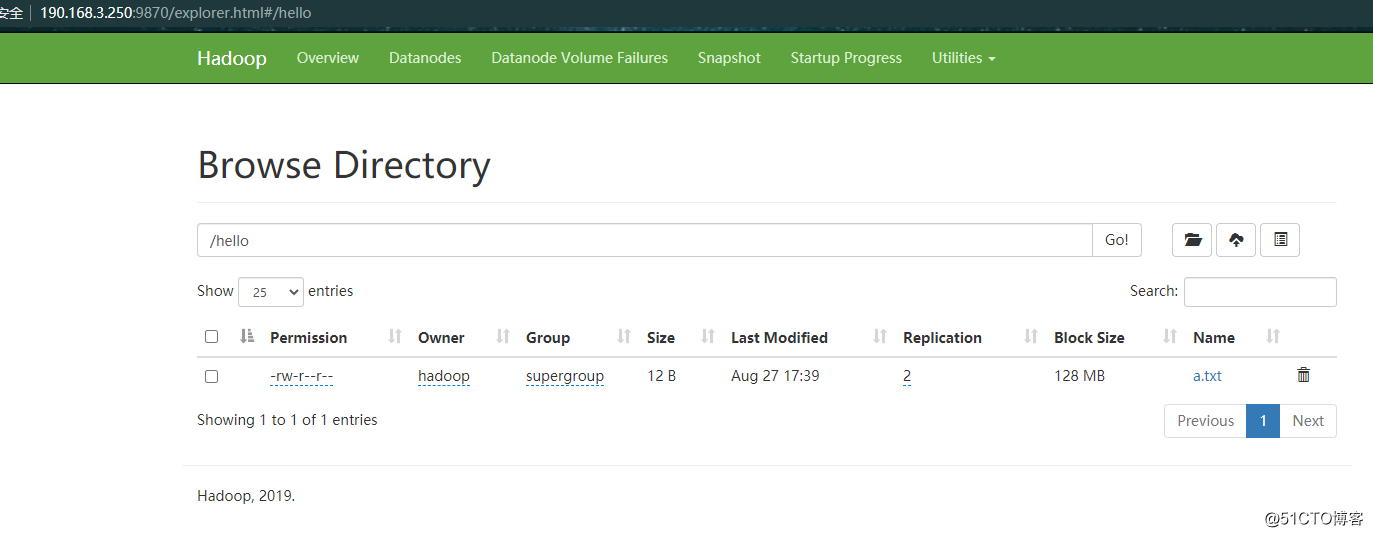
保存了2份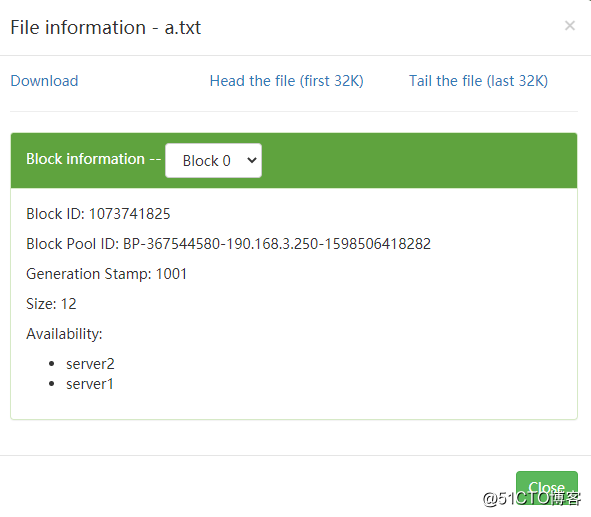
查看集群状态
[hadoop@server1 hadoop]$ hdfs dfsadmin -report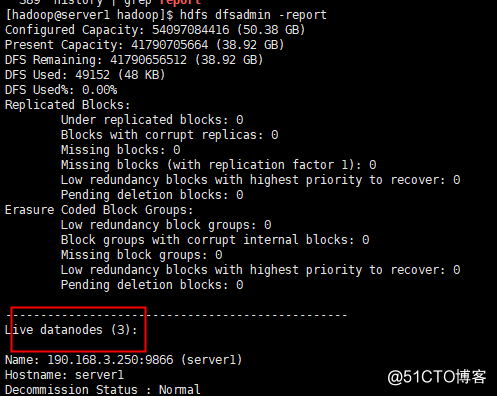
标签:htm 搭建 测试 nod sbin shuff 注意 art 变化
原文地址:https://blog.51cto.com/anfishr/2524895