标签:存储 core keyword 查询 依赖 分词器 文件中 mamicode inf
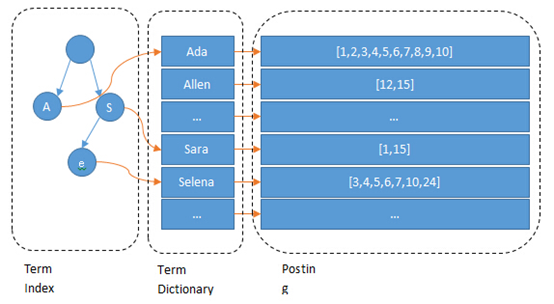
搜索引擎三大过程
爬取内容、进行分词、建立倒排索引。
分词器
分词器使用IK,通常为了保证索引时覆盖度和搜索时准确度,索引分词器采用ik_max_word,搜索分析器采用ik_smart模式。可在IK的配置文件中配置自定义的词典、停词词典。
倒排索引
Elasticsearc依赖Lucene建立倒排索引,并提供分布式的文档存储系统。
索引、类型、文档、属性
数据库、表、行、列。Keyword 类型是不会分词的,直接根据字符串内容建立反向索引,Text 类型在存入 Elasticsearch 的时候,会先分词,然后根据分词后的内容建立反向索引。
查询
Match用于部分匹配,term用于精确匹配。
评分
在查询条件中,通过function_score属性设置相关度算法进行排序。
低级评分:词频、逆向文档频率。
高级:field_value_factor、衰减函数等。
搜索建议
对搜索建议,ES 采用了不同的数据结构。并非通过倒排索引来完成,而是将 Analyze 的数据编码成 FST 和倒排索引放在一起。FST 只能用于前缀查找。
标签:存储 core keyword 查询 依赖 分词器 文件中 mamicode inf
原文地址:https://www.cnblogs.com/running-chicken/p/13576016.html