标签:cal custom 就是 ack 字节 window 本质 thread bitarray
昨天发现线上试跑期的一个程序挂了,平时都跑的好好的,查了下日志是因为昨天运营跑了一家美妆top级淘品牌店,会员量近千万,一下子就把128G的内存给爆了,当时并行跑了二个任务,没辙先速写一段代码限流,后面再做进一步优化。1. 背景介绍
因为是自己写的代码,所以我知道问题出现在哪里,如果大家看过我之前写的文章应该知道我用全内存跑了很多模型对用户打标签,一个模型就是一组定向的筛选条件,而为了加速处理,我会原子化筛选条件,然后一边查询一边缓存原子化条件获取的人数,后面的模型如果命中了前面模型的原子化条件,那么可以直接从缓存中读取它的人数即可,这也是动态规划的思想~ ,如果不明白我来画张图。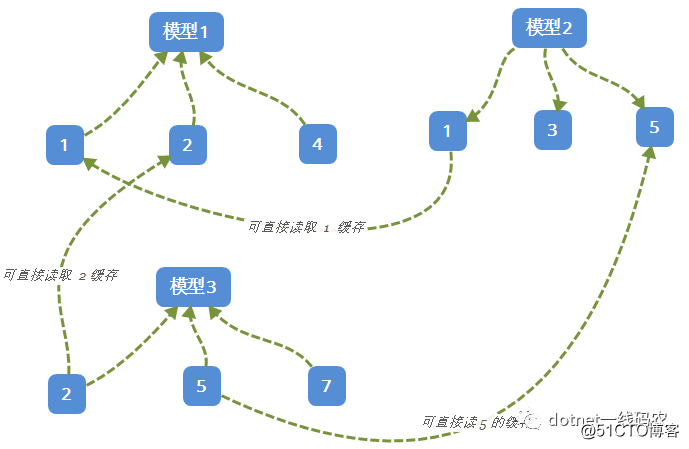
从上面图可以看到,在计算模型2的时候,条件1的人数可以直接从模型1下的条件1处获取,模型三下的2,5的人数也可以直接从模型1和2处获取,这样就大大加速的处理速度。
2. 找原因
刚才提到了缓存人数,我也不知道为什么用了这么一个类型,如下代码:
/// <summary>
/// 缓存原子人群
/// key: 原子化条件
/// value: 人数集合
/// </summary>
public ConcurrentDictionary<string, List<long>> CachedCrowds { get; set; } = new ConcurrentDictionary<string, List<long>>();我说的是里面的List\,我居然用了long类型存储customerID,可能是看了这个项目先祖原先定义的long才跟风成long,谁家店有数不尽的客户,国家才14亿人呢,而一个long占用8个字节,明显是一种浪费。
1. 将long转成int
人都是懒的,能少改点代码就少改点,省的背锅,好事不出门,坏事传千里,所以这里用int表示就足够了,应该能省一半的空间对不对,接下来为了演示,在List\ 和 List\ 中分别灌入 500w 客户ID,代码如下:
public static void Main(string[] args)
{
var rand = new Random();
List<int> intCustomerIDList = Enumerable.Range(1, 5000000).OrderBy(m => rand.Next(0, 100000))
.Take(5000000).ToList();
List<long> longCustomerIDList = Enumerable.Range(1, 5000000).OrderBy(m => rand.Next(0, 100000))
.Take(5000000).Select(m => (long)m).ToList();
Console.WriteLine("处理完毕...");
Console.Read();
}接下来用windbg看一下他们在堆中各占多少内存。
~0s -> !clrstack -l -> !dumpobj 从主线程找到List\和List\ 的局部变量,然后查看size。
0:000> ~0s
ntdll!ZwReadFile+0x14:
00007ff8`fea4aa64 c3 ret
0:000> !clrstack -l
OS Thread Id: 0x5b70 (0)
Child SP IP Call Site
00000015c37feed0 00007ff889e60b9c ConsoleApp2.Program.Main(System.String[]) [C:\dream\Csharp\ConsoleApp1\ConsoleApp2\Program.cs @ 35]
LOCALS:
0x00000015c37fef90 = 0x0000014ad7c12d88
0x00000015c37fef88 = 0x0000014ad7c13060
0x00000015c37fef80 = 0x0000014ad7c33438
00000015c37ff1a8 00007ff8e9396c93 [GCFrame: 00000015c37ff1a8]
0:000> !do 0x0000014ad7c13060
Name: System.Collections.Generic.List`1[[System.Int32, mscorlib]]
MethodTable: 00007ff8e7aaa068
EEClass: 00007ff8e7c0b008
Size: 40(0x28) bytes
File: C:\WINDOWS\Microsoft.Net\assembly\GAC_64\mscorlib\v4.0_4.0.0.0__b77a5c561934e089\mscorlib.dll
Fields:
MT Field Offset Type VT Attr Value Name
00007ff8e7a98538 400189e 8 System.Int32[] 0 instance 0000014af02d1020 _items
00007ff8e7a985a0 400189f 18 System.Int32 1 instance 5000000 _size
00007ff8e7a985a0 40018a0 1c System.Int32 1 instance 5000000 _version
00007ff8e7a95dd8 40018a1 10 System.Object 0 instance 0000000000000000 _syncRoot
00007ff8e7a98538 40018a2 0 System.Int32[] 0 shared static _emptyArray
>> Domain:Value dynamic statics NYI 0000014ad61166c0:NotInit <<
0:000> !do 0000014af02d1020
Name: System.Int32[]
MethodTable: 00007ff8e7a98538
EEClass: 00007ff8e7c05918
Size: 33554456(0x2000018) bytes
Array: Rank 1, Number of elements 8388608, Type Int32 (Print Array)
Fields:
None
0:000> !do 0x0000014ad7c33438
Name: System.Collections.Generic.List`1[[System.Int64, mscorlib]]
MethodTable: 00007ff8e7aad2a0
EEClass: 00007ff8e7c0bd70
Size: 40(0x28) bytes
File: C:\WINDOWS\Microsoft.Net\assembly\GAC_64\mscorlib\v4.0_4.0.0.0__b77a5c561934e089\mscorlib.dll
Fields:
MT Field Offset Type VT Attr Value Name
00007ff8e7aa6c08 400189e 8 System.Int64[] 0 instance 0000014a80001020 _items
00007ff8e7a985a0 400189f 18 System.Int32 1 instance 5000000 _size
00007ff8e7a985a0 40018a0 1c System.Int32 1 instance 5000000 _version
00007ff8e7a95dd8 40018a1 10 System.Object 0 instance 0000000000000000 _syncRoot
00007ff8e7aa6c08 40018a2 0 System.Int64[] 0 shared static _emptyArray
>> Domain:Value dynamic statics NYI 0000014ad61166c0:NotInit <<
0:000> !do 0000014a80001020
Name: System.Int64[]
MethodTable: 00007ff8e7aa6c08
EEClass: 00007ff8e7c09e50
Size: 67108888(0x4000018) bytes
Array: Rank 1, Number of elements 8388608, Type Int64 (Print Array)
Fields:
None仔细看上图,在主线程的堆栈中找到了三个变量,后两个变量就是我们的List\ 和 List\,分别是
Size: 33554456(0x2000018) bytes => 33554456/1024/1024 = 32M
Size:67108888(0x4000018) bytes => 67108888/1024/1024 = 64M
以后可以跟别人吹牛了,我知道500w个int占用是32M内存,虽然内存空间优化了一半,但没有本质性的优化,还得继续往上挖,否则同时跑4个任务又要把内存给爆掉了。。。
2. 使用bitarray
我们在学习数据结构的时候,相信很多人都学习过bitmap,刚好原子化的筛选条件获取的人数众多,使用bitmap刚好满足我的业务需求,如果不知道bitmap我简单解释一下。
<1 style="box-sizing: border-box;"> 原理解释
我们都知道一个int是4个字节。也就是4byte,也就是32bit,画成图就是32个格子,如下所示: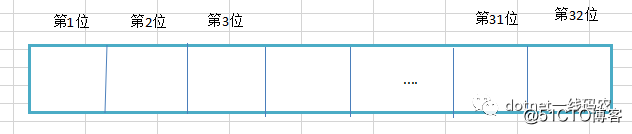
默认情况下32个格子表示一个int是不是有点浪费,其实32个格子可以放置32个数字(1-32)。比如1放在第一个格子里,3放在第三个格子里。。。32放在第32个格子里,那么两个int就可以存放1-64个数字,也就是说理想情况下可以优化空间32倍,思维一定要反转一下,把数字作为数组的下标,因为是bit,所以0,1两种状态刚好可以表示当前格子是否已经被设置了,1表示已设置,0表示未设置,好好品味一下,如果还是不明白,可以参考我八年前的文章:
经典算法题每日演练——第十一题 Bitmap算法
在C#中已经帮我们设置好了一个BitArray类,结合我刚才讲得,大家好好品味一下bitarray如何向各自格子中设置值的,底层还是用m_array承载,它其实是一个int[]。
public void Set(int index, bool value){
if (value)
{
m_array[index / 32] |= 1 << index % 32;
}
else
{
m_array[index / 32] &= ~(1 << index % 32);
}
_version++;
}
public bool Get(int index){
return (m_array[index / 32] & (1 << index % 32)) != 0;
}<2 style="box-sizing: border-box;"> 查看内存占用
接下来把List\ 中的数据灌入到bitArray中看看,先上一下代码:
public static void Main(string[] args)
{
var rand = new Random();
List<int> intCustomerIDList = Enumerable.Range(1, 5000000).OrderBy(m => rand.Next(0, 100000))
.Take(5000000).ToList();
BitArray bitArray = new BitArray(intCustomerIDList.Max() + 1);
foreach (var customerID in intCustomerIDList)
{
bitArray[customerID] = true;
}
Console.WriteLine("处理完毕...");
Console.Read();
}
然后抓一下dump文件,用windbg看一下内存占用。
0:000> !do 0x0000026e4d0332b8
Name: System.Collections.BitArray
MethodTable: 00007ff8e7a89220
EEClass: 00007ff8e7c01bc0
Size: 40(0x28) bytes
File: C:\WINDOWS\Microsoft.Net\assembly\GAC_64\mscorlib\v4.0_4.0.0.0__b77a5c561934e089\mscorlib.dll
Fields:
MT Field Offset Type VT Attr Value Name
00007ff8e7a98538 4001810 8 System.Int32[] 0 instance 0000026e5dfd9bd8 m_array
00007ff8e7a985a0 4001811 18 System.Int32 1 instance 5000001 m_length
00007ff8e7a985a0 4001812 1c System.Int32 1 instance 5000000 _version
00007ff8e7a95dd8 4001813 10 System.Object 0 instance 0000000000000000 _syncRoot
0:000> !DumpObj /d 0000026e5dfd9bd8
Name: System.Int32[]
MethodTable: 00007ff8e7a98538
EEClass: 00007ff8e7c05918
Size: 625028(0x98984) bytes
Array: Rank 1, Number of elements 156251, Type Int32 (Print Array)Fields:None从图中可以看到,没错,就是bitArray类型,从Size中可以看到:
Size: 625028(0x98984) bytes => 625028/1024/1024 = 0.59M
看到没有,由最初的64M优化到了0.6M,简直不要太爽,看到这么小的占用量,我感到枯燥而乏味,哈哈,这下并行跑几十家不怕了,这里要提醒一下,如果客户数少并且数字还大,就不要用bitArray啦,反而浪费空间,当然数据量小怎么用也无所谓。
跑小店铺的时候代码怎么写都行,数据量大了到处都是坑,你的场景也总有优化的办法~
标签:cal custom 就是 ack 字节 window 本质 thread bitarray
原文地址:https://blog.51cto.com/huangxincheng/2525743