标签:info 干货 收盘价 nes 分析 常见 字符 频率 类型
Pandas数据处理——玩转时间序列数据原创 易执 Python读财 3月16日
点击上方“Python读财”,选择“星标”公众号
重磅干货,第一时间送达
进行金融数据分析或量化研究时,总避免不了时间序列数据的处理,时间序列是指在一定时间内按时间顺序测量的某个变量的取值序列。常见的时间序列数据有一天内随着时间变化的温度序列,又或者交易时间内不断波动的股票价格序列。Pandas也因其强大的时序处理能力而被广泛应用于金融数据分析,这篇文章为大家介绍一下Pandas中的时间序列处理,所使用的数据是上证指数2019年的行情数据。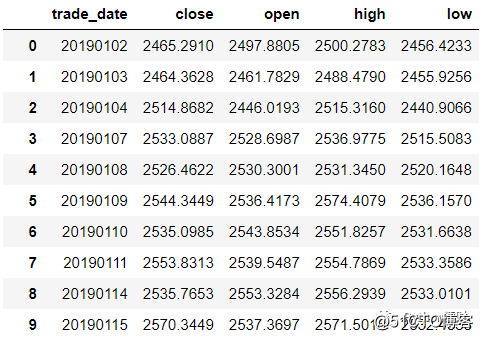
Pandas时序处理中最常见的两种数据类型为datetime和timedelta。一个datetime可以如下图所示: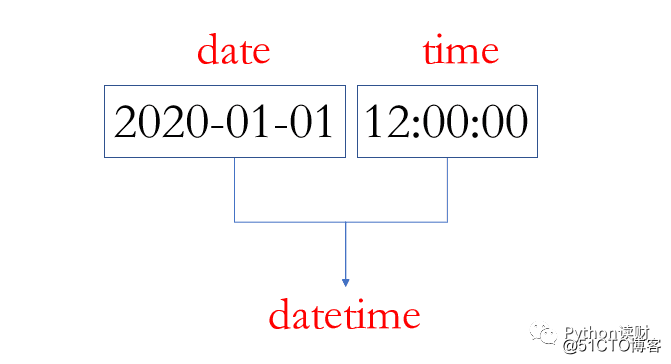
datetime顾名思义就是既有日期date也有时间time,表示一个具体的时间点(时间戳)。timedelta则表示两个时间点之间的差,比如2020-01-01和2020-01-02之间的timedelta即为一天,相信并不难理解。
大多数时候,我们是从csv文件中导入数据,此时Dataframe中对应的时间列是字符串的形式,如下:
In [5]: data.trade_date.head()
Out[5]:
0 20190102
1 20190103
2 20190104
3 20190107
4 20190108
Name: trade_date, dtype: object运用pd.to_datetime(),可以将对应的列转换为Pandas中的datetime64类型,便于后期的处理
In [11]: data["trade_date"] = pd.to_datetime(data.trade_date)
In [12]: data.trade_date.head()
Out[12]:
0 2019-01-02
1 2019-01-03
2 2019-01-04
3 2019-01-07
4 2019-01-08
Name: trade_date, dtype: datetime64[ns]时间序列中索引和Pandas普通的索引类似,大多时候调用.loc[index,columns]进行相应的索引,直接上代码看看
In [20]: data1 = data.set_index("trade_date")
# 2019年6月的数据
In [21]: data1.loc["2019-06"].head()
Out[21]:
close open high low
trade_date
2019-06-03 2890.0809 2901.7424 2920.8292 2875.9019
2019-06-04 2862.2803 2887.6405 2888.3861 2851.9728
2019-06-05 2861.4181 2882.9369 2888.7676 2858.5719
2019-06-06 2827.7978 2862.3327 2862.3327 2822.1853
2019-06-10 2852.1302 2833.0145 2861.1310 2824.3554
# 2019年6月-2019年8月的数据
In [22]: data1.loc["2019-06":"2019-08"].tail()
Out[22]:
close open high low
trade_date
2019-08-26 2863.5673 2851.0158 2870.4939 2849.2381
2019-08-27 2902.1932 2879.5154 2919.6444 2879.4060
2019-08-28 2893.7564 2901.6267 2905.4354 2887.0115
2019-08-29 2890.9192 2895.9991 2898.6046 2878.5878
2019-08-30 2886.2365 2907.3825 2914.5767 2874.1028在时序数据处理过程中,经常需要实现下述需求:
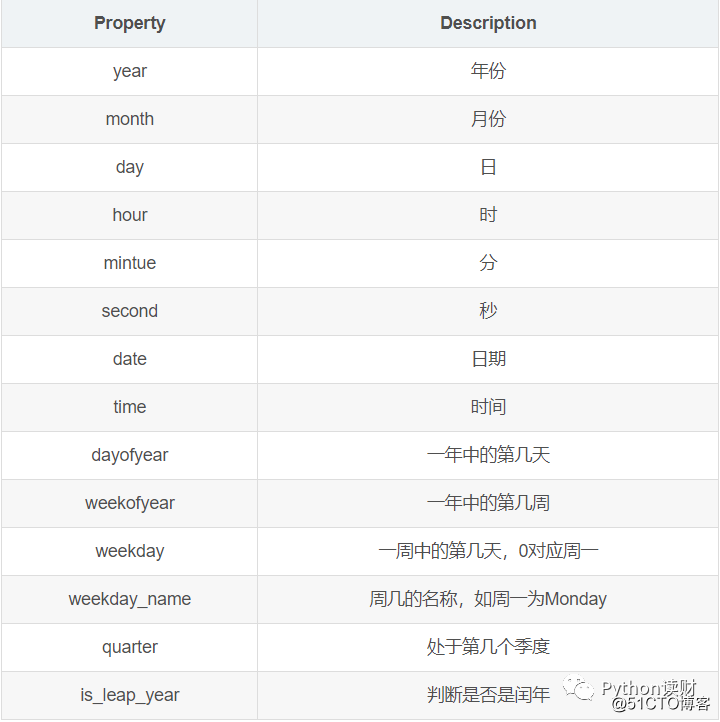
# 一年中的第几天
In [13]: data.trade_date.dt.dayofweek[0]
Out[13]: 2
# 返回对应日期
In [14]: data.trade_date.dt.date[0]
Out[14]: datetime.date(2019, 1, 2)
# 返回周数
In [15]: data.trade_date.dt.weekofyear[0]
Out[15]: 1
# 返回周几
In [16]: data.trade_date.dt.weekday_name[0]
Out[16]: ‘Wednesday‘resample翻译过来是重采样的意思,官方文档中是这么描述resample的
resample() is a time-based groupby翻译过来就是基于时间的groupby操作,我个人认为这是Pandas时间序列处理中最重要的功能,也是本文的重中之重。
根据采样是从低频到高频还是从高频到低频可以分为升采样和降采样两种方式,先来看看降采样是啥
In [32]: data.resample(‘Q‘,on=‘trade_date‘)["close"].mean()
Out[32]:
trade_date
2019-03-31 2792.941622
2019-06-30 3010.354672
2019-09-30 2923.136748
2019-12-31 2946.752270
Freq: Q-DEC, Name: close, dtype: float64其中‘Q‘是以季度为频率进行采样,on指定datetime列(如果索引为Datetimeindex,则on不需要指定,默认依据索引进行降采样)。整个过程图解如下: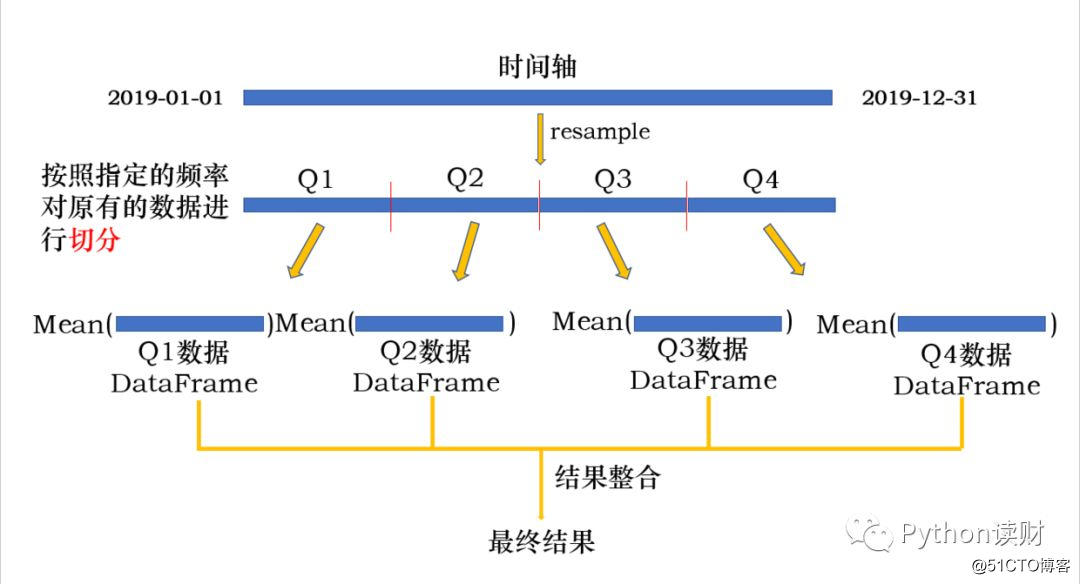
整个过程其实就是一个groupby过程:
In [24]: example
Out[24]:
close
trade_date
2019-01-02 2465.2910
2019-01-03 2464.3628
In [25]: example.resample(‘6H‘).asfreq()
Out[25]:
close
trade_date
2019-01-02 00:00:00 2465.2910
2019-01-02 06:00:00 NaN
2019-01-02 12:00:00 NaN
2019-01-02 18:00:00 NaN
2019-01-03 00:00:00 2464.362
8对resample后的结果应用.asfreq()会返回新频率下的结果。可以看到升采样后产生了缺失值。如果想要填充缺失值可以采用向后填充.bfill()或向前填充.ffill()的方式:
# 向前填充,缺失值取2465.2910进行填充
In [29]: example.resample(‘6H‘).ffill()
Out[29]:
close
trade_date
2019-01-02 00:00:00 2465.2910
2019-01-02 06:00:00 2465.2910
2019-01-02 12:00:00 2465.2910
2019-01-02 18:00:00 2465.2910
2019-01-03 00:00:00 2464.3628
# 向后填充,缺失值取2464.3628进行填充
In [30]: example.resample(‘6H‘).bfill()
Out[30]:
close
trade_date
2019-01-02 00:00:00 2465.2910
2019-01-02 06:00:00 2464.3628
2019-01-02 12:00:00 2464.3628
2019-01-02 18:00:00 2464.3628
2019-01-03 00:00:00 2464.3628总结一下resample,resample可以对原有的时间序列进行任何频率freq的采样,如果从低频到高频为升采样,高频到低频为降采样。整个操作过程和groupby基本一致,所以也可以对resample后的对象进行apply和transform等操作,具体操作和原理这里就不多解释了,类比于groupby即可,参看这篇文章Pandas数据分析——超好用的Groupby详解。
往期精彩回顾
Pandas数据处理三板斧,你会几板?
Pandas数据分析——超好用的Groupby详解
Pandas数据处理——一文详解数据拼接方法merge
一文带你掌握常见的Pandas性能优化方法,让你的pandas飞起来!
Pandas数据处理——盘点那些常用的函数(上)
Pandas数据处理——盘点那些常用的函数(下)

你点的每个“在看”,是对我最大的鼓励
标签:info 干货 收盘价 nes 分析 常见 字符 频率 类型
原文地址:https://blog.51cto.com/14915204/2525822