标签:基金 table toc 怎么 dict 正则表达 taf 爬虫 日期
天秀!Pandas还能用来写爬虫?点击上方“Python读财”,选择“星标”公众号
重磅干货,第一时间送达
谈及Pandas的read.xxx系列的函数,大家的第一反应会想到比较常用的pd.read_csv()和pd.read_excel(),大多数人估计没用过pd.read_html()这个函数。
虽然它低调,但功能非常强大,用于抓取Table表格型数据时,简直是个神器。下面来详细介绍一下。
大家逛网页时,经常会看到这样一些数据表格,比如:
电影票房数据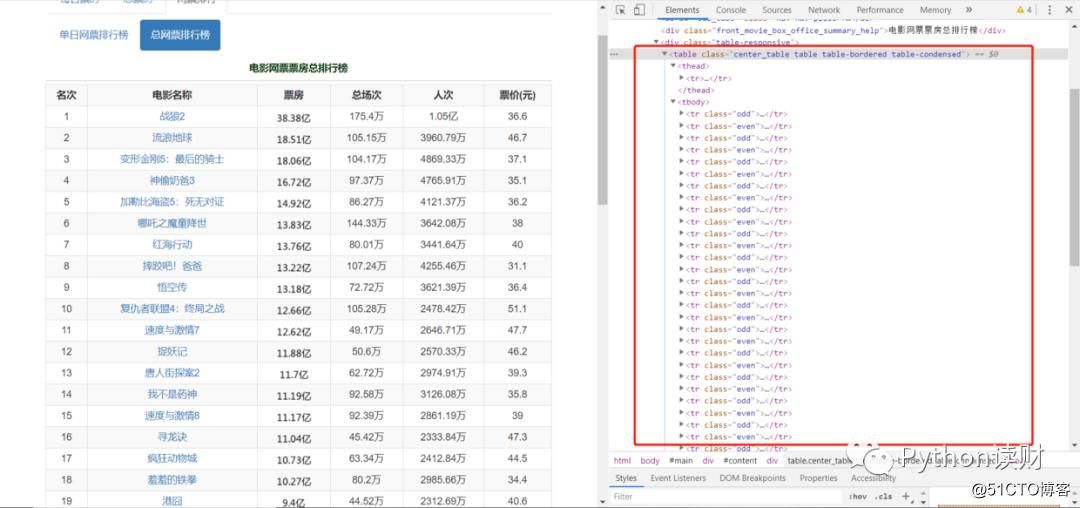
世界大学排行榜数据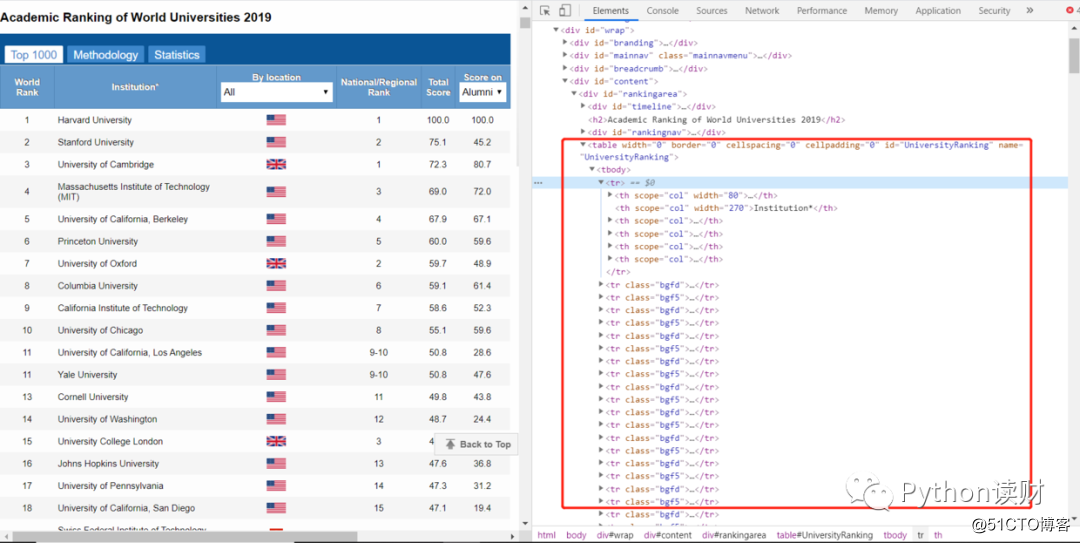
财经数据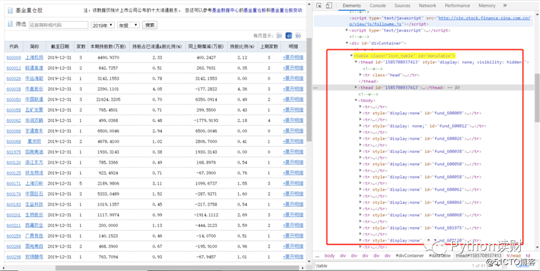
如果查看一下网页的HTML结构(Chrome浏览器F12),会发现它们有个共同的特点,不仅是表格,还是以Table结构展示的表格数据,大致的网页结构如下
<table class="..." id="...">
<thead>
<tr>
<th>...</th>
</tr>
</thead>
<tbody>
<tr>
<td>...</td>
</tr>
<tr>...</tr>
<tr>...</tr>
...
<tr>...</tr>
<tr>...</tr>
</tbody>
</table针对网页结构类似的表格类型数据,pd.read_html()就派上了大用场了,它可以将网页上的表格都抓取下来,并以DataFrame的形式装在一个列表中返回。具体是这么个流程: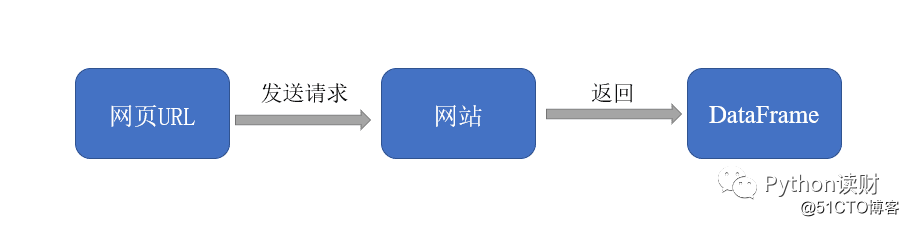
先介绍一下read_html的一些主要的参数
read_html
import pandas as pd
df = pd.DataFrame()
for i in range(6):
url = ‘http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jjzc/index.phtml?p={page}‘.format(page=i+1)
df = pd.concat([df,pd.read_html(url)[0]])
print("第{page}页完成~".format(page=i+1))
df.to_csv(‘./data.csv‘, encoding=‘utf-8‘, index=0)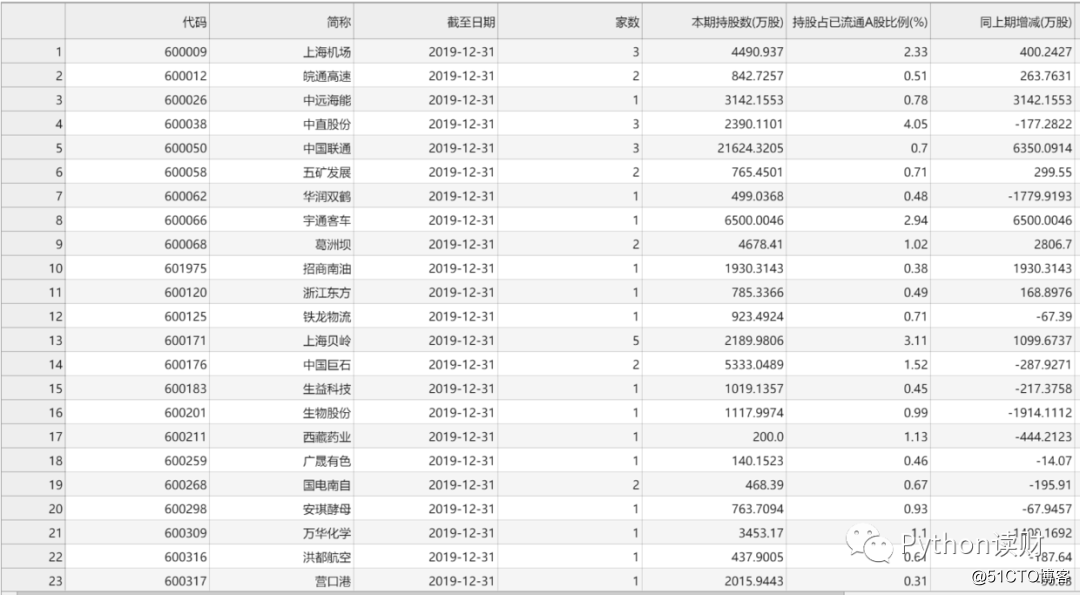
整个过程不需要用到正则表达式或者xpath等工具,短短的几行代码就可以将数据嗖嗖地爬下来了,是不是超级无敌方便?赶紧动手操作一波吧!
日后在爬一些小型数据时,只要遇到这种Table类型的表格,就可以直接祭出read_html这个神器啦,别人还在琢磨正则、xpath怎么写的时候,你已经把数据爬完了,想想就很舒服!
往期精彩回顾
Pandas数据处理——玩转时间序列数据
Pandas数据处理——盘点那些常用的函数(上)
Pandas数据处理——盘点那些常用的函数(下)
Pandas数据处理——一文详解数据拼接方法merge
Pandas数据分析——超好用的Groupby详解
标签:基金 table toc 怎么 dict 正则表达 taf 爬虫 日期
原文地址:https://blog.51cto.com/14915204/2525810