标签:展现 数据分析 monthly 思路 参考 pytho eset mic die
提高数据的颜值!一起看看Pandas中的那些Style点击上方“Python读财”,选择“星标”公众号
重磅干货,第一时间送达
Pandas的style用法在大多数教程中见的比较少,它主要是用来美化DataFrame和Series的输出,能够更加直观地显示数据结果。
下面采用某商店的零售数据集,通过实际的应用场景,来介绍一下style中那些实用的方法。
首先导入相应的包和数据集
import pandas as pd
import numpy as np
data = data = pd.read_excel(‘./data/sales.xlsx‘)
data.head()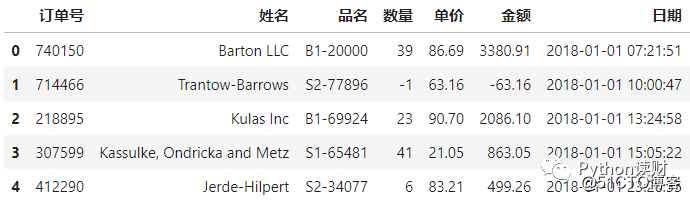
数据集中的特征有订单号、顾客姓名、商品名、数量、单价、金额以及对应的购买日期。
style中的format函数可以对输出进行格式化,比如在上述的数据集中,求每位顾客的消费平均金额和总金额,要求保留两位小数并显示相应的币种。
(data.groupby([‘姓名‘])[‘金额‘].agg([‘mean‘,‘sum‘])
.head(5)
.style
.format(‘${0:,.2f}‘))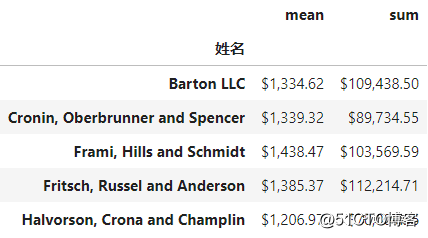
又或求每位顾客的总消费金额(保留2位小数)及其对应的占比情况(以百分数形式展现)
consumer_sales = data.groupby(‘姓名‘)[‘金额‘].agg([‘sum‘]).reset_index()
consumer_sales[‘消费金额占比‘] = consumer_sales[‘sum‘] / consumer_sales[‘sum‘].sum()
(consumer_sales.head(5)
.style
.format({‘sum‘:‘${0:,.0f}‘, ‘消费金额占比‘: ‘{:.2%}‘}))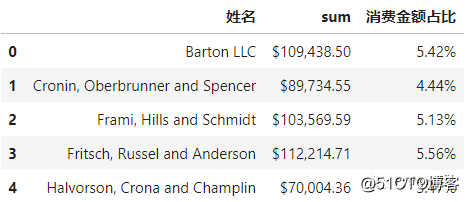
style还可以突出显示数据中的特殊值,比如高亮显示数据中的最大(highlight_max)、最小值(highlight_min)。
#求每个月的销售总金额,并分别用红色、绿色高亮显示最大值和最小值
monthly_sales = data.resample(‘M‘,on=‘日期‘)[‘金额‘].agg([‘sum‘]).reset_index()
monthly_sales[‘pct_of_total‘] = monthly_sales[‘sum‘] / data[‘金额‘].sum()
format_dict = {‘sum‘:‘${0:,.0f}‘, ‘日期‘: ‘{:%Y-%m}‘, ‘pct_of_total‘: ‘{:.2%}‘}
(monthly_sales.style
.format(format_dict)
.highlight_max(color=‘#cd4f39‘)
.highlight_min(color=‘lightgreen‘))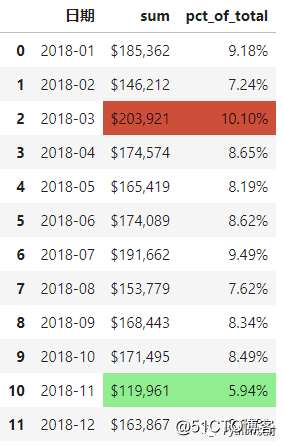
运用style的background_gradient方法,还可以实现类似于Excel的条件格式中的显示色阶样式,用颜色深浅来直观表示数据大小。
import seaborn as sns
cm = sns.light_palette("green", as_cmap=True)
(data.groupby([‘姓名‘])[[‘数量‘,‘金额‘]]
.agg([‘sum‘])
.head(5)
.style
.background_gradient(cmap=cm))
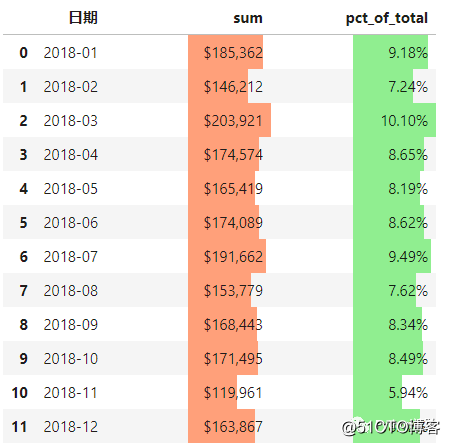
同样的,对于Excel的条件格式中的数据条样式,可以用style中的bar达到类似效果,通过颜色条的长短可以直观显示数值的大小。
(monthly_sales.style
.format(format_dict)
.bar(color=‘#FFA07A‘, vmin=100_000, subset=[‘sum‘], align=‘zero‘)
.bar(color=‘lightgreen‘, vmin=0, subset=[‘pct_of_total‘], align=‘zero‘)
)
最后介绍一个简单好用的骚操作——sparklines的运用,它能够以字符串的形式展现一个迷你的数据特征图。
假设我现在有一个这样的需求,就是想看看所有用户的购买数量和金额的大体分布情况。
按照往常的思路,可以用可视化的形式绘制出来,但是这样稍显复杂,使用sparklines则可以简单达到这种效果。
首先需要安装sparklines这个包
pip install sparklines因为需求的实现
需要用的groupby函数,所以先定义一个处理函数
from sparklines import sparklines
# 定义sparklines函数用于展现数据分布
def sparkline_str(x):
bins = np.histogram(x)[0]
sl = ‘‘.join(sparklines(bins))
return sl
# 定义groupby之后的列名
sparkline_str.__name__ = "分布图"
data.groupby(‘姓名‘)[[‘数量‘, ‘金额‘]].agg([‘mean‘, sparkline_str])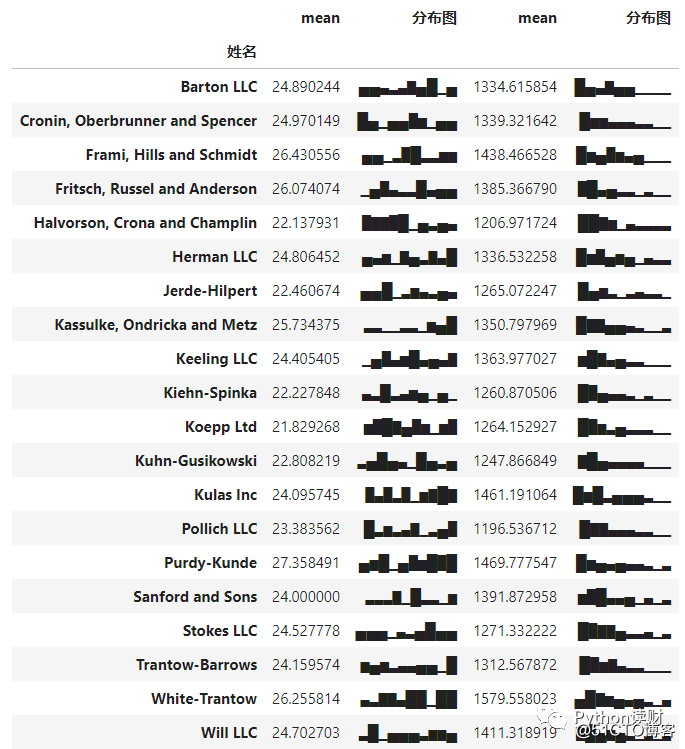
这样一来,就比较清晰直观地展现了每个用户的消费数量分布和消费金额分布,进而可以根据这些特征对用户的消费行为进行进一步的研究。
sparklines的功能还是挺Cool挺实用的,更具体的用法可以去看看sparklines的文档。
参考资料:https://pbpython.com/styling-pandas.html
往期精彩回顾
Pandas数据处理——玩转时间序列数据
天秀!Pandas还能用来写爬虫?
Pandas数据处理——一文详解数据拼接方法merge
Pandas数据分析——超好用的Groupby详解
标签:展现 数据分析 monthly 思路 参考 pytho eset mic die
原文地址:https://blog.51cto.com/14915204/2525809