标签:服务 open 下载视频 播放 get 学习 rename std 几分钟
宝藏B站UP主,视频弹幕尽收囊中!来自专辑
网络爬虫教程
点击上方“Jack Cui”,选择“加为星标”
第一时间关注技术干货!
1

众所周知,B 站是一个学习网站。
「里面的人,个个都是人才,说话又好听,超喜欢那里的。」
B 站里有很多宝藏 UP 主,视频质量非常高。
想要下载 B 站视频,保存到硬盘里慢慢「学习」,那本文的 B 站视频下载教程可以帮到你。
没有弹幕的 B 站视频是没有灵魂的,弹幕当然也不能少。
B 站视频 + 弹幕下载,Let`s go!
爬 B 站视频和弹幕,会有新的挑战,本文会讲解一些你可能不知道的新思路。
2
「刑部尚书」手工耿,以他奇思妙想的「刑具」而著称。
自制夫妻分分合合床,自制倒立洗头机,自制不锈钢 AK47 键盘,这都什么「妖魔鬼怪」。
 !
!
今天就以他为例,下载他的所有视频和弹幕。
保存到硬盘,以备后续「深入学习」。
会了本文的方法,找一些收藏家 UP 主下载些小视频也就都不成问题了。
3
首先看下手工耿的个人空间。
地址:
https://space.bilibili.com/280793434

点击更多,打开他的全部视频。
查看请求,不难发现,视频链接是通过一个接口获得的。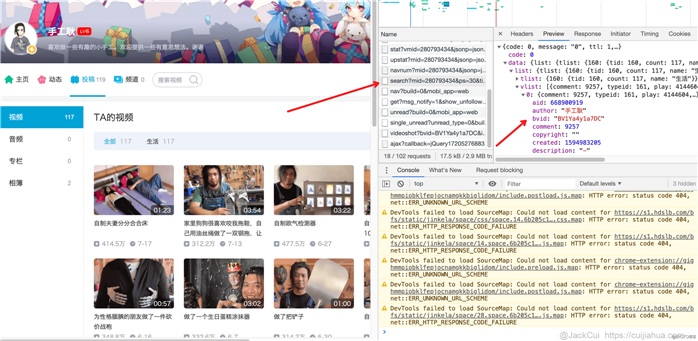
这个 API 接口是这样的:
https://api.bilibili.com/x/space/arc/search?mid=280793434&ps=30&tid=0&pn=1&keyword=&order=pubdate&jsonp=jsonp后面都 keyword 参数都是无用,我们直接看前面。
https://api.bilibili.com/x/space/arc/search?mid=280793434&ps=30&tid=0&pn=1mid 就是用户的一种 id,可以通过用户首页获取这个 mid。
https://space.bilibili.com/280793434ps 是当前也加载视频的格式。
tid 一直为 0 即可。
pn 是翻页。
知道这些,就可以直接写代码,获取所有视频的链接了。
# -*-coding:utf-8 -*-
# Website: https://cuijiahua.com
# Author: Jack Cui
# Date: 2020.07.22
import requests
import json
import math
space_url = ‘https://space.bilibili.com/280793434‘
search_url = ‘https://api.bilibili.com/x/space/arc/search‘
mid = space_url.split(‘/‘)[-1]
sess = requests.Session()
search_headers = {‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36‘,
‘Accept-Language‘: ‘zh-CN,zh;q=0.9‘,
‘Accept-Encoding‘: ‘gzip, deflate, br‘,
‘Accept‘: ‘application/json, text/plain, */*‘}
# 获取视频个数
ps = 1
pn = 1
search_params = {‘mid‘: mid,
‘ps‘: ps,
‘tid‘: 0,
‘pn‘: pn}
req = sess.get(url=search_url, headers=search_headers, params=search_params, verify=False)
info = json.loads(req.text)
video_count = info[‘data‘][‘page‘][‘count‘]
ps = 10
page = math.ceil(video_count/ps)
videos_list = []
for pn in range(1, page+1):
search_params = {‘mid‘: mid,
‘ps‘: ps,
‘tid‘: 0,
‘pn‘: pn}
req = sess.get(url=search_url, headers=search_headers, params=search_params, verify=False)
info = json.loads(req.text)
vlist = info[‘data‘][‘list‘][‘vlist‘]
for video in vlist:
title = video[‘title‘]
bvid = video[‘bvid‘]
vurl = ‘https://www.bilibili.com/video/‘ + bvid
videos_list.append([title, vurl])
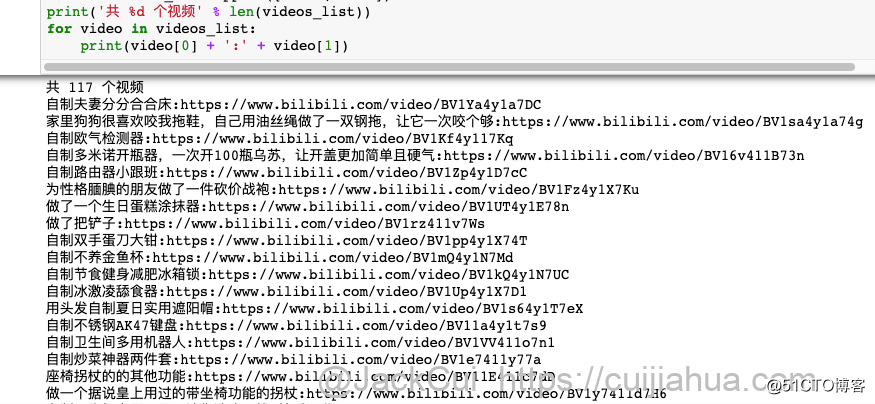
print(‘共 %d 个视频‘ % len(videos_list))
for video in videos_list:
print(video[0] + ‘:‘ + video[1])运行结果:
4
有了链接,接下来就可以下载视频了。
使用 you-get 这类工具下载 B 站视频,时常会抽风下载失败,很不稳定,有的视频链接还无法解析,问题很多。
自己解析视频的成本又高,因为网站可能会时常更新,那就得总改代码。
这回,咱换一个方法,使用别人搭建好的 B 站视频解析服务,抓包分析提供解析服务的网站,将视频解析的任务交给它们处理。
经过我精挑细选,找到了一个既稳定又快速的 B 站视频解析服务网站。
咱们直接拿解析好的视频地址下载即可。
# -*-coding:utf-8 -*-
# Website: https://cuijiahua.com
# Author: Jack Cui
# Date: 2020.07.22
import requests
import json
import re
from bs4 import BeautifulSoup
def get_download_url(arcurl):
# 微信搜索 JackCui-AI 关注公众号,后台回复「B 站」获取视频解析地址
jiexi_url = ‘xxx‘
payload = {‘url‘: arcurl}
jiexi_req = requests.get(jiexi_url, params=payload)
jiexi_bf = BeautifulSoup(jiexi_req.text)
jiexi_dn_url = jiexi_bf.iframe.get(‘src‘)
dn_req = requests.get(jiexi_dn_url)
dn_bf = BeautifulSoup(dn_req.text)
video_script = dn_bf.find(‘script‘,src = None)
DPlayer = str(video_script.string)
download_url = re.findall(‘\‘(http[s]?:(?:[a-zA-Z]|[0-9]|[$-_@.&~+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+)\‘‘, DPlayer)[0]
download_url = download_url.replace(‘\\‘, ‘‘)
return download_url
download_url = get_download_url(‘https://www.bilibili.com/video/BV1Ya4y1a7DC‘)
print(download_url)jiexi_url 地址进行了隐藏,想要使用这个解析服务的地址,关注我的微信公众号,后台回复「B 站」获取。
这是为了防止这个 B 站视频解析服务网站被滥用,我对其进行了一些限制。
这种 API 的一种特点就是,知道的人越多,它失效的也就越快。
希望这样,它可以活得久一点。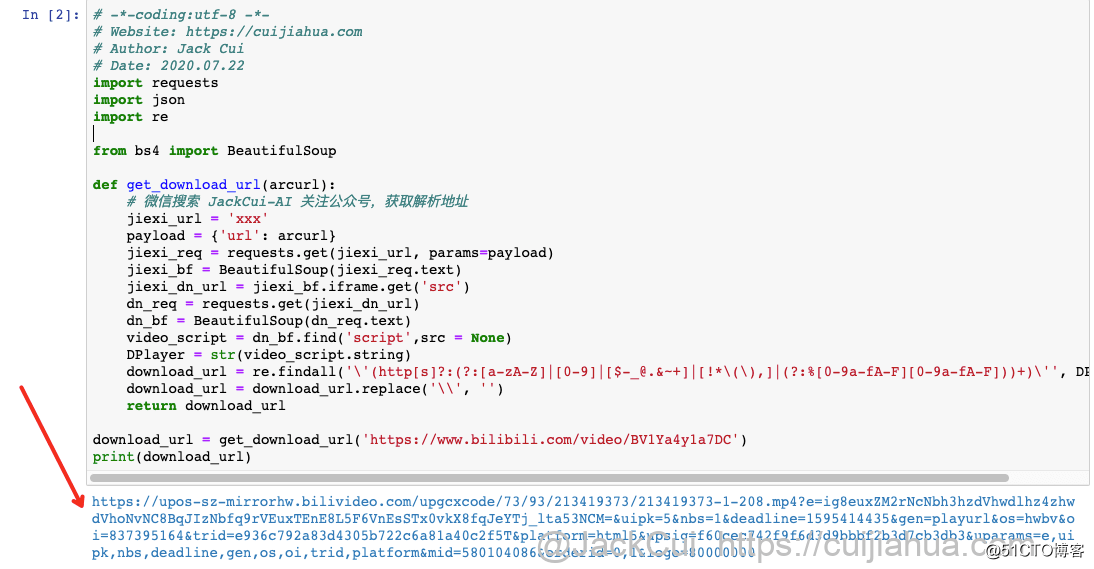
可以看到,视频顺利解析。
这个视频解析网站,抓包分析也很简单,就是通过 GET 请求,设置 url 参数,然后进行解析。
解析的 url 通过正则表达式匹配。
视频下载地址获取到了,那怎么下载视频的弹幕呢?
打开视频页面,抓包分析。
URL:
https://www.bilibili.com/video/BV1Ya4y1a7DC
这个是 PC 端的链接,打开这个视频,你可能花费九牛二虎之力,也找不到弹幕是怎么加载的。
B 站是怎么实现的,我们不清楚。
但是我们可以换个思路去尝试摸索,没准有意外收获。
记住,这也是一种常规的爬虫分析思路。
我们将 URL 修改为移动端的链接:
URL:
https://m.bilibili.com/video/BV1Ya4y1a7DC
可以看到,链接中的 www 改为了 m。
一个网站,有「 PC端」页面,也可能还有「 移动端」页面。
而「 移动端」页面,往往会因为一些原因,忘记或者为了适配,而没有「 PC端」健壮。
这就有机可乘。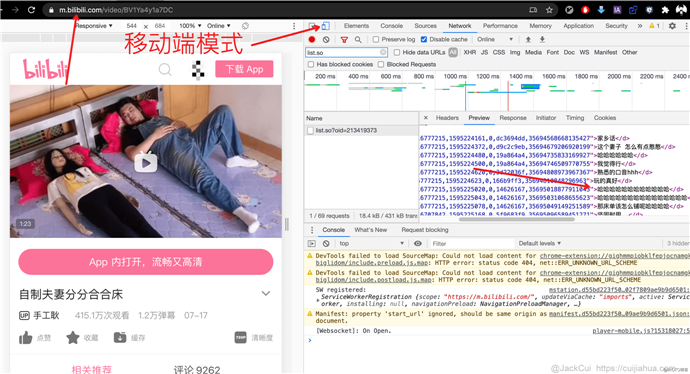
使用 Chrome 浏览器,可以直接开启移动端模式。这回再刷新页面,我们就能轻松找到视频弹幕的加载地址了。
甚至,「 移动端」页面还会返回视频的真实地址。
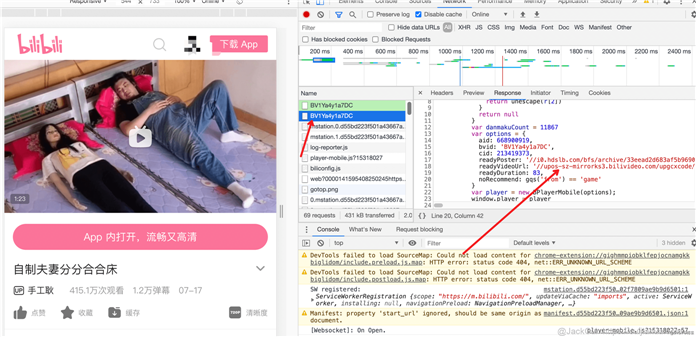
瞧,视频的下载地址就这么轻易的拿到了。
不过,为啥本文没用这种方法呢?
因为这个是移动端的视频,视频清晰度是有限的。
如果对视频清晰度要求不高,倒是可以用这种方法下载视频。
我们再看这个视频弹幕怎么下载。
视频弹幕接口:
https://api.bilibili.com/x/v1/dm/list.so?oid=213419373可以看到,只有一个参数 oid。
oid 可以通过,解析后的视频下载地址获得。
# -*-coding:utf-8 -*-
# Website: https://cuijiahua.com
# Author: Jack Cui
# Date: 2020.07.22
import requests
import xml2ass
import time
from contextlib import closing
filename = ‘自制夫妻分分合合床‘
danmu_name = filename + ‘.xml‘
danmu_ass = filename + ‘.ass‘
download_url = ‘https://upos-sz-mirrorhw.bilivideo.com/upgcxcode/73/93/213419373/213419373-1-208.mp4?e=ig8euxZM2rNcNbh3hzdVhwdlhz4zhwdVhoNvNC8BqJIzNbfq9rVEuxTEnE8L5F6VnEsSTx0vkX8fqJeYTj_lta53NCM=&uipk=5&nbs=1&deadline=1595414435&gen=playurl&os=hwbv&oi=837395164&trid=e936c792a83d4305b722c6a81a40c2f5T&platform=html5&upsig=f60cec742f9f6d3d9bbbf2b3d7cb3db3&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,platform&mid=580104086&orderid=0,1&logo=80000000‘
oid = download_url.split(‘/‘)[6]
danmu_url = ‘https://api.bilibili.com/x/v1/dm/list.so?oid={}‘.format(oid)
print(danmu_url)
sess = requests.Session()
danmu_header = {‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36‘,
‘Accept‘: ‘*/*‘,
‘Accept-Encoding‘: ‘gzip, deflate, br‘,
‘Accept-Language‘: ‘zh-CN,zh;q=0.9‘}
with closing(sess.get(danmu_url, headers=danmu_header, stream=True, verify=False)) as response:
if response.status_code == 200:
with open(danmu_name, ‘wb‘) as file:
for data in response.iter_content():
file.write(data)
file.flush()
else:
print(‘链接异常‘)
time.sleep(0.5)
xml2ass.Danmaku2ASS(danmu_name, danmu_ass, 1280, 720)这里用到了一个 xml2ass ,这个是一个 xml转 ass 封装好的函数,直接用即可,其实就是变了一下文本格式。
xml2ass.py 文件地址:
https://github.com/Jack-Cherish/python-spider/blob/master/2020/bilibili/xml2ass.py
运行结果:
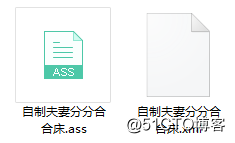
生成一个 ass 文件和 xml 文件。
ass 弹幕文件就是本地视频播放可以用的弹幕文件。
5
对于视频下载,除了曾经写过的 requests、urlretrieve 方法,其实可以外接迅雷。
这么做的好处是,下载更稳定,可以批量提交给迅雷任务,下载速度也更快。
总而言之,更快更强。
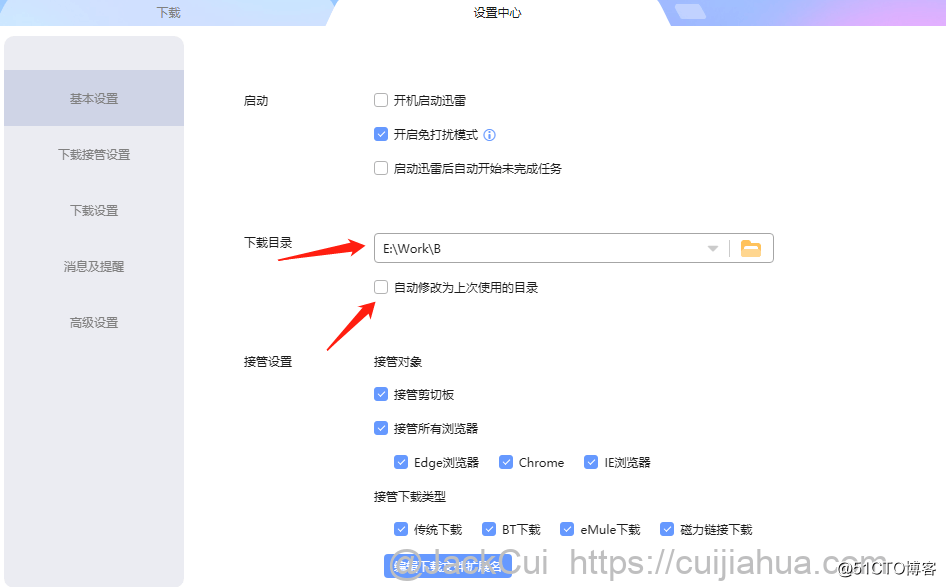
程序调用迅雷下载,需要将迅雷设置为一键下载。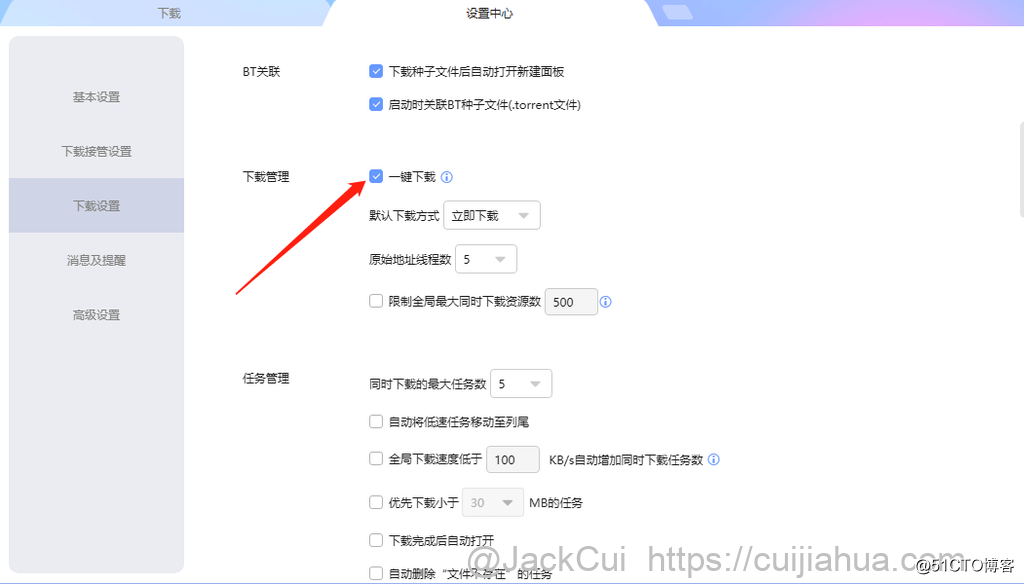
此外,再将迅雷下载目录改为,我们的工程目录,并将「自动修改为上次使用的目录」去掉。
运行如下代码:
import os
import time
from win32com.client import Dispatch
def addTasktoXunlei(down_url):
flag = False
o = Dispatch(‘ThunderAgent.Agent64.1‘)
try:
o.AddTask(down_url, "", "", "", "", -1, 0, 5)
o.CommitTasks()
flag = True
except Exception:
print(Exception.message)
print(" AddTask is fail!")
return flag
addTasktoXunlei(‘ftp://b:b@dx.dl1234.com:8206/[电影天堂www.dy2018.com]战狼BD国语中字.rmvb‘)如果配置没错的话,那么程序会自动调用迅雷,下载视频。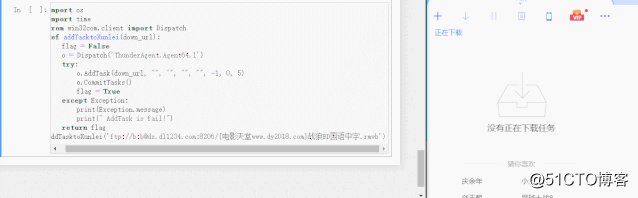
可以看到,运行左边程序,可以给迅雷添加下载任务。
6
现在将所有功能模块整合到一起,开始下载手工耿的所有视频吧!
# -*-coding:utf-8 -*-
# Website: https://cuijiahua.com
# Author: Jack Cui
# Date: 2020.07.22
import requests
import json
import re
import json
import math
import xml2ass
import time
from contextlib import closing
from bs4 import BeautifulSoup
import os
from win32com.client import Dispatch
def addTasktoXunlei(down_url):
flag = False
o = Dispatch(‘ThunderAgent.Agent64.1‘)
try:
o.AddTask(down_url, "", "", "", "", -1, 0, 5)
o.CommitTasks()
flag = True
except Exception:
print(Exception.message)
print(" AddTask is fail!")
return flag
def get_download_url(arcurl):
# 微信搜索 JackCui-AI 关注公众号,后台回复「B 站」获取视频解析地址
jiexi_url = ‘xxx‘
payload = {‘url‘: arcurl}
jiexi_req = requests.get(jiexi_url, params=payload)
jiexi_bf = BeautifulSoup(jiexi_req.text)
jiexi_dn_url = jiexi_bf.iframe.get(‘src‘)
dn_req = requests.get(jiexi_dn_url)
dn_bf = BeautifulSoup(dn_req.text)
video_script = dn_bf.find(‘script‘,src = None)
DPlayer = str(video_script.string)
download_url = re.findall(‘\‘(http[s]?:(?:[a-zA-Z]|[0-9]|[$-_@.&~+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+)\‘‘, DPlayer)[0]
download_url = download_url.replace(‘\\‘, ‘‘)
return download_url
space_url = ‘https://space.bilibili.com/280793434‘
search_url = ‘https://api.bilibili.com/x/space/arc/search‘
mid = space_url.split(‘/‘)[-1]
sess = requests.Session()
search_headers = {‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36‘,
‘Accept-Language‘: ‘zh-CN,zh;q=0.9‘,
‘Accept-Encoding‘: ‘gzip, deflate, br‘,
‘Accept‘: ‘application/json, text/plain, */*‘}
# 获取视频个数
ps = 1
pn = 1
search_params = {‘mid‘: mid,
‘ps‘: ps,
‘tid‘: 0,
‘pn‘: pn}
req = sess.get(url=search_url, headers=search_headers, params=search_params, verify=False)
info = json.loads(req.text)
video_count = info[‘data‘][‘page‘][‘count‘]
ps = 10
page = math.ceil(video_count/ps)
videos_list = []
for pn in range(1, page+1):
search_params = {‘mid‘: mid,
‘ps‘: ps,
‘tid‘: 0,
‘pn‘: pn}
req = sess.get(url=search_url, headers=search_headers, params=search_params, verify=False)
info = json.loads(req.text)
vlist = info[‘data‘][‘list‘][‘vlist‘]
for video in vlist:
title = video[‘title‘]
bvid = video[‘bvid‘]
vurl = ‘https://www.bilibili.com/video/‘ + bvid
videos_list.append([title, vurl])
print(‘共 %d 个视频‘ % len(videos_list))
all_video = {}
# 下载前 10 个视频
for video in videos_list[:10]:
download_url = get_download_url(video[1])
print(video[0] + ‘:‘ + download_url)
# 记录视频名字
xunlei_video_name = download_url.split(‘?‘)[0].split(‘/‘)[-1]
filename = video[0]
for c in u‘′☆?\/:*?"<>| ‘:
filename = filename.replace(c, ‘‘)
save_video_name = filename + ‘.mp4‘
all_video[xunlei_video_name] = save_video_name
addTasktoXunlei(download_url)
# 弹幕下载
danmu_name = filename + ‘.xml‘
danmu_ass = filename + ‘.ass‘
oid = download_url.split(‘/‘)[6]
danmu_url = ‘https://api.bilibili.com/x/v1/dm/list.so?oid={}‘.format(oid)
danmu_header = {‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36‘,
‘Accept‘: ‘*/*‘,
‘Accept-Encoding‘: ‘gzip, deflate, br‘,
‘Accept-Language‘: ‘zh-CN,zh;q=0.9‘}
with closing(sess.get(danmu_url, headers=danmu_header, stream=True, verify=False)) as response:
if response.status_code == 200:
with open(danmu_name, ‘wb‘) as file:
for data in response.iter_content():
file.write(data)
file.flush()
else:
print(‘链接异常‘)
time.sleep(0.5)
xml2ass.Danmaku2ASS(danmu_name, danmu_ass, 1280, 720)
# 视频重命名
for key, item in all_video.items():
while key not in os.listdir(‘./‘):
time.sleep(1)
os.rename(key, item)这里下载的是前 10 个视频,想下载全部视频,可以将 videos_list[:10] 改为 videos_list。
几分钟,就可以运行完毕,迅雷几兆/秒的下载速度可不是盖的。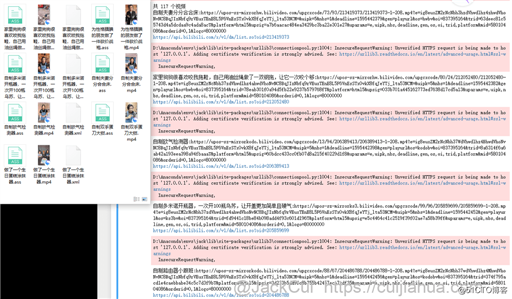 ![]
![]
使用 PotPlayer 这类支持弹幕的播放器打开视频,即可自动加载弹幕,播放视频。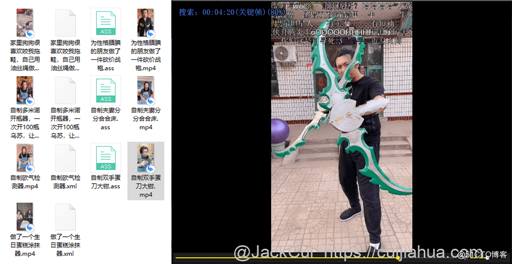
真香!
7
使用迅雷下载,速度飞起。用本文的方法,爬 B 站视频,就很舒服。
代码、教程仅限于学习交流,请勿用于任何商业用途!
文章已于2020-07-24修改
阅读原文
阅读 879
赞41
在看13
写下你的留言
精选留言
标签:服务 open 下载视频 播放 get 学习 rename std 几分钟
原文地址:https://blog.51cto.com/14915208/2526028