标签:make pre isp 直接 span oom 掌握 索引 百度
stu = {
"name":["张三","李四","王燕"],
"age":[18,20,22],
"sex":["男","男","女"]
}
df = pd.DataFrame(stu)
display(df)
结果如下:
person = {
"name":"Tom",
"age":20,
"subject":["Python","Java","Excel"]
}
df = pd.DataFrame(person)
display(df)
结果如下: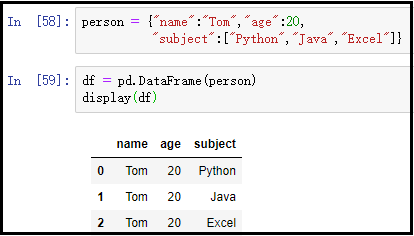
x = [[1,2,3,4],[5,6,7,8],[9,10,11,12]]
df = pd.DataFrame(data)
display(df)
结果如下: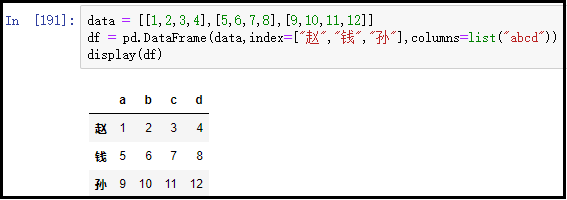
data = [
{"one":1,"two":2},
{"one":5,"two":10,"three":15}
]
df = pd.DataFrame(data)
display(df)
结果如下: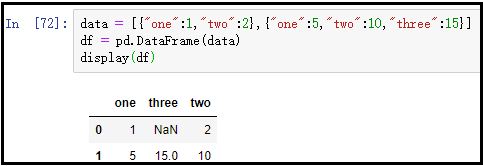
data = {
"张三":{"Java":90, "Python":89, "Hive":78},
"李四":{"Java":82, "Python":95, "Hive":96},
"王五":{"Java":85, "Python":94}
}
df = pd.DataFrame(data)
display(df)
data = {
"Java":{"张三":90,"李四":82,"王五":85},
"Python":{"张三":89,"李四":95,"王五":94},
"Hive":{"张三":78,"李四":96}
}
df = pd.DataFrame(data)
display(df)
结果如下: 注意:对于上述两个DataFrame,我们直接可以使用data.T进行DataFrame行、列之间的转换。
注意:对于上述两个DataFrame,我们直接可以使用data.T进行DataFrame行、列之间的转换。
data = {
"Java":pd.Series(np.random.randint(70,100,5)),
"Python":np.random.randint(80,100,5)
}
df = pd.DataFrame(data)
display(df)
结果如下: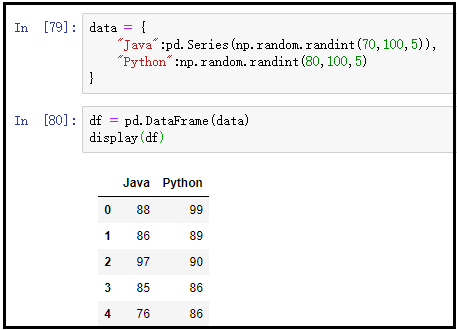
column = ["Python","Java","Excel"]
dates = pd.date_range("20200202",periods=5)
df = pd.DataFrame(np.random.randint(low=70,high=100,size=(5,3)),
index=dates,columns=column)
display(df)
结果如下: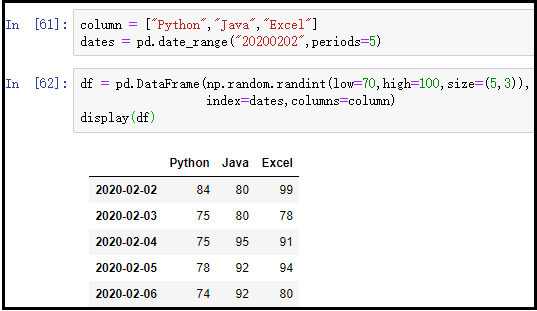 注意:这里有两个知识点需要掌握,一个是pd.date_range(),一个np.random.randint(),知道怎么用就行了,详细说明请自行百度。
注意:这里有两个知识点需要掌握,一个是pd.date_range(),一个np.random.randint(),知道怎么用就行了,详细说明请自行百度。
x = np.arange(1,21).reshape(4,5)
index = list("abcde")
df = pd.DataFrame(x,index=index)
display(df)
结果如下:
movie = ["战狼2","哪吒之魔童降世","流浪地球","红海行动"]
piapofang = [str(x)+"亿" for x in [56.39,49.34,46.18,36.22]]
list_to_tuple = list(zip(movie,piaofang))
df = pd.DataFrame(list_to_tuple,columns=["movies","piaofang"])
display(df)
结果如下: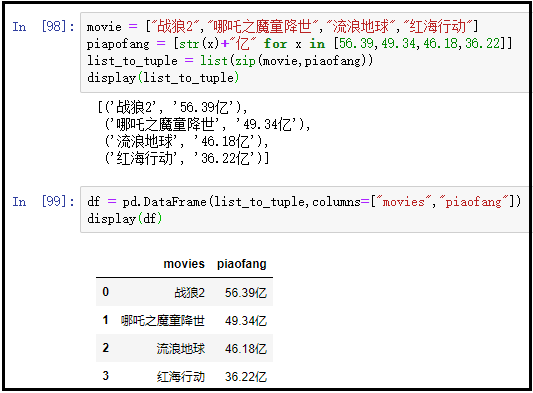
以后工作中都是利用已有的文件,进行数据分析。
最好的方式就是将文件读取成DataFrame方式,然后利用各种方式进行数据处理。
由于文件格式众多,这里不细说,你需要读取哪一种文件,就自行百度学习一下,即可。
标签:make pre isp 直接 span oom 掌握 索引 百度
原文地址:https://www.cnblogs.com/math98/p/13591327.html